 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMK > CLS: Landmark Pooling for Dense Embeddings
Jan 29, 2026Representation learning is central to many downstream tasks such as search, clustering, classification, and reranking. State-of-the-art sequence encoders typically collapse a variable-length token sequence to a single vector using a pooling operator, most commonly a special [CLS] token or mean pooling over token embeddings. In this paper, we identify systematic weaknesses of these pooling strategies: [CLS] tends to concentrate information toward the initial positions of the sequence and can under-represent distributed evidence, while mean pooling can dilute salient local signals, sometimes leading to worse short-context performance. To address these issues, we introduce Landmark (LMK) pooling, which partitions a sequence into chunks, inserts landmark tokens between chunks, and forms the final representation by mean-pooling the landmark token embeddings. This simple mechanism improves long-context extrapolation without sacrificing local salient features, at the cost of introducing a small number of special tokens. We empirically demonstrate that LMK pooling matches existing methods on short-context retrieval tasks and yields substantial improvements on long-context tasks, making it a practical and scalable alternative to existing pooling methods.
Influence Guided Sampling for Domain Adaptation of Text Retrievers
Jan 29, 2026General-purpose open-domain dense retrieval systems are usually trained with a large, eclectic mix of corpora and search tasks. How should these diverse corpora and tasks be sampled for training? Conventional approaches sample them uniformly, proportional to their instance population sizes, or depend on human-level expert supervision. It is well known that the training data sampling strategy can greatly impact model performance. However, how to find the optimal strategy has not been adequately studied in the context of embedding models. We propose Inf-DDS, a novel reinforcement learning driven sampling framework that adaptively reweighs training datasets guided by influence-based reward signals and is much more lightweight with respect to GPU consumption. Our technique iteratively refines the sampling policy, prioritizing datasets that maximize model performance on a target development set. We evaluate the efficacy of our sampling strategy on a wide range of text retrieval tasks, demonstrating strong improvements in retrieval performance and better adaptation compared to existing gradient-based sampling methods, while also being 1.5x to 4x cheaper in GPU compute. Our sampling strategy achieves a 5.03 absolute NDCG@10 improvement while training a multilingual bge-m3 model and an absolute NDCG@10 improvement of 0.94 while training all-MiniLM-L6-v2, even when starting from expert-assigned weights on a large pool of training datasets.
Mistral-SPLADE: LLMs for better Learned Sparse Retrieval
Aug 22, 2024



Learned Sparse Retrievers (LSR) have evolved into an effective retrieval strategy that can bridge the gap between traditional keyword-based sparse retrievers and embedding-based dense retrievers. At its core, learned sparse retrievers try to learn the most important semantic keyword expansions from a query and/or document which can facilitate better retrieval with overlapping keyword expansions. LSR like SPLADE has typically been using encoder only models with MLM (masked language modeling) style objective in conjunction with known ways of retrieval performance improvement such as hard negative mining, distillation, etc. In this work, we propose to use decoder-only model for learning semantic keyword expansion. We posit, decoder only models that have seen much higher magnitudes of data are better equipped to learn keyword expansions needed for improved retrieval. We use Mistral as the backbone to develop our Learned Sparse Retriever similar to SPLADE and train it on a subset of sentence-transformer data which is often used for training text embedding models. Our experiments support the hypothesis that a sparse retrieval model based on decoder only large language model (LLM) surpasses the performance of existing LSR systems, including SPLADE and all its variants. The LLM based model (Echo-Mistral-SPLADE) now stands as a state-of-the-art learned sparse retrieval model on the BEIR text retrieval benchmark.
How effective is Multi-source pivoting for Translation of Low Resource Indian Languages?
Jun 19, 2024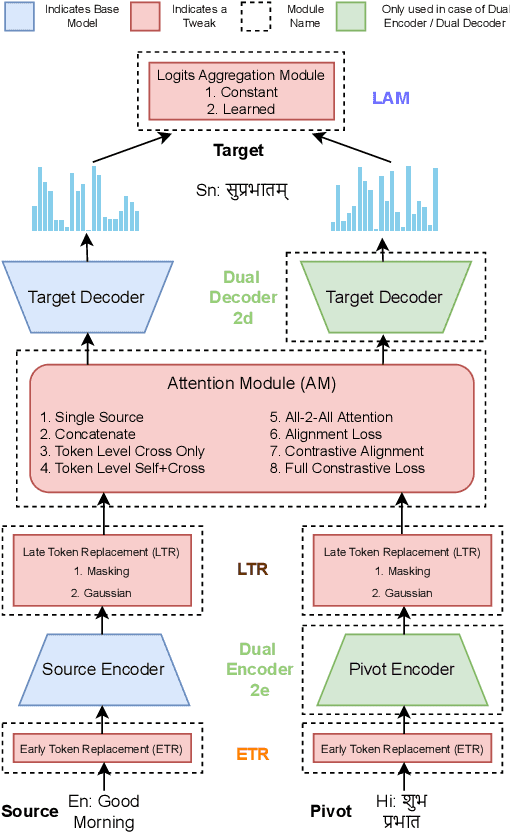



Machine Translation (MT) between linguistically dissimilar languages is challenging, especially due to the scarcity of parallel corpora. Prior works suggest that pivoting through a high-resource language can help translation into a related low-resource language. However, existing works tend to discard the source sentence when pivoting. Taking the case of English to Indian language MT, this paper explores the 'multi-source translation' approach with pivoting, using both source and pivot sentences to improve translation. We conducted extensive experiments with various multi-source techniques for translating English to Konkani, Manipuri, Sanskrit, and Bodo, using Hindi, Marathi, and Bengali as pivot languages. We find that multi-source pivoting yields marginal improvements over the state-of-the-art, contrary to previous claims, but these improvements can be enhanced with synthetic target language data. We believe multi-source pivoting is a promising direction for Low-resource translation.
