 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlide, Constrain, Parse, Repeat: Synchronous SlidingWindows for Document AMR Parsing
May 26, 2023The sliding window approach provides an elegant way to handle contexts of sizes larger than the Transformer's input window, for tasks like language modeling. Here we extend this approach to the sequence-to-sequence task of document parsing. For this, we exploit recent progress in transition-based parsing to implement a parser with synchronous sliding windows over source and target. We develop an oracle and a parser for document-level AMR by expanding on Structured-BART such that it leverages source-target alignments and constrains decoding to guarantee synchronicity and consistency across overlapping windows. We evaluate our oracle and parser using the Abstract Meaning Representation (AMR) parsing 3.0 corpus. On the Multi-Sentence development set of AMR 3.0, we show that our transition oracle loses only 8\% of the gold cross-sentential links despite using a sliding window. In practice, this approach also results in a high-quality document-level parser with manageable memory requirements. Our proposed system performs on par with the state-of-the-art pipeline approach for document-level AMR parsing task on Multi-Sentence AMR 3.0 corpus while maintaining sentence-level parsing performance.
Inducing and Using Alignments for Transition-based AMR Parsing
May 03, 2022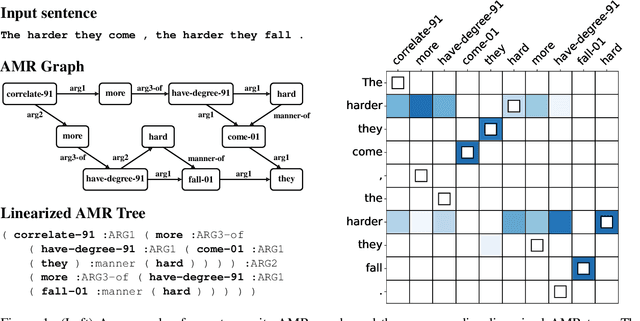
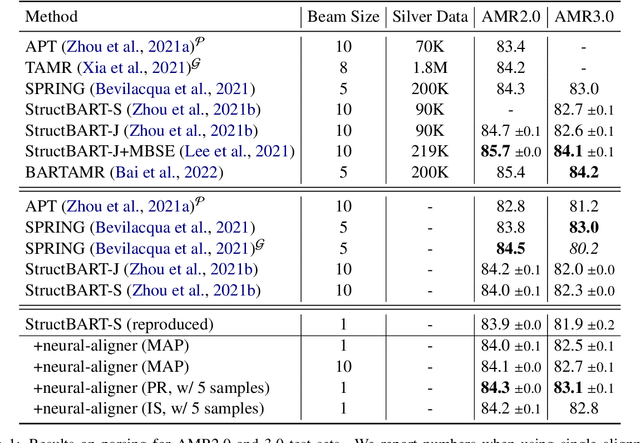

Transition-based parsers for Abstract Meaning Representation (AMR) rely on node-to-word alignments. These alignments are learned separately from parser training and require a complex pipeline of rule-based components, pre-processing, and post-processing to satisfy domain-specific constraints. Parsers also train on a point-estimate of the alignment pipeline, neglecting the uncertainty due to the inherent ambiguity of alignment. In this work we explore two avenues for overcoming these limitations. First, we propose a neural aligner for AMR that learns node-to-word alignments without relying on complex pipelines. We subsequently explore a tighter integration of aligner and parser training by considering a distribution over oracle action sequences arising from aligner uncertainty. Empirical results show this approach leads to more accurate alignments and generalization better from the AMR2.0 to AMR3.0 corpora. We attain a new state-of-the art for gold-only trained models, matching silver-trained performance without the need for beam search on AMR3.0.
Learning to Transpile AMR into SPARQL
Dec 15, 2021

