 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc-to-Atom: Learning to Compile and Compose Memory Atoms
Jun 10, 2026Long input sequences are central to document understanding and multi-step reasoning in Large Language Models, yet the quadratic cost of attention makes inference both memory-intensive and slow. Context distillation mitigates this by compressing contextual information into model parameters, and recent work such as Doc-to-LoRA amortizes context distillation into a single forward pass that generates one LoRA adapter per document. However, producing a single monolithic adapter for all queries leads to irrelevant-query interference, limited compositional recall, and poor scalability to long-document reasoning. To address these challenges, we propose Doc-to-Atom (Doc2Atom), a compositional parametric memory framework that decomposes each document into semantically typed knowledge atoms. Each atom is compiled into an independent micro-LoRA adapter and a provenance retrieval key. At inference time, a lightweight query router selects and assembles only the relevant atoms into a query-specific adapter, which is then injected into a frozen base model. The entire system is trained end-to-end through a multi-objective distillation framework. Experiments on six diverse QA benchmarks demonstrate that Doc2Atom outperforms Doc-to-LoRA baselines while reducing the memory cost of document internalization.
VOYAGER: A Training Free Approach for Generating Diverse Datasets using LLMs
Dec 12, 2025Large language models (LLMs) are increasingly being used to generate synthetic datasets for the evaluation and training of downstream models. However, prior work has noted that such generated data lacks diversity. In this paper, we propose Voyager, a novel principled approach to generate diverse datasets. Our approach is iterative and directly optimizes a mathematical quantity that optimizes the diversity of the dataset using the machinery of determinantal point processes. Furthermore, our approach is training-free, applicable to closed-source models, and scalable. In addition to providing theoretical justification for the working of our method, we also demonstrate through comprehensive experiments that Voyager significantly outperforms popular baseline approaches by providing a 1.5-3x improvement in diversity.
Insertion Language Models: Sequence Generation with Arbitrary-Position Insertions
May 09, 2025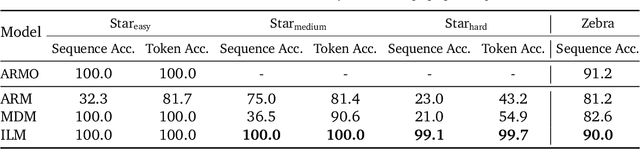



Autoregressive models (ARMs), which predict subsequent tokens one-by-one ``from left to right,'' have achieved significant success across a wide range of sequence generation tasks. However, they struggle to accurately represent sequences that require satisfying sophisticated constraints or whose sequential dependencies are better addressed by out-of-order generation. Masked Diffusion Models (MDMs) address some of these limitations, but the process of unmasking multiple tokens simultaneously in MDMs can introduce incoherences, and MDMs cannot handle arbitrary infilling constraints when the number of tokens to be filled in is not known in advance. In this work, we introduce Insertion Language Models (ILMs), which learn to insert tokens at arbitrary positions in a sequence -- that is, they select jointly both the position and the vocabulary element to be inserted. By inserting tokens one at a time, ILMs can represent strong dependencies between tokens, and their ability to generate sequences in arbitrary order allows them to accurately model sequences where token dependencies do not follow a left-to-right sequential structure. To train ILMs, we propose a tailored network parameterization and use a simple denoising objective. Our empirical evaluation demonstrates that ILMs outperform both ARMs and MDMs on common planning tasks. Furthermore, we show that ILMs outperform MDMs and perform on par with ARMs in an unconditional text generation task while offering greater flexibility than MDMs in arbitrary-length text infilling.
LS-GAN: Human Motion Synthesis with Latent-space GANs
Dec 30, 2024



