 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Multilingual R2 Models
May 13, 2026We introduce the multilingual Granite Embedding R2 models, a family of encoder-based embedding models for enterprise-scale dense retrieval across 200+ languages. Extending our English-focused R2 release, these models add enhanced support for 52 languages and programming code, a 32,768-token context window (a 64x expansion over R1), and state-of-the-art overall performance across multilingual and cross-lingual text search, code retrieval, long-document search, and reasoning retrieval datasets. The release consists of two bi-encoder models based on the ModernBERT architecture with an expanded multilingual vocabulary: a 311M-parameter full-size, and a 97M-parameter compact model built via model pruning and vocabulary selection that achieves the highest retrieval score of any open multilingual embedding model under 100M parameters. The full-size also supports Matryoshka Representation Learning for flexible embedding dimensionality. Both models are trained on enterprise-appropriate data with governance oversight, and released under the Apache 2.0 license at https://huggingface.co/collections/ibm-granite, designed to support responsible use and enable unrestricted research and enterprise adoption.
Bootstrapping Multilingual AMR with Contextual Word Alignments
Feb 03, 2021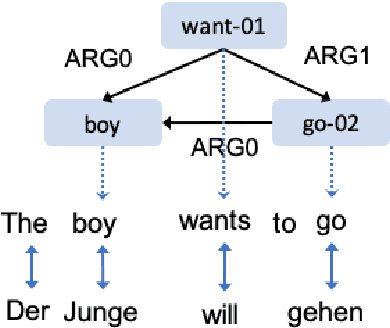
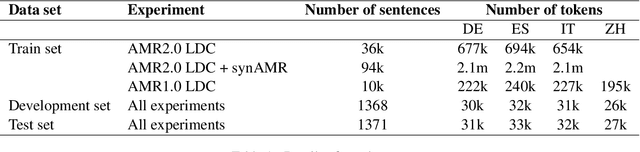
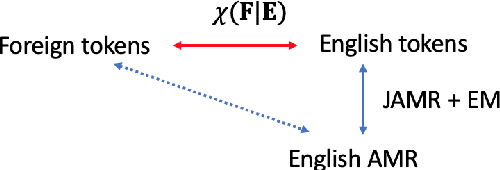

We develop high performance multilingualAbstract Meaning Representation (AMR) sys-tems by projecting English AMR annotationsto other languages with weak supervision. Weachieve this goal by bootstrapping transformer-based multilingual word embeddings, in partic-ular those from cross-lingual RoBERTa (XLM-R large). We develop a novel technique forforeign-text-to-English AMR alignment, usingthe contextual word alignment between En-glish and foreign language tokens. This wordalignment is weakly supervised and relies onthe contextualized XLM-R word embeddings.We achieve a highly competitive performancethat surpasses the best published results forGerman, Italian, Spanish and Chinese.
Multi-Stage Pre-training for Low-Resource Domain Adaptation
Oct 12, 2020
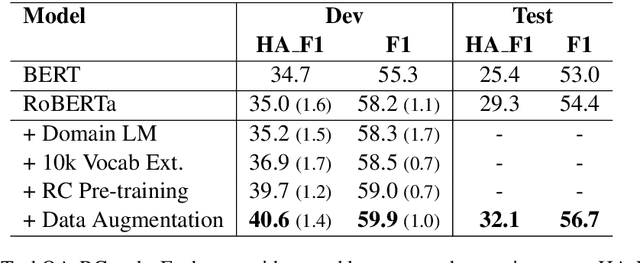
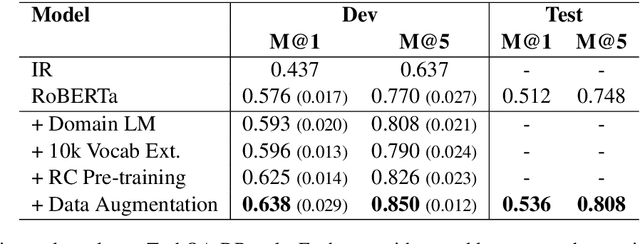
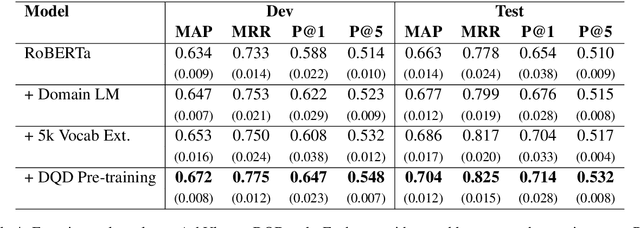
Transfer learning techniques are particularly useful in NLP tasks where a sizable amount of high-quality annotated data is difficult to obtain. Current approaches directly adapt a pre-trained language model (LM) on in-domain text before fine-tuning to downstream tasks. We show that extending the vocabulary of the LM with domain-specific terms leads to further gains. To a bigger effect, we utilize structure in the unlabeled data to create auxiliary synthetic tasks, which helps the LM transfer to downstream tasks. We apply these approaches incrementally on a pre-trained Roberta-large LM and show considerable performance gain on three tasks in the IT domain: Extractive Reading Comprehension, Document Ranking and Duplicate Question Detection.