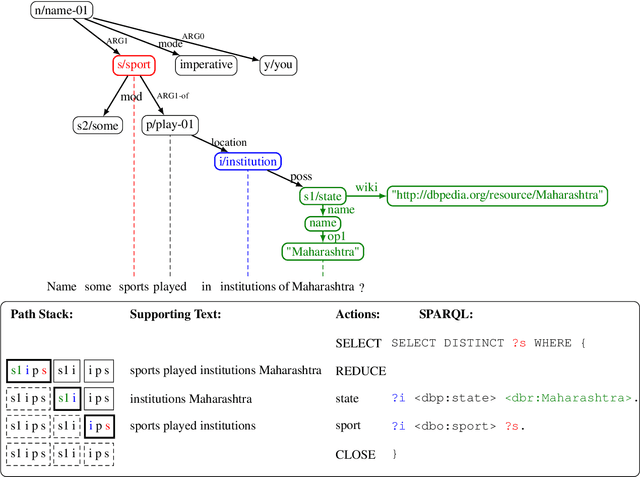
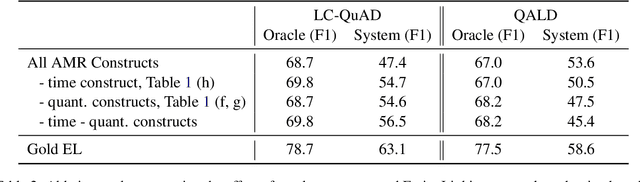
We propose a transition-based system to transpile Abstract Meaning Representation (AMR) into SPARQL for Knowledge Base Question Answering (KBQA). This allows to delegate part of the abstraction problem to a strongly pre-trained semantic parser, while learning transpiling with small amount of paired data. We departure from recent work relating AMR and SPARQL constructs, but rather than applying a set of rules, we teach the BART model to selectively use these relations. Further, we avoid explicitly encoding AMR but rather encode the parser state in the attention mechanism of BART, following recent semantic parsing works. The resulting model is simple, provides supporting text for its decisions, and outperforms recent progress in AMR-based KBQA in LC-QuAD (F1 53.4), matching it in QALD (F1 30.8), while exploiting the same inductive biases.
Maximum Bayes Smatch Ensemble Distillation for AMR Parsing
Dec 14, 2021
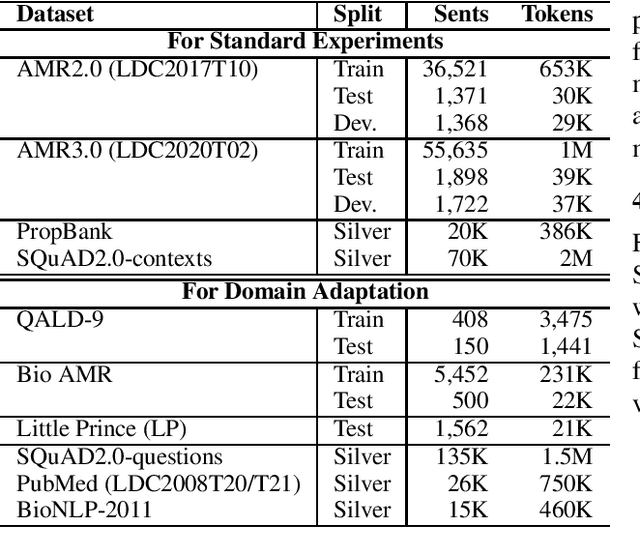

