 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Models
Feb 27, 2025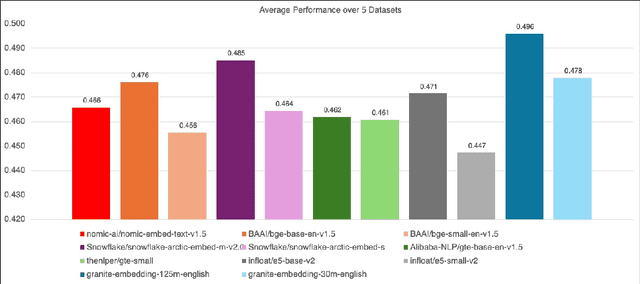



We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
Mistral-SPLADE: LLMs for better Learned Sparse Retrieval
Aug 22, 2024Learned Sparse Retrievers (LSR) have evolved into an effective retrieval strategy that can bridge the gap between traditional keyword-based sparse retrievers and embedding-based dense retrievers. At its core, learned sparse retrievers try to learn the most important semantic keyword expansions from a query and/or document which can facilitate better retrieval with overlapping keyword expansions. LSR like SPLADE has typically been using encoder only models with MLM (masked language modeling) style objective in conjunction with known ways of retrieval performance improvement such as hard negative mining, distillation, etc. In this work, we propose to use decoder-only model for learning semantic keyword expansion. We posit, decoder only models that have seen much higher magnitudes of data are better equipped to learn keyword expansions needed for improved retrieval. We use Mistral as the backbone to develop our Learned Sparse Retriever similar to SPLADE and train it on a subset of sentence-transformer data which is often used for training text embedding models. Our experiments support the hypothesis that a sparse retrieval model based on decoder only large language model (LLM) surpasses the performance of existing LSR systems, including SPLADE and all its variants. The LLM based model (Echo-Mistral-SPLADE) now stands as a state-of-the-art learned sparse retrieval model on the BEIR text retrieval benchmark.