 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Lip-synchrony in Direct Audio-Visual Speech-to-Speech Translation
Dec 21, 2024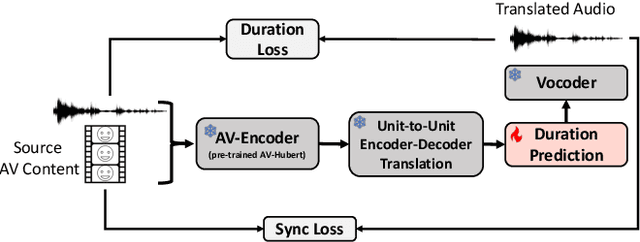



Audio-Visual Speech-to-Speech Translation typically prioritizes improving translation quality and naturalness. However, an equally critical aspect in audio-visual content is lip-synchrony-ensuring that the movements of the lips match the spoken content-essential for maintaining realism in dubbed videos. Despite its importance, the inclusion of lip-synchrony constraints in AVS2S models has been largely overlooked. This study addresses this gap by integrating a lip-synchrony loss into the training process of AVS2S models. Our proposed method significantly enhances lip-synchrony in direct audio-visual speech-to-speech translation, achieving an average LSE-D score of 10.67, representing a 9.2% reduction in LSE-D over a strong baseline across four language pairs. Additionally, it maintains the naturalness and high quality of the translated speech when overlaid onto the original video, without any degradation in translation quality.
SPARTAN: Sparse Hierarchical Memory for Parameter-Efficient Transformers
Nov 29, 2022



Fine-tuning pre-trained language models (PLMs) achieves impressive performance on a range of downstream tasks, and their sizes have consequently been getting bigger. Since a different copy of the model is required for each task, this paradigm is infeasible for storage-constrained edge devices like mobile phones. In this paper, we propose SPARTAN, a parameter efficient (PE) and computationally fast architecture for edge devices that adds hierarchically organized sparse memory after each Transformer layer. SPARTAN freezes the PLM parameters and fine-tunes only its memory, thus significantly reducing storage costs by re-using the PLM backbone for different tasks. SPARTAN contains two levels of memory, with only a sparse subset of parents being chosen in the first level for each input, and children cells corresponding to those parents being used to compute an output representation. This sparsity combined with other architecture optimizations improves SPARTAN's throughput by over 90% during inference on a Raspberry Pi 4 when compared to PE baselines (adapters) while also outperforming the latter by 0.1 points on the GLUE benchmark. Further, it can be trained 34% faster in a few-shot setting, while performing within 0.9 points of adapters. Qualitative analysis shows that different parent cells in SPARTAN specialize in different topics, thus dividing responsibility efficiently.
GAAMA 2.0: An Integrated System that Answers Boolean and Extractive Questions
Jun 21, 2022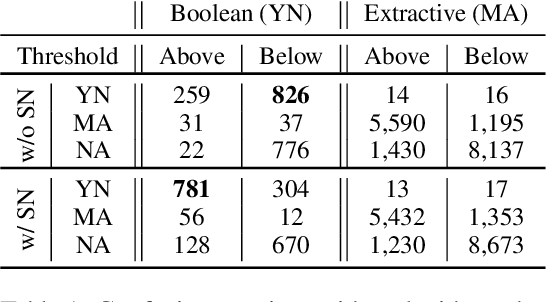
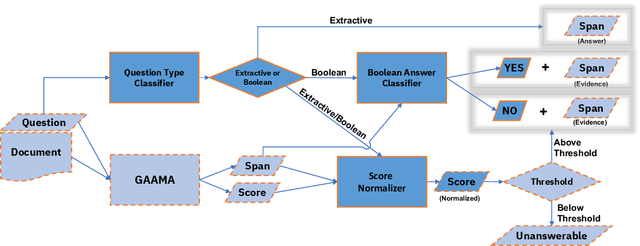


Recent machine reading comprehension datasets include extractive and boolean questions but current approaches do not offer integrated support for answering both question types. We present a multilingual machine reading comprehension system and front-end demo that handles boolean questions by providing both a YES/NO answer and highlighting supporting evidence, and handles extractive questions by highlighting the answer in the passage. Our system, GAAMA 2.0, is ranked first on the Tydi QA leaderboard at the time of this writing. We contrast two different implementations of our approach. The first includes several independent stacks of transformers allowing easy deployment of each component. The second is a single stack of transformers utilizing adapters to reduce GPU memory footprint in a resource-constrained environment.