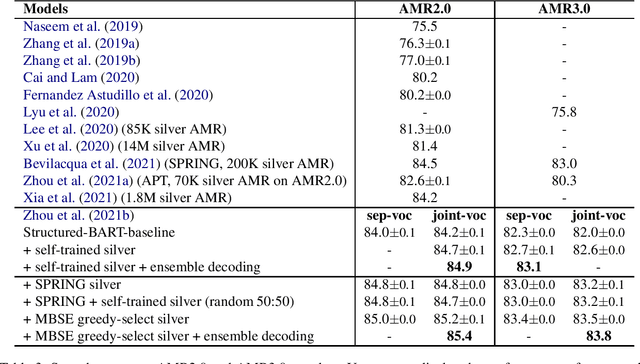
AMR parsing has experienced an unprecendented increase in performance in the last three years, due to a mixture of effects including architecture improvements and transfer learning. Self-learning techniques have also played a role in pushing performance forward. However, for most recent high performant parsers, the effect of self-learning and silver data generation seems to be fading. In this paper we show that it is possible to overcome this diminishing returns of silver data by combining Smatch-based ensembling techniques with ensemble distillation. In an extensive experimental setup, we push single model English parser performance above 85 Smatch for the first time and return to substantial gains. We also attain a new state-of-the-art for cross-lingual AMR parsing for Chinese, German, Italian and Spanish. Finally we explore the impact of the proposed distillation technique on domain adaptation, and show that it can produce gains rivaling those of human annotated data for QALD-9 and achieve a new state-of-the-art for BioAMR.
Ensembling Graph Predictions for AMR Parsing
Oct 18, 2021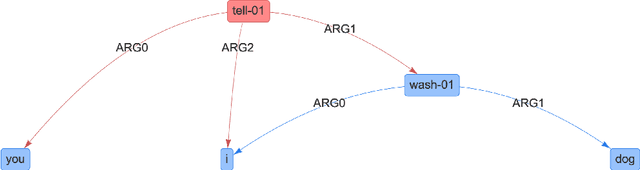
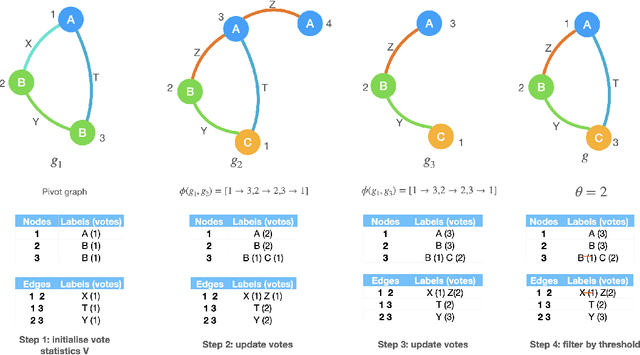
In many machine learning tasks, models are trained to predict structure data such as graphs. For example, in natural language processing, it is very common to parse texts into dependency trees or abstract meaning representation (AMR) graphs. On the other hand, ensemble methods combine predictions from multiple models to create a new one that is more robust and accurate than individual predictions. In the literature, there are many ensembling techniques proposed for classification or regression problems, however, ensemble graph prediction has not been studied thoroughly. In this work, we formalize this problem as mining the largest graph that is the most supported by a collection of graph predictions. As the problem is NP-Hard, we propose an efficient heuristic algorithm to approximate the optimal solution. To validate our approach, we carried out experiments in AMR parsing problems. The experimental results demonstrate that the proposed approach can combine the strength of state-of-the-art AMR parsers to create new predictions that are more accurate than any individual models in five standard benchmark datasets.
EAT: Enhanced ASR-TTS for Self-supervised Speech Recognition
Apr 13, 2021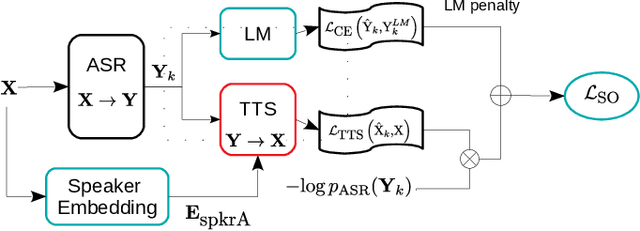



