 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Continuous-Time Markov Chain Framework for Insertion Language Models
Jun 08, 2026Insertion Language Models (ILMs) offer several advantages over left-to-right generation and mask-based generation. However, existing formulations of insertion-based generation have largely been ad-hoc. In this paper, we derive a diffusion-style denoising objective for ILMs from first principles by formulating the noising process as a continuous-time Markov chain on the space of variable-length sequences. We show that previous formulations of ILMs can be viewed as special cases of this denoising framework. Through empirical evaluation on a synthetic planning task, we show that the proposed approach retains the benefits of insertion-based generation over left-to-right generation and masked diffusion models. In language modeling, our diffusion-based approach is competitive with left-to-right generation and masked diffusion models, while offering additional flexibility in sampling compared to existing insertion language models.
Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought
Apr 27, 2026While long, explicit chains-of-thought (CoT) have proven effective on complex reasoning tasks, they are costly to generate during inference. Non-verbal reasoning methods have emerged with shorter generation lengths by leveraging continuous representations, yet their performance lags behind verbalized CoT. We propose $\textbf{Abstract Chain-of-Thought}$, a discrete latent reasoning post-training mechanism in which the language model produces a short sequence of tokens from a reserved vocabulary in lieu of a natural language CoT, before generating a response. To make previously unseen ''abstract'' tokens useful, we introduce a policy iteration-style warm-up loop that alternates between (i.) bottlenecking from a verbal CoT via masking and performing supervised fine-tuning, and (ii.) self-distillation by training the model to generate abstract tokens from the prompt alone via constrained decoding with the codebook. After warm-up, we optimize the generation of abstract sequences with warm-started reinforcement learning under constrained decoding. Abstract-CoT achieves up to $11.6\times$ fewer reasoning tokens while demonstrating comparable performance across mathematical reasoning, instruction-following, and multi-hop reasoning, and generalizes across language model families. We also find an emergent power law distribution over the abstract vocabulary, akin to those seen in natural language, that evolves across the training phases. Our findings highlight the potential for post-training latent reasoning mechanisms that enable efficient inference through a learned abstract reasoning language.
Latent Principle Discovery for Language Model Self-Improvement
May 22, 2025When language model (LM) users aim to improve the quality of its generations, it is crucial to specify concrete behavioral attributes that the model should strive to reflect. However, curating such principles across many domains, even non-exhaustively, requires a labor-intensive annotation process. To automate this process, we propose eliciting these latent attributes guiding model reasoning towards human-preferred responses by explicitly modeling them in a self-correction setting. Our approach mines new principles from the LM itself and compresses the discovered elements to an interpretable set via clustering. Specifically, we employ an approximation of posterior-regularized Monte Carlo Expectation-Maximization to both identify a condensed set of the most effective latent principles and teach the LM to strategically invoke them in order to intrinsically refine its responses. We demonstrate that bootstrapping our algorithm over multiple iterations enables smaller language models (7-8B parameters) to self-improve, achieving +8-10% in AlpacaEval win-rate, an average of +0.3 on MT-Bench, and +19-23% in principle-following win-rate on IFEval. We also show that clustering the principles yields interpretable and diverse model-generated constitutions while retaining model performance. The gains our method achieves highlight the potential of automated, principle-driven post-training recipes toward continual self-improvement.
Optimal Policy Minimum Bayesian Risk
May 22, 2025Inference scaling can help LLMs solve complex reasoning problems through extended runtime computation. On top of targeted supervision for long chain-of-thought (long-CoT) generation, purely inference-time techniques such as best-of-N (BoN) sampling, majority voting, or more generally, minimum Bayes risk decoding (MBRD), can further improve LLM accuracy by generating multiple candidate solutions and aggregating over them. These methods typically leverage additional signals in the form of reward models and risk/similarity functions that compare generated samples, e.g., exact match in some normalized space or standard similarity metrics such as Rouge. Here we present a novel method for incorporating reward and risk/similarity signals into MBRD. Based on the concept of optimal policy in KL-controlled reinforcement learning, our framework provides a simple and well-defined mechanism for leveraging such signals, offering several advantages over traditional inference-time methods: higher robustness, improved accuracy, and well-understood asymptotic behavior. In addition, it allows for the development of a sample-efficient variant of MBRD that can adjust the number of samples to generate according to the difficulty of the problem, without relying on majority vote counts. We empirically demonstrate the advantages of our approach on math (MATH-$500$) and coding (HumanEval) tasks using recent open-source models. We also present a comprehensive analysis of its accuracy-compute trade-offs.
Insertion Language Models: Sequence Generation with Arbitrary-Position Insertions
May 09, 2025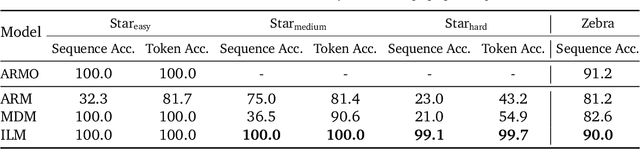



