 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Not Worry if You Do Not Have Data: Building Pretrained Language Models Using Translationese
Paper and Code
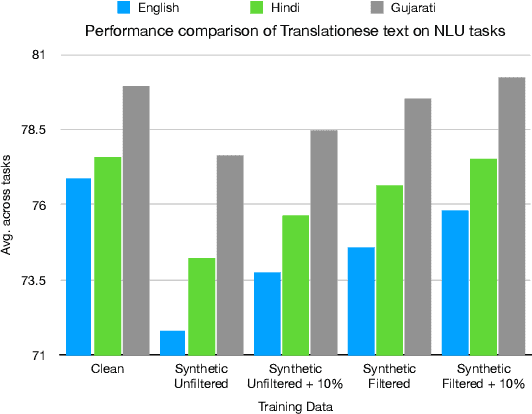
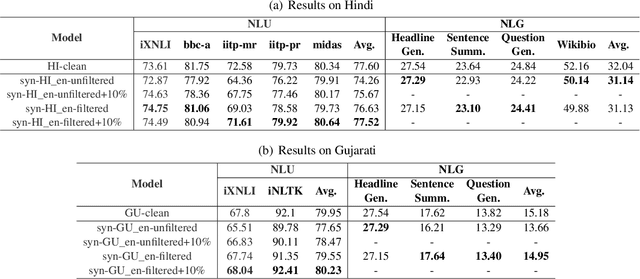
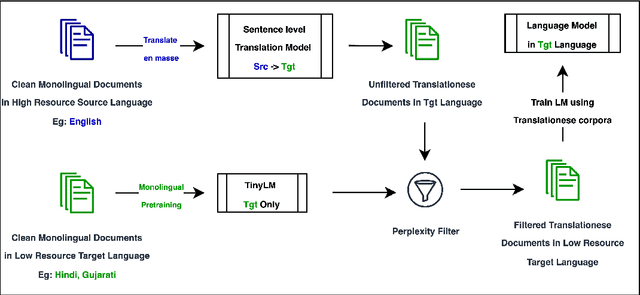
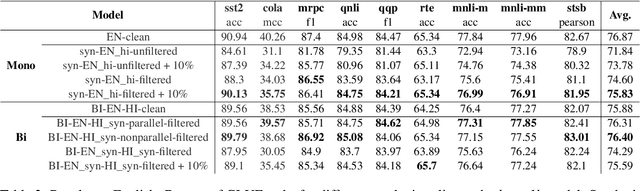
In this paper, we explore the utility of Translationese as synthetic data created using machine translation for pre-training language models (LMs). Pre-training requires vast amounts of monolingual data, which is mostly unavailable for languages other than English. Recently, there has been a growing interest in using synthetic data to address this data scarcity. We take the case of English and Indic languages and translate web-crawled monolingual documents (clean) into the target language. Then, we train language models containing 28M and 85M parameters on this translationese data (synthetic). We show that their performance on downstream natural language understanding and generative tasks is only 3.56% poorer on NLU tasks and 1.51% on NLG tasks than LMs pre-trained on clean data. Further, we propose the use of lightweight TinyLMs pre-trained on clean data to filter synthetic data efficiently which significantly improves the performance of our models. We also find that LMs trained on synthetic data strongly benefit from extended pretraining on a tiny fraction (10%) of clean data. We release the data we collected and created as a part of this work, IndicMonoDoc, the largest collection of monolingual document-level corpora, which we hope will help bridge the gap between English and non-English performance for large language models.