VAULT: VAriable Unified Long Text Representation for Machine Reading Comprehension
Jun 02, 2021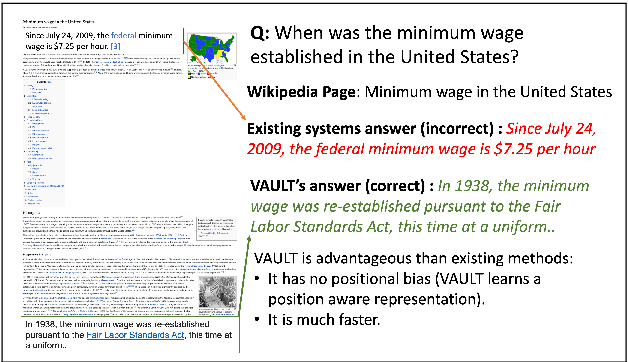
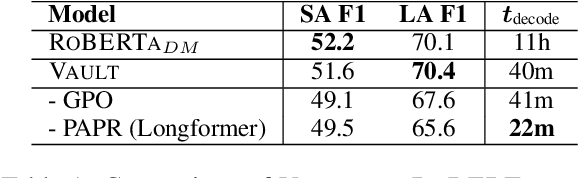
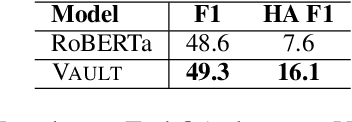
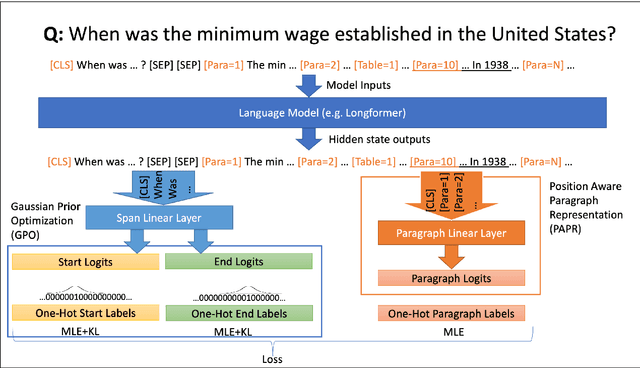
Existing models on Machine Reading Comprehension (MRC) require complex model architecture for effectively modeling long texts with paragraph representation and classification, thereby making inference computationally inefficient for production use. In this work, we propose VAULT: a light-weight and parallel-efficient paragraph representation for MRC based on contextualized representation from long document input, trained using a new Gaussian distribution-based objective that pays close attention to the partially correct instances that are close to the ground-truth. We validate our VAULT architecture showing experimental results on two benchmark MRC datasets that require long context modeling; one Wikipedia-based (Natural Questions (NQ)) and the other on TechNotes (TechQA). VAULT can achieve comparable performance on NQ with a state-of-the-art (SOTA) complex document modeling approach while being 16 times faster, demonstrating the efficiency of our proposed model. We also demonstrate that our model can also be effectively adapted to a completely different domain -- TechQA -- with large improvement over a model fine-tuned on a previously published large PLM.
