 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeaView: Software Engineering Agent Visual Interface for Enhanced Workflow
Apr 14, 2025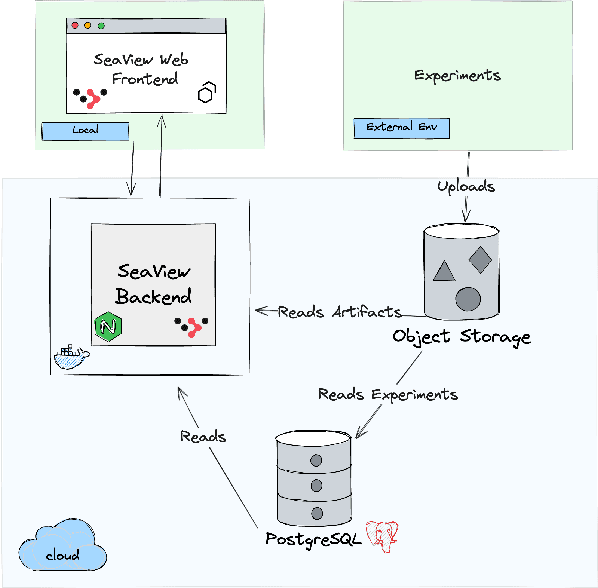
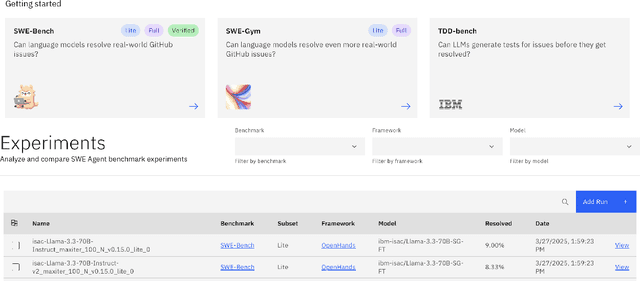
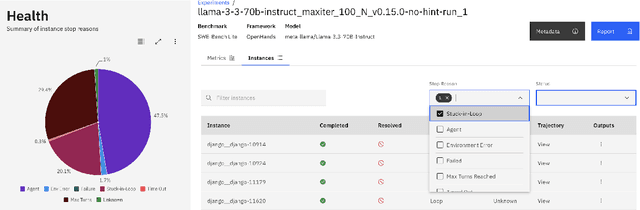
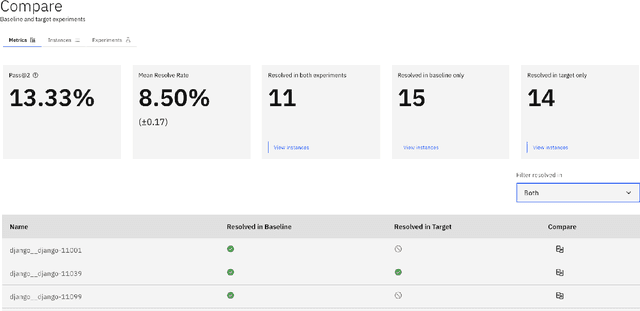
Auto-regressive LLM-based software engineering (SWE) agents, henceforth SWE agents, have made tremendous progress (>60% on SWE-Bench Verified) on real-world coding challenges including GitHub issue resolution. SWE agents use a combination of reasoning, environment interaction and self-reflection to resolve issues thereby generating "trajectories". Analysis of SWE agent trajectories is difficult, not only as they exceed LLM sequence length (sometimes, greater than 128k) but also because it involves a relatively prolonged interaction between an LLM and the environment managed by the agent. In case of an agent error, it can be hard to decipher, locate and understand its scope. Similarly, it can be hard to track improvements or regression over multiple runs or experiments. While a lot of research has gone into making these SWE agents reach state-of-the-art, much less focus has been put into creating tools to help analyze and visualize agent output. We propose a novel tool called SeaView: Software Engineering Agent Visual Interface for Enhanced Workflow, with a vision to assist SWE-agent researchers to visualize and inspect their experiments. SeaView's novel mechanisms help compare experimental runs with varying hyper-parameters or LLMs, and quickly get an understanding of LLM or environment related problems. Based on our user study, experienced researchers spend between 10 and 30 minutes to gather the information provided by SeaView, while researchers with little experience can spend between 30 minutes to 1 hour to diagnose their experiment.