Do Not Worry if You Do Not Have Data: Building Pretrained Language Models Using Translationese
Mar 21, 2024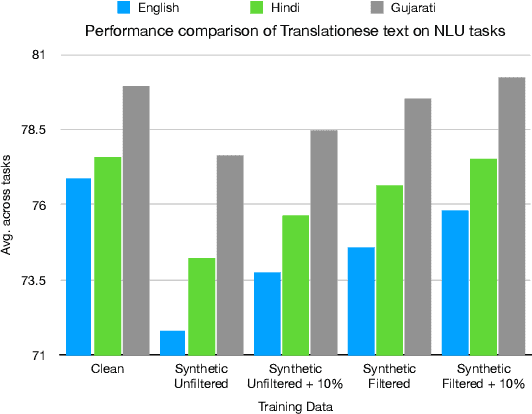
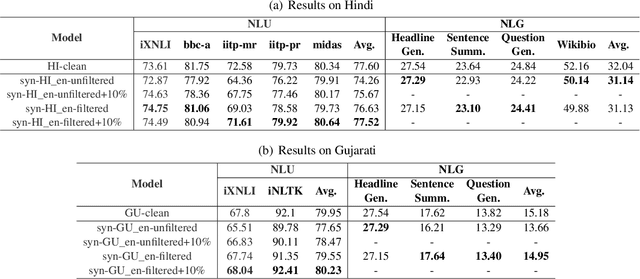
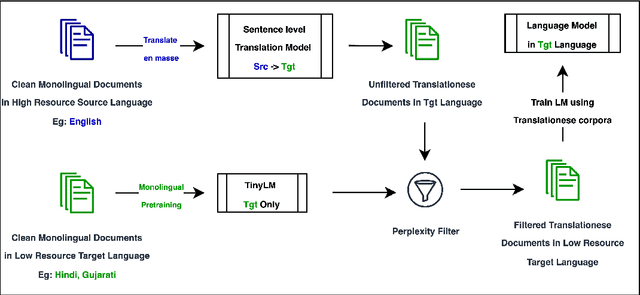
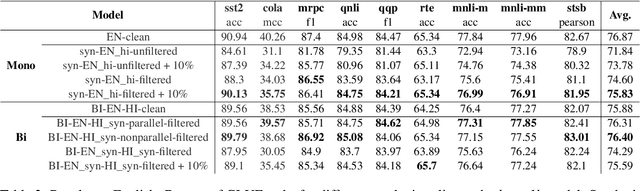
In this paper, we explore the utility of Translationese as synthetic data created using machine translation for pre-training language models (LMs). Pre-training requires vast amounts of monolingual data, which is mostly unavailable for languages other than English. Recently, there has been a growing interest in using synthetic data to address this data scarcity. We take the case of English and Indic languages and translate web-crawled monolingual documents (clean) into the target language. Then, we train language models containing 28M and 85M parameters on this translationese data (synthetic). We show that their performance on downstream natural language understanding and generative tasks is only 3.56% poorer on NLU tasks and 1.51% on NLG tasks than LMs pre-trained on clean data. Further, we propose the use of lightweight TinyLMs pre-trained on clean data to filter synthetic data efficiently which significantly improves the performance of our models. We also find that LMs trained on synthetic data strongly benefit from extended pretraining on a tiny fraction (10%) of clean data. We release the data we collected and created as a part of this work, IndicMonoDoc, the largest collection of monolingual document-level corpora, which we hope will help bridge the gap between English and non-English performance for large language models.
PUB: A Pragmatics Understanding Benchmark for Assessing LLMs' Pragmatics Capabilities
Jan 13, 2024LLMs have demonstrated remarkable capability for understanding semantics, but they often struggle with understanding pragmatics. To demonstrate this fact, we release a Pragmatics Understanding Benchmark (PUB) dataset consisting of fourteen tasks in four pragmatics phenomena, namely, Implicature, Presupposition, Reference, and Deixis. We curated high-quality test sets for each task, consisting of Multiple Choice Question Answers (MCQA). PUB includes a total of 28k data points, 6.1k of which have been created by us, and the rest are adapted from existing datasets. We evaluated nine models varying in the number of parameters and type of training. Our study indicates that fine-tuning for instruction-following and chat significantly enhances the pragmatics capabilities of smaller language models. However, for larger models, the base versions perform comparably with their chat-adapted counterparts. Additionally, there is a noticeable performance gap between human capabilities and model capabilities. Furthermore, unlike the consistent performance of humans across various tasks, the models demonstrate variability in their proficiency, with performance levels fluctuating due to different hints and the complexities of tasks within the same dataset. Overall, the benchmark aims to provide a comprehensive evaluation of LLM's ability to handle real-world language tasks that require pragmatic reasoning.