Multi-Stage Pre-training for Low-Resource Domain Adaptation
Oct 12, 2020
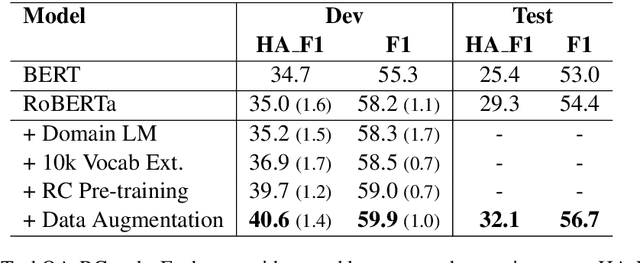
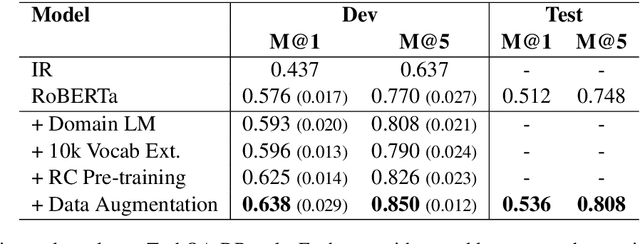
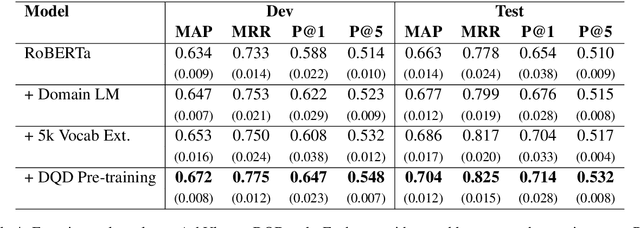
Transfer learning techniques are particularly useful in NLP tasks where a sizable amount of high-quality annotated data is difficult to obtain. Current approaches directly adapt a pre-trained language model (LM) on in-domain text before fine-tuning to downstream tasks. We show that extending the vocabulary of the LM with domain-specific terms leads to further gains. To a bigger effect, we utilize structure in the unlabeled data to create auxiliary synthetic tasks, which helps the LM transfer to downstream tasks. We apply these approaches incrementally on a pre-trained Roberta-large LM and show considerable performance gain on three tasks in the IT domain: Extractive Reading Comprehension, Document Ranking and Duplicate Question Detection.
The TechQA Dataset
Nov 08, 2019

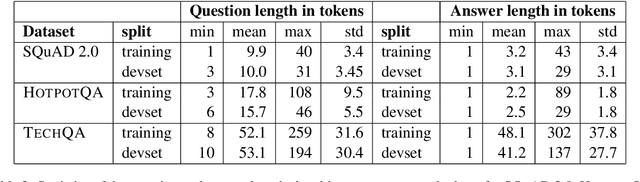
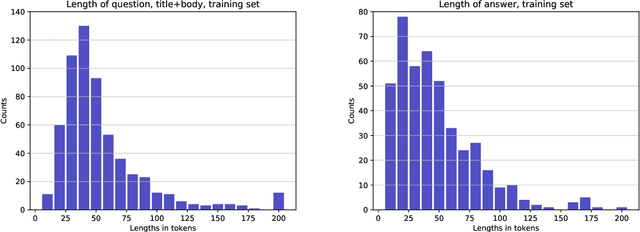
We introduce TechQA, a domain-adaptation question answering dataset for the technical support domain. The TechQA corpus highlights two real-world issues from the automated customer support domain. First, it contains actual questions posed by users on a technical forum, rather than questions generated specifically for a competition or a task. Second, it has a real-world size -- 600 training, 310 dev, and 490 evaluation question/answer pairs -- thus reflecting the cost of creating large labeled datasets with actual data. Consequently, TechQA is meant to stimulate research in domain adaptation rather than being a resource to build QA systems from scratch. The dataset was obtained by crawling the IBM Developer and IBM DeveloperWorks forums for questions with accepted answers that appear in a published IBM Technote---a technical document that addresses a specific technical issue. We also release a collection of the 801,998 publicly available Technotes as of April 4, 2019 as a companion resource that might be used for pretraining, to learn representations of the IT domain language.