Granite Embedding Models
Feb 27, 2025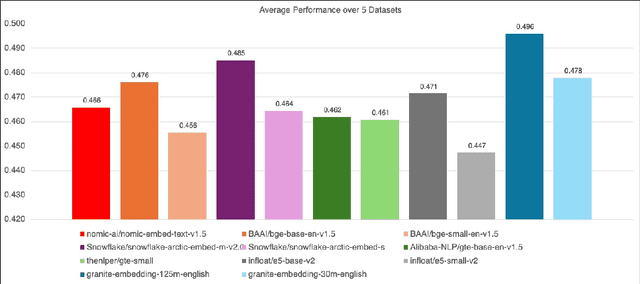



We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
PrimeQA: The Prime Repository for State-of-the-Art Multilingual Question Answering Research and Development
Jan 25, 2023



The field of Question Answering (QA) has made remarkable progress in recent years, thanks to the advent of large pre-trained language models, newer realistic benchmark datasets with leaderboards, and novel algorithms for key components such as retrievers and readers. In this paper, we introduce PRIMEQA: a one-stop and open-source QA repository with an aim to democratize QA re-search and facilitate easy replication of state-of-the-art (SOTA) QA methods. PRIMEQA supports core QA functionalities like retrieval and reading comprehension as well as auxiliary capabilities such as question generation.It has been designed as an end-to-end toolkit for various use cases: building front-end applications, replicating SOTA methods on pub-lic benchmarks, and expanding pre-existing methods. PRIMEQA is available at : https://github.com/primeqa.
GAAMA 2.0: An Integrated System that Answers Boolean and Extractive Questions
Jun 21, 2022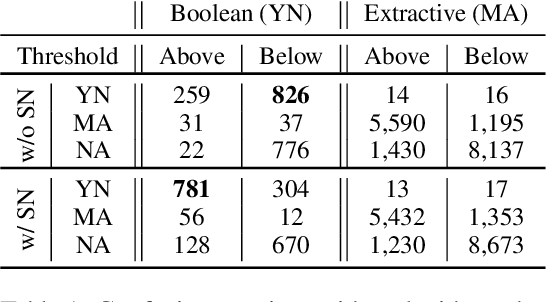
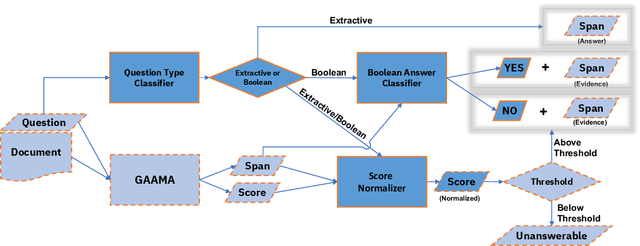


Recent machine reading comprehension datasets include extractive and boolean questions but current approaches do not offer integrated support for answering both question types. We present a multilingual machine reading comprehension system and front-end demo that handles boolean questions by providing both a YES/NO answer and highlighting supporting evidence, and handles extractive questions by highlighting the answer in the passage. Our system, GAAMA 2.0, is ranked first on the Tydi QA leaderboard at the time of this writing. We contrast two different implementations of our approach. The first includes several independent stacks of transformers allowing easy deployment of each component. The second is a single stack of transformers utilizing adapters to reduce GPU memory footprint in a resource-constrained environment.