Self-supervised ASR-TTS models suffer in out-of-domain data conditions. Here we propose an enhanced ASR-TTS (EAT) model that incorporates two main features: 1) The ASR$\rightarrow$TTS direction is equipped with a language model reward to penalize the ASR hypotheses before forwarding it to TTS. 2) In the TTS$\rightarrow$ASR direction, a hyper-parameter is introduced to scale the attention context from synthesized speech before sending it to ASR to handle out-of-domain data. Training strategies and the effectiveness of the EAT model are explored under out-of-domain data conditions. The results show that EAT reduces the performance gap between supervised and self-supervised training significantly by absolute 2.6\% and 2.7\% on Librispeech and BABEL respectively.
Bootstrapping Multilingual AMR with Contextual Word Alignments
Feb 03, 2021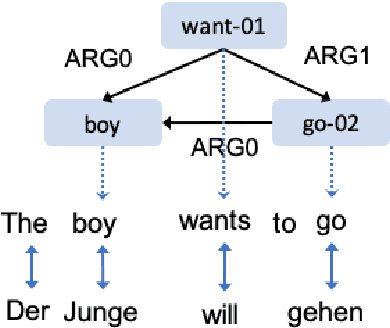
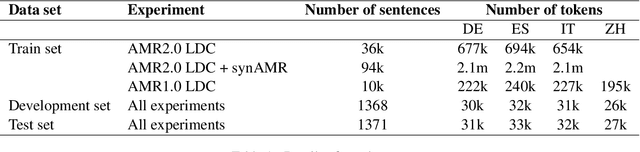
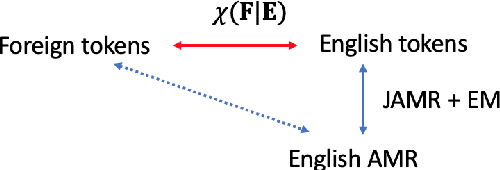

We develop high performance multilingualAbstract Meaning Representation (AMR) sys-tems by projecting English AMR annotationsto other languages with weak supervision. Weachieve this goal by bootstrapping transformer-based multilingual word embeddings, in partic-ular those from cross-lingual RoBERTa (XLM-R large). We develop a novel technique forforeign-text-to-English AMR alignment, usingthe contextual word alignment between En-glish and foreign language tokens. This wordalignment is weakly supervised and relies onthe contextualized XLM-R word embeddings.We achieve a highly competitive performancethat surpasses the best published results forGerman, Italian, Spanish and Chinese.
Pushing the Limits of AMR Parsing with Self-Learning
Oct 20, 2020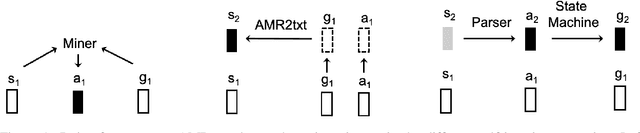

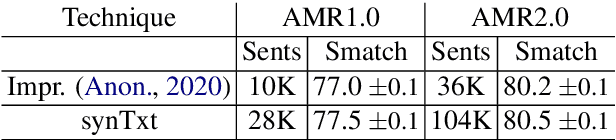
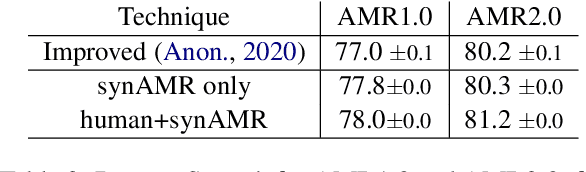
Abstract Meaning Representation (AMR) parsing has experienced a notable growth in performance in the last two years, due both to the impact of transfer learning and the development of novel architectures specific to AMR. At the same time, self-learning techniques have helped push the performance boundaries of other natural language processing applications, such as machine translation or question answering. In this paper, we explore different ways in which trained models can be applied to improve AMR parsing performance, including generation of synthetic text and AMR annotations as well as refinement of actions oracle. We show that, without any additional human annotations, these techniques improve an already performant parser and achieve state-of-the-art results on AMR 1.0 and AMR 2.0.
Transition-based Parsing with Stack-Transformers
Oct 20, 2020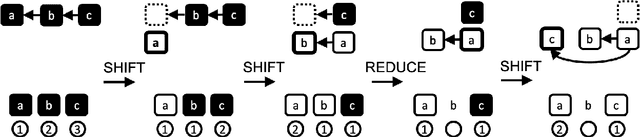