Ensembling Strategies for Answering Natural Questions
Nov 06, 2019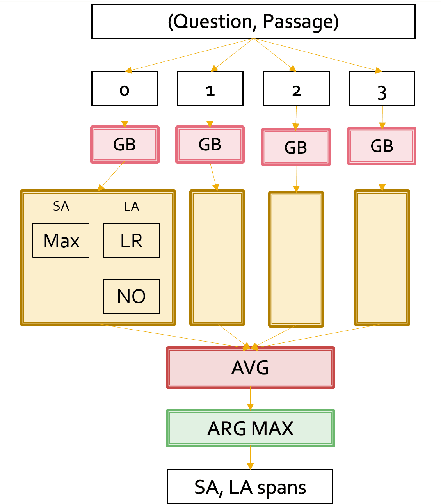

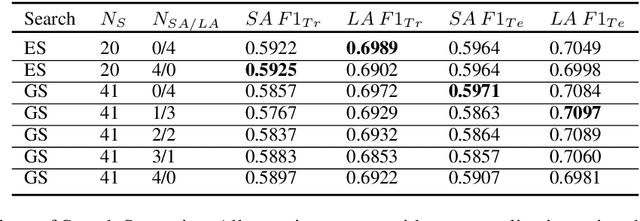
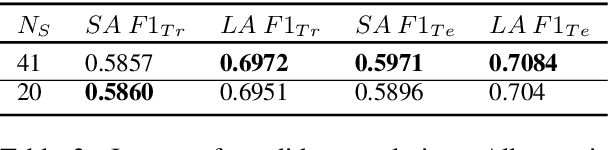
Many of the top question answering systems today utilize ensembling to improve their performance on tasks such as the Stanford Question Answering Dataset (SQuAD) and Natural Questions (NQ) challenges. Unfortunately most of these systems do not publish their ensembling strategies used in their leaderboard submissions. In this work, we investigate a number of ensembling techniques and demonstrate a strategy which improves our F1 score for short answers on the dev set for NQ by 2.3 F1 points over our single model (which outperforms the previous SOTA by 1.9 F1 points).
Frustratingly Easy Natural Question Answering
Sep 11, 2019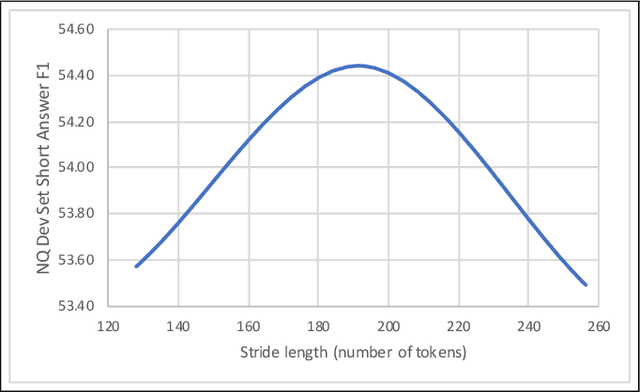
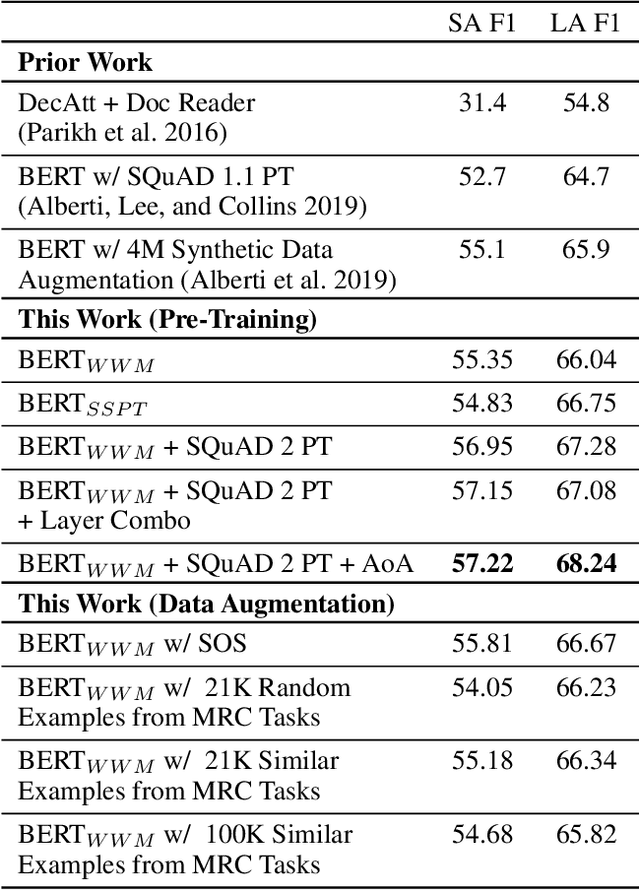
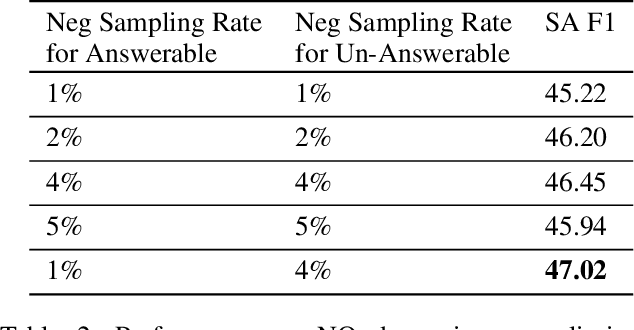
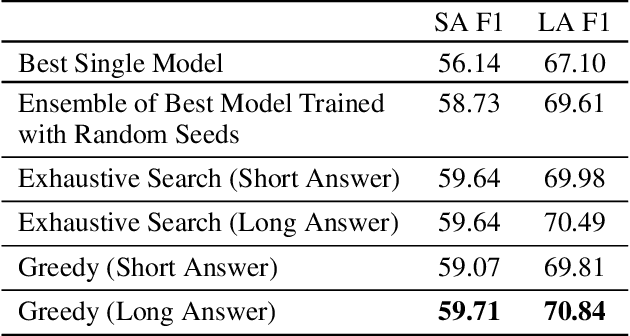
Existing literature on Question Answering (QA) mostly focuses on algorithmic novelty, data augmentation, or increasingly large pre-trained language models like XLNet and RoBERTa. Additionally, a lot of systems on the QA leaderboards do not have associated research documentation in order to successfully replicate their experiments. In this paper, we outline these algorithmic components such as Attention-over-Attention, coupled with data augmentation and ensembling strategies that have shown to yield state-of-the-art results on benchmark datasets like SQuAD, even achieving super-human performance. Contrary to these prior