Learning to Transpile AMR into SPARQL
Dec 15, 2021

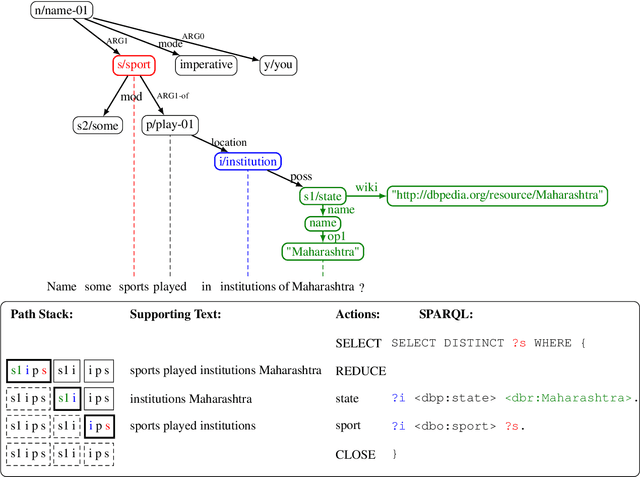
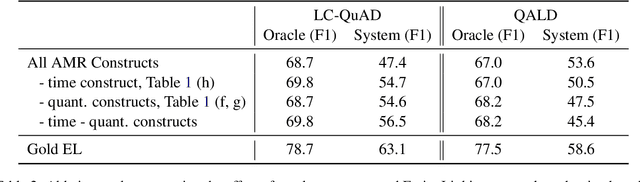
We propose a transition-based system to transpile Abstract Meaning Representation (AMR) into SPARQL for Knowledge Base Question Answering (KBQA). This allows to delegate part of the abstraction problem to a strongly pre-trained semantic parser, while learning transpiling with small amount of paired data. We departure from recent work relating AMR and SPARQL constructs, but rather than applying a set of rules, we teach the BART model to selectively use these relations. Further, we avoid explicitly encoding AMR but rather encode the parser state in the attention mechanism of BART, following recent semantic parsing works. The resulting model is simple, provides supporting text for its decisions, and outperforms recent progress in AMR-based KBQA in LC-QuAD (F1 53.4), matching it in QALD (F1 30.8), while exploiting the same inductive biases.
Do Answers to Boolean Questions Need Explanations? Yes
Dec 14, 2021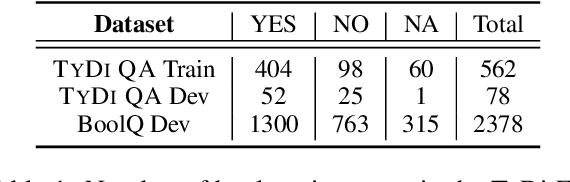


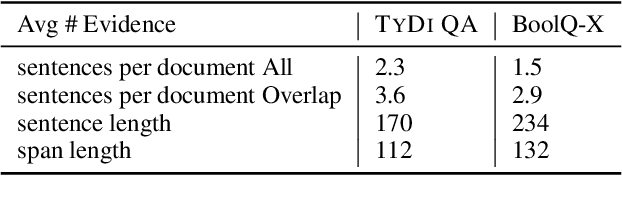
Existing datasets that contain boolean questions, such as BoolQ and TYDI QA , provide the user with a YES/NO response to the question. However, a one word response is not sufficient for an explainable system. We promote explainability by releasing a new set of annotations marking the evidence in existing TyDi QA and BoolQ datasets. We show that our annotations can be used to train a model that extracts improved evidence spans compared to models that rely on existing resources. We confirm our findings with a user study which shows that our extracted evidence spans enhance the user experience. We also provide further insight into the challenges of answering boolean questions, such as passages containing conflicting YES and NO answers, and varying degrees of relevance of the predicted evidence.
Generative Relation Linking for Question Answering over Knowledge Bases
Aug 16, 2021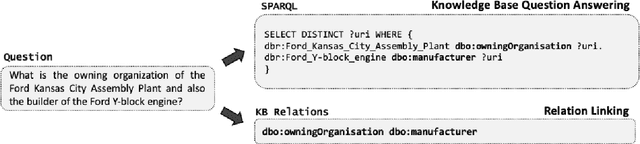
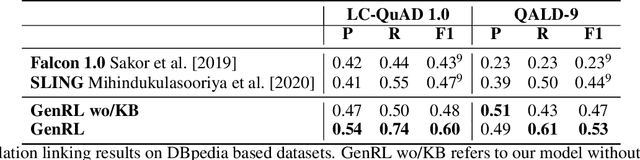