Autoregressive models (ARMs), which predict subsequent tokens one-by-one ``from left to right,'' have achieved significant success across a wide range of sequence generation tasks. However, they struggle to accurately represent sequences that require satisfying sophisticated constraints or whose sequential dependencies are better addressed by out-of-order generation. Masked Diffusion Models (MDMs) address some of these limitations, but the process of unmasking multiple tokens simultaneously in MDMs can introduce incoherences, and MDMs cannot handle arbitrary infilling constraints when the number of tokens to be filled in is not known in advance. In this work, we introduce Insertion Language Models (ILMs), which learn to insert tokens at arbitrary positions in a sequence -- that is, they select jointly both the position and the vocabulary element to be inserted. By inserting tokens one at a time, ILMs can represent strong dependencies between tokens, and their ability to generate sequences in arbitrary order allows them to accurately model sequences where token dependencies do not follow a left-to-right sequential structure. To train ILMs, we propose a tailored network parameterization and use a simple denoising objective. Our empirical evaluation demonstrates that ILMs outperform both ARMs and MDMs on common planning tasks. Furthermore, we show that ILMs outperform MDMs and perform on par with ARMs in an unconditional text generation task while offering greater flexibility than MDMs in arbitrary-length text infilling.
Self-Refinement of Language Models from External Proxy Metrics Feedback
Feb 27, 2024



It is often desirable for Large Language Models (LLMs) to capture multiple objectives when providing a response. In document-grounded response generation, for example, agent responses are expected to be relevant to a user's query while also being grounded in a given document. In this paper, we introduce Proxy Metric-based Self-Refinement (ProMiSe), which enables an LLM to refine its own initial response along key dimensions of quality guided by external metrics feedback, yielding an overall better final response. ProMiSe leverages feedback on response quality through principle-specific proxy metrics, and iteratively refines its response one principle at a time. We apply ProMiSe to open source language models Flan-T5-XXL and Llama-2-13B-Chat, to evaluate its performance on document-grounded question answering datasets, MultiDoc2Dial and QuAC, demonstrating that self-refinement improves response quality. We further show that fine-tuning Llama-2-13B-Chat on the synthetic dialogue data generated by ProMiSe yields significant performance improvements over the zero-shot baseline as well as a supervised fine-tuned model on human annotated data.
BRAIn: Bayesian Reward-conditioned Amortized Inference for natural language generation from feedback
Feb 04, 2024



Following the success of Proximal Policy Optimization (PPO) for Reinforcement Learning from Human Feedback (RLHF), new techniques such as Sequence Likelihood Calibration (SLiC) and Direct Policy Optimization (DPO) have been proposed that are offline in nature and use rewards in an indirect manner. These techniques, in particular DPO, have recently become the tools of choice for LLM alignment due to their scalability and performance. However, they leave behind important features of the PPO approach. Methods such as SLiC or RRHF make use of the Reward Model (RM) only for ranking/preference, losing fine-grained information and ignoring the parametric form of the RM (eg., Bradley-Terry, Plackett-Luce), while methods such as DPO do not use even a separate reward model. In this work, we propose a novel approach, named BRAIn, that re-introduces the RM as part of a distribution matching approach.BRAIn considers the LLM distribution conditioned on the assumption of output goodness and applies Bayes theorem to derive an intractable posterior distribution where the RM is explicitly represented. BRAIn then distills this posterior into an amortized inference network through self-normalized importance sampling, leading to a scalable offline algorithm that significantly outperforms prior art in summarization and AntropicHH tasks. BRAIn also has interesting connections to PPO and DPO for specific RM choices.
Scalable Learning of Latent Language Structure With Logical Offline Cycle Consistency
May 31, 2023



