 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransition-based Parsing with Stack-Transformers
Paper and Code
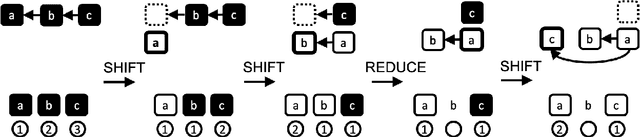

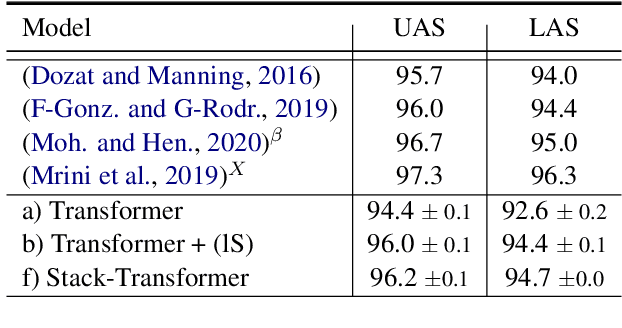
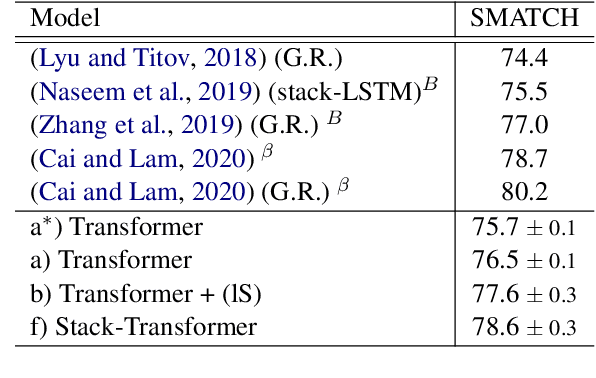
Modeling the parser state is key to good performance in transition-based parsing. Recurrent Neural Networks considerably improved the performance of transition-based systems by modelling the global state, e.g. stack-LSTM parsers, or local state modeling of contextualized features, e.g. Bi-LSTM parsers. Given the success of Transformer architectures in recent parsing systems, this work explores modifications of the sequence-to-sequence Transformer architecture to model either global or local parser states in transition-based parsing. We show that modifications of the cross attention mechanism of the Transformer considerably strengthen performance both on dependency and Abstract Meaning Representation (AMR) parsing tasks, particularly for smaller models or limited training data.