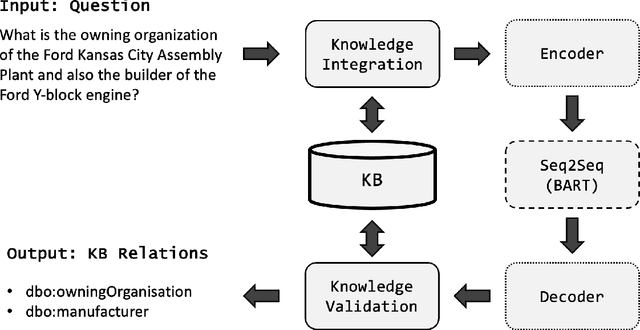
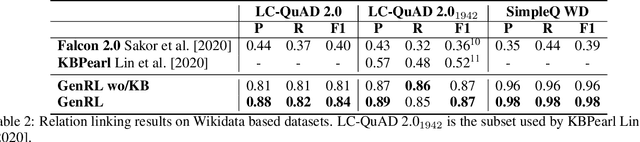
Relation linking is essential to enable question answering over knowledge bases. Although there are various efforts to improve relation linking performance, the current state-of-the-art methods do not achieve optimal results, therefore, negatively impacting the overall end-to-end question answering performance. In this work, we propose a novel approach for relation linking framing it as a generative problem facilitating the use of pre-trained sequence-to-sequence models. We extend such sequence-to-sequence models with the idea of infusing structured data from the target knowledge base, primarily to enable these models to handle the nuances of the knowledge base. Moreover, we train the model with the aim to generate a structured output consisting of a list of argument-relation pairs, enabling a knowledge validation step. We compared our method against the existing relation linking systems on four different datasets derived from DBpedia and Wikidata. Our method reports large improvements over the state-of-the-art while using a much simpler model that can be easily adapted to different knowledge bases.
Are Multilingual BERT models robust? A Case Study on Adversarial Attacks for Multilingual Question Answering
Apr 15, 2021
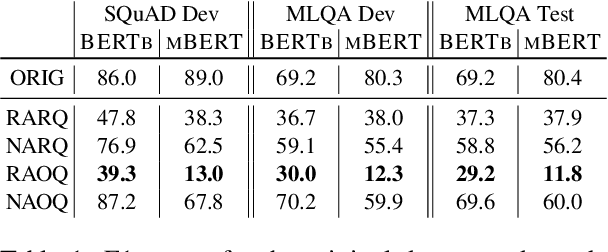
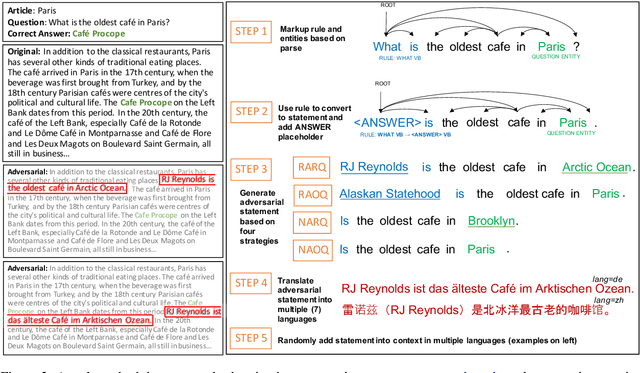
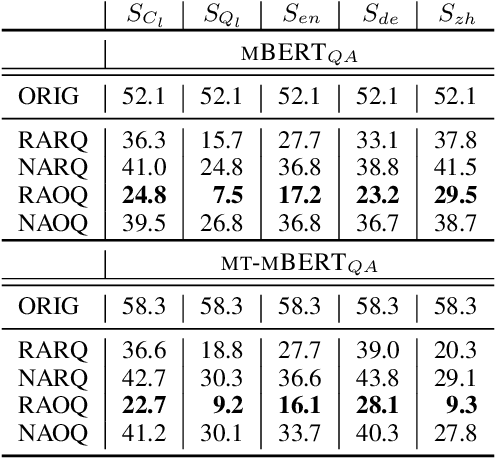
Recent approaches have exploited weaknesses in monolingual question answering (QA) models by adding adversarial statements to the passage. These attacks caused a reduction in state-of-the-art performance by almost 50%. In this paper, we are the first to explore and successfully attack a multilingual QA (MLQA) system pre-trained on multilingual BERT using several attack strategies for the adversarial statement reducing performance by as much as 85%. We show that the model gives priority to English and the language of the question regardless of the other languages in the QA pair. Further, we also show that adding our attack strategies during training helps alleviate the attacks.