We introduce Logical Offline Cycle Consistency Optimization (LOCCO), a scalable, semi-supervised method for training a neural semantic parser. Conceptually, LOCCO can be viewed as a form of self-learning where the semantic parser being trained is used to generate annotations for unlabeled text that are then used as new supervision. To increase the quality of annotations, our method utilizes a count-based prior over valid formal meaning representations and a cycle-consistency score produced by a neural text generation model as additional signals. Both the prior and semantic parser are updated in an alternate fashion from full passes over the training data, which can be seen as approximating the marginalization of latent structures through stochastic variational inference. The use of a count-based prior, frozen text generation model, and offline annotation process yields an approach with negligible complexity and latency increases as compared to conventional self-learning. As an added bonus, the annotations produced by LOCCO can be trivially repurposed to train a neural text generation model. We demonstrate the utility of LOCCO on the well-known WebNLG benchmark where we obtain an improvement of 2 points against a self-learning parser under equivalent conditions, an improvement of 1.3 points against the previous state-of-the-art parser, and competitive text generation performance in terms of BLEU score.
Slide, Constrain, Parse, Repeat: Synchronous SlidingWindows for Document AMR Parsing
May 26, 2023The sliding window approach provides an elegant way to handle contexts of sizes larger than the Transformer's input window, for tasks like language modeling. Here we extend this approach to the sequence-to-sequence task of document parsing. For this, we exploit recent progress in transition-based parsing to implement a parser with synchronous sliding windows over source and target. We develop an oracle and a parser for document-level AMR by expanding on Structured-BART such that it leverages source-target alignments and constrains decoding to guarantee synchronicity and consistency across overlapping windows. We evaluate our oracle and parser using the Abstract Meaning Representation (AMR) parsing 3.0 corpus. On the Multi-Sentence development set of AMR 3.0, we show that our transition oracle loses only 8\% of the gold cross-sentential links despite using a sliding window. In practice, this approach also results in a high-quality document-level parser with manageable memory requirements. Our proposed system performs on par with the state-of-the-art pipeline approach for document-level AMR parsing task on Multi-Sentence AMR 3.0 corpus while maintaining sentence-level parsing performance.
Laziness Is a Virtue When It Comes to Compositionality in Neural Semantic Parsing
May 07, 2023
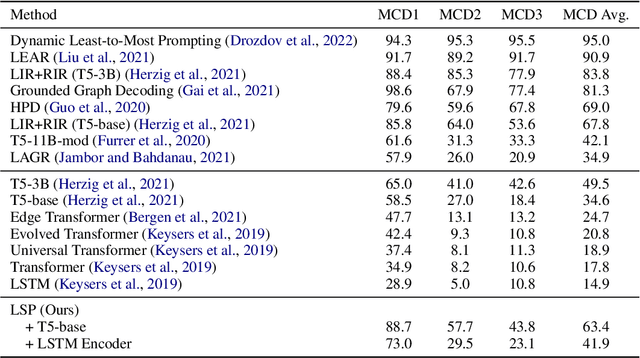


Nearly all general-purpose neural semantic parsers generate logical forms in a strictly top-down autoregressive fashion. Though such systems have achieved impressive results across a variety of datasets and domains, recent works have called into question whether they are ultimately limited in their ability to compositionally generalize. In this work, we approach semantic parsing from, quite literally, the opposite direction; that is, we introduce a neural semantic parsing generation method that constructs logical forms from the bottom up, beginning from the logical form's leaves. The system we introduce is lazy in that it incrementally builds up a set of potential semantic parses, but only expands and processes the most promising candidate parses at each generation step. Such a parsimonious expansion scheme allows the system to maintain an arbitrarily large set of parse hypotheses that are never realized and thus incur minimal computational overhead. We evaluate our approach on compositional generalization; specifically, on the challenging CFQ dataset and three Text-to-SQL datasets where we show that our novel, bottom-up semantic parsing technique outperforms general-purpose semantic parsers while also being competitive with comparable neural parsers that have been designed for each task.