results, when we evaluate on the recently proposed Natural Questions benchmark dataset, we find that an incredibly simple approach of transfer learning from BERT outperforms the previous state-of-the-art system trained on 4 million more examples than ours by 1.9 F1 points. Adding ensembling strategies further improves that number by 2.3 F1 points.
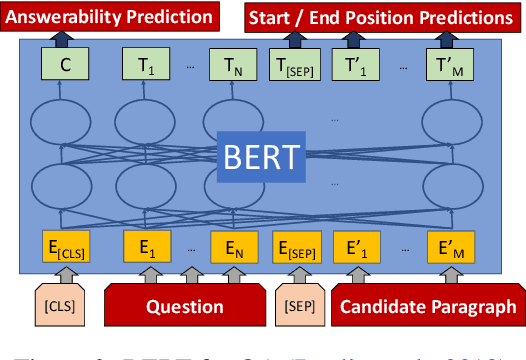
Span Selection Pre-training for Question Answering
Sep 09, 2019
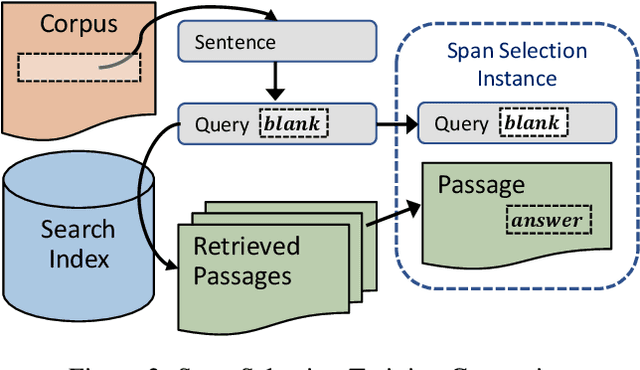

BERT (Bidirectional Encoder Representations from Transformers) and related pre-trained Transformers have provided large gains across many language understanding tasks, achieving a new state-of-the-art (SOTA). BERT is pre-trained on two auxiliary tasks: Masked Language Model and Next Sentence Prediction. In this paper we introduce a new pre-training task inspired by reading comprehension and an effort to avoid encoding general knowledge in the transformer network itself. We find significant and consistent improvements over both BERT-BASE and BERT-LARGE on multiple reading comprehension (MRC) and paraphrasing datasets. Specifically, our proposed model has strong empirical evidence as it obtains SOTA results on Natural Questions, a new benchmark MRC dataset, outperforming BERT-LARGE by 3 F1 points on short answer prediction. We also establish a new SOTA in HotpotQA, improving answer prediction F1 by 4 F1 points and supporting fact prediction by 1 F1 point. Moreover, we show that our pre-training approach is particularly effective when training data is limited, improving the learning curve by a large amount.