Multilingual Transfer Learning for QA Using Translation as Data Augmentation
Dec 10, 2020

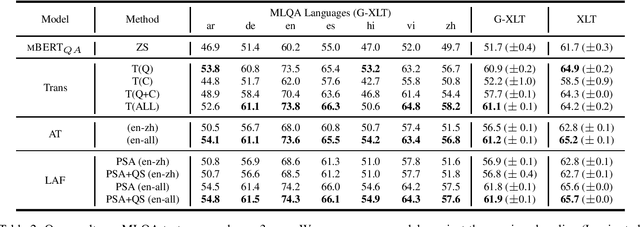
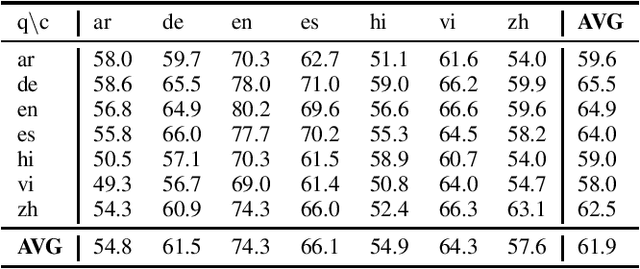
Prior work on multilingual question answering has mostly focused on using large multilingual pre-trained language models (LM) to perform zero-shot language-wise learning: train a QA model on English and test on other languages. In this work, we explore strategies that improve cross-lingual transfer by bringing the multilingual embeddings closer in the semantic space. Our first strategy augments the original English training data with machine translation-generated data. This results in a corpus of multilingual silver-labeled QA pairs that is 14 times larger than the original training set. In addition, we propose two novel strategies, language adversarial training and language arbitration framework, which significantly improve the (zero-resource) cross-lingual transfer performance and result in LM embeddings that are less language-variant. Empirically, we show that the proposed models outperform the previous zero-shot baseline on the recently introduced multilingual MLQA and TyDiQA datasets.
Exploring Software Naturalness through Neural Language Models
Jun 24, 2020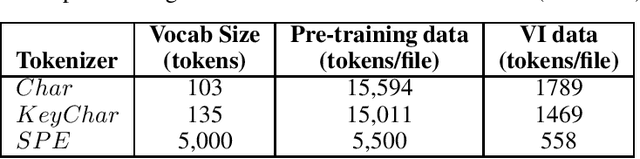
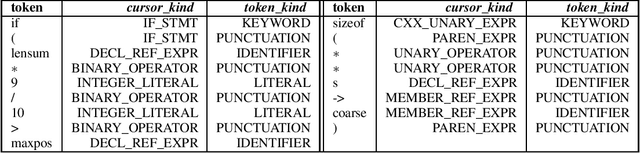
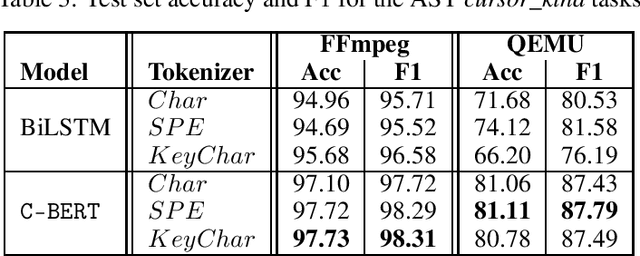
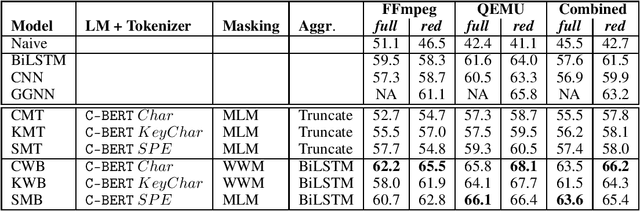
The Software Naturalness hypothesis argues that programming languages can be understood through the same techniques used in natural language processing. We explore this hypothesis through the use of a pre-trained transformer-based language model to perform code analysis tasks. Present approaches to code analysis depend heavily on features derived from the Abstract Syntax Tree (AST) while our transformer-based language models work on raw source code. This work is the first to investigate whether such language models can discover AST features automatically. To achieve this, we introduce a sequence labeling task that directly probes the language models understanding of AST. Our results show that transformer based language models achieve high accuracy in the AST tagging task. Furthermore, we evaluate our model on a software vulnerability identification task. Importantly, we show that our approach obtains vulnerability identification results comparable to graph based approaches that rely heavily on compilers for feature extraction.