The TechQA Dataset
Nov 08, 2019

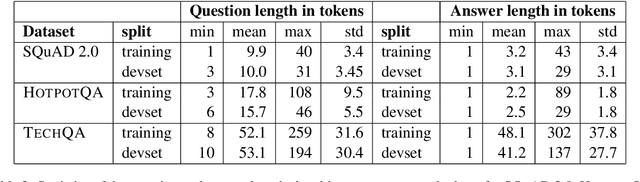
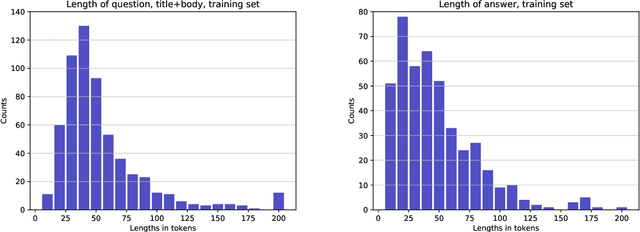
We introduce TechQA, a domain-adaptation question answering dataset for the technical support domain. The TechQA corpus highlights two real-world issues from the automated customer support domain. First, it contains actual questions posed by users on a technical forum, rather than questions generated specifically for a competition or a task. Second, it has a real-world size -- 600 training, 310 dev, and 490 evaluation question/answer pairs -- thus reflecting the cost of creating large labeled datasets with actual data. Consequently, TechQA is meant to stimulate research in domain adaptation rather than being a resource to build QA systems from scratch. The dataset was obtained by crawling the IBM Developer and IBM DeveloperWorks forums for questions with accepted answers that appear in a published IBM Technote---a technical document that addresses a specific technical issue. We also release a collection of the 801,998 publicly available Technotes as of April 4, 2019 as a companion resource that might be used for pretraining, to learn representations of the IT domain language.
Multilingual Neural Machine Translation with Task-Specific Attention
Jun 08, 2018
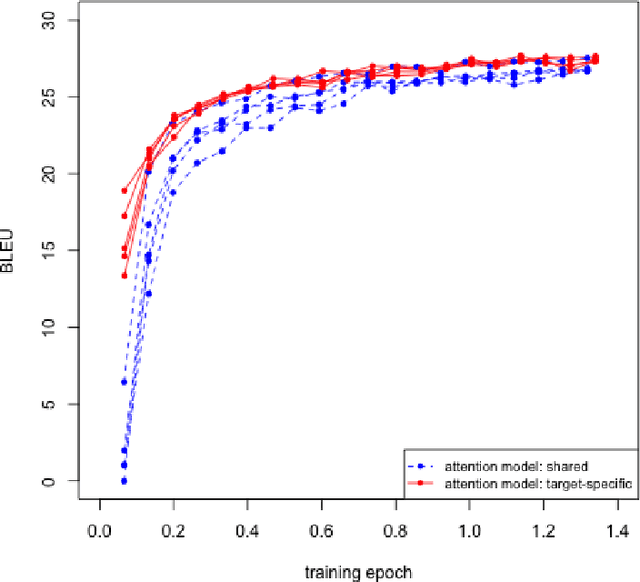
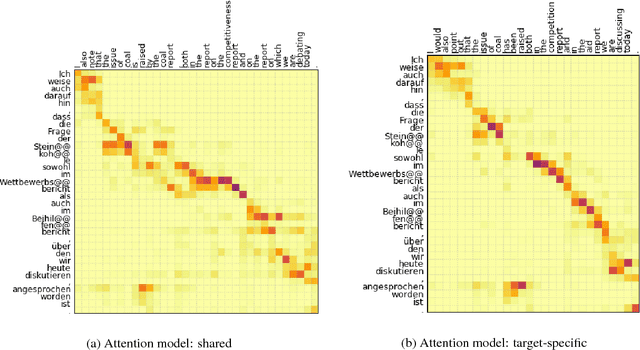
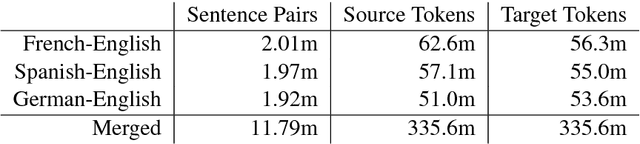
Multilingual machine translation addresses the task of translating between multiple source and target languages. We propose task-specific attention models, a simple but effective technique for improving the quality of sequence-to-sequence neural multilingual translation. Our approach seeks to retain as much of the parameter sharing generalization of NMT models as possible, while still allowing for language-specific specialization of the attention model to a particular language-pair or task. Our experiments on four languages of the Europarl corpus show that using a target-specific model of attention provides consistent gains in translation quality for all possible translation directions, compared to a model in which all parameters are shared. We observe improved translation quality even in the (extreme) low-resource zero-shot translation directions for which the model never saw explicitly paired parallel data.