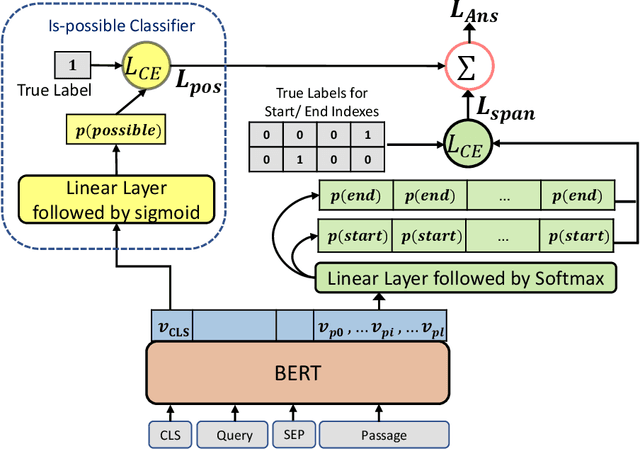
CFO: A Framework for Building Production NLP Systems
Aug 30, 2019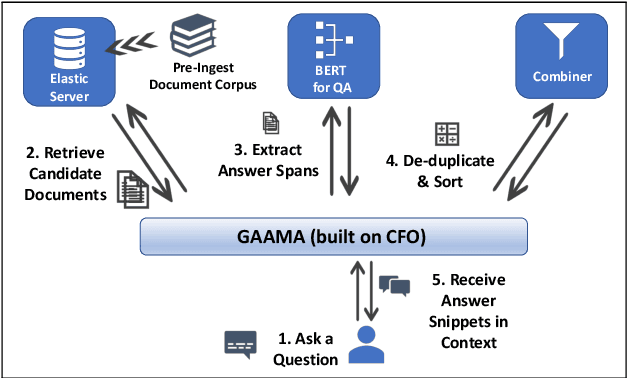
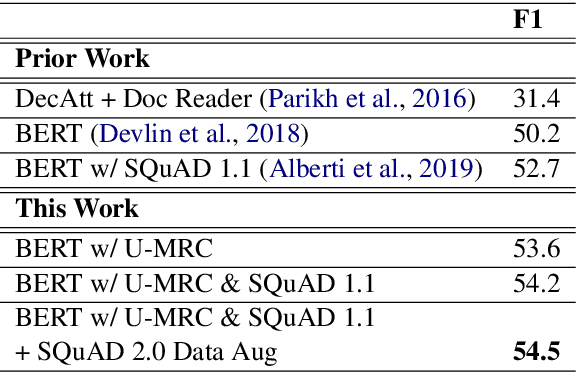

This paper introduces a novel orchestration framework, called CFO (COMPUTATION FLOW ORCHESTRATOR), for building, experimenting with, and deploying interactive NLP (Natural Language Processing) and IR (Information Retrieval) systems to production environments. We then demonstrate a question answering system built using this framework which incorporates state-of-the-art BERT based MRC (Machine Reading Comprehension) with IR components to enable end-to-end answer retrieval. Results from the demo system are shown to be high quality in both academic and industry domain specific settings. Finally, we discuss best practices when (pre-)training BERT based MRC models for production systems.