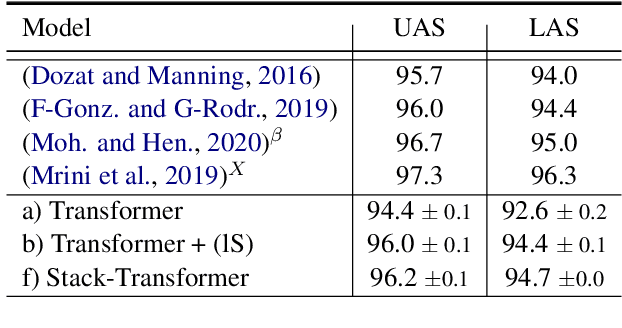
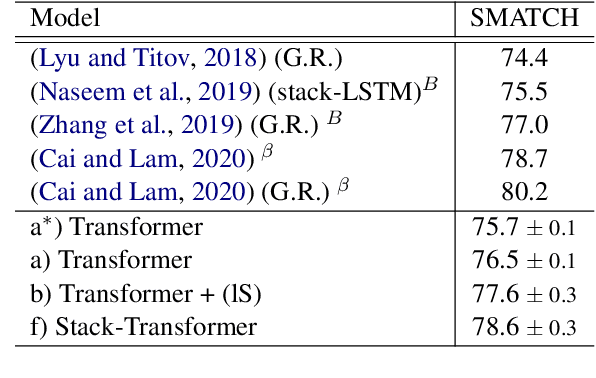
Modeling the parser state is key to good performance in transition-based parsing. Recurrent Neural Networks considerably improved the performance of transition-based systems by modelling the global state, e.g. stack-LSTM parsers, or local state modeling of contextualized features, e.g. Bi-LSTM parsers. Given the success of Transformer architectures in recent parsing systems, this work explores modifications of the sequence-to-sequence Transformer architecture to model either global or local parser states in transition-based parsing. We show that modifications of the cross attention mechanism of the Transformer considerably strengthen performance both on dependency and Abstract Meaning Representation (AMR) parsing tasks, particularly for smaller models or limited training data.
GPT-too: A language-model-first approach for AMR-to-text generation
May 27, 2020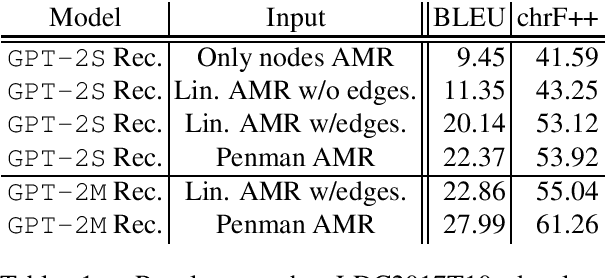

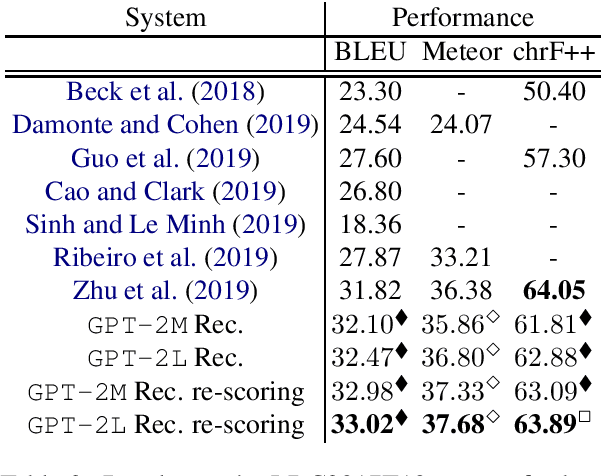

Meaning Representations (AMRs) are broad-coverage sentence-level semantic graphs. Existing approaches to generating text from AMR have focused on training sequence-to-sequence or graph-to-sequence models on AMR annotated data only. In this paper, we propose an alternative approach that combines a strong pre-trained language model with cycle consistency-based re-scoring. Despite the simplicity of the approach, our experimental results show these models outperform all previous techniques on the English LDC2017T10dataset, including the recent use of transformer architectures. In addition to the standard evaluation metrics, we provide human evaluation experiments that further substantiate the strength of our approach.