Human motion synthesis conditioned on textual input has gained significant attention in recent years due to its potential applications in various domains such as gaming, film production, and virtual reality. Conditioned Motion synthesis takes a text input and outputs a 3D motion corresponding to the text. While previous works have explored motion synthesis using raw motion data and latent space representations with diffusion models, these approaches often suffer from high training and inference times. In this paper, we introduce a novel framework that utilizes Generative Adversarial Networks (GANs) in the latent space to enable faster training and inference while achieving results comparable to those of the state-of-the-art diffusion methods. We perform experiments on the HumanML3D, HumanAct12 benchmarks and demonstrate that a remarkably simple GAN in the latent space achieves a FID of 0.482 with more than 91% in FLOPs reduction compared to latent diffusion model. Our work opens up new possibilities for efficient and high-quality motion synthesis using latent space GANs.
Safe to Serve: Aligning Instruction-Tuned Models for Safety and Helpfulness
Nov 26, 2024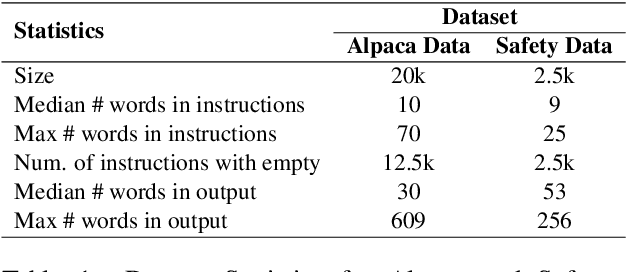
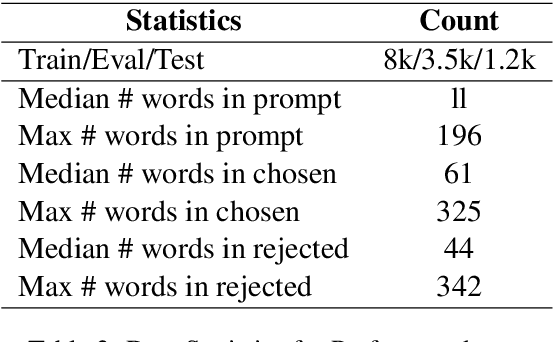
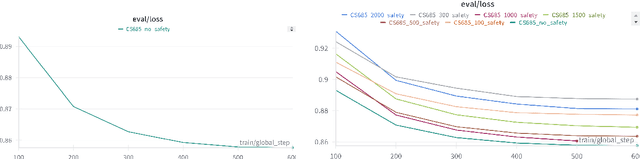
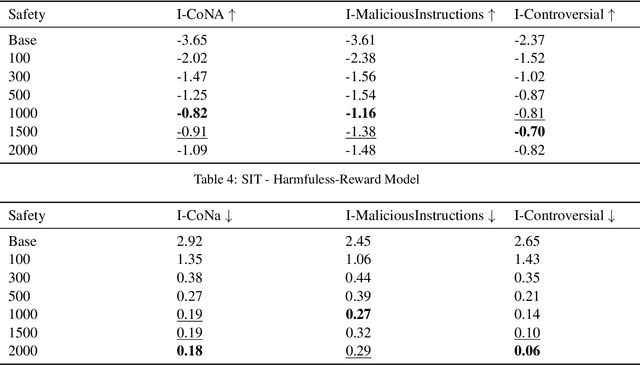
Large language models (LLMs) have demonstrated remarkable capabilities in complex reasoning and text generation. However, these models can inadvertently generate unsafe or biased responses when prompted with problematic inputs, raising significant ethical and practical concerns for real-world deployment. This research addresses the critical challenge of developing language models that generate both helpful and harmless content, navigating the delicate balance between model performance and safety. We demonstrate that incorporating safety-related instructions during the instruction-tuning of pre-trained models significantly reduces toxic responses to unsafe prompts without compromising performance on helpfulness datasets. We found Direct Preference Optimization (DPO) to be particularly effective, outperforming both SIT and RAFT by leveraging both chosen and rejected responses for learning. Our approach increased safe responses from 40$\%$ to over 90$\%$ across various harmfulness benchmarks. In addition, we discuss a rigorous evaluation framework encompassing specialized metrics and diverse datasets for safety and helpfulness tasks ensuring a comprehensive assessment of the model's capabilities.
Quasi-random Multi-Sample Inference for Large Language Models
Nov 09, 2024



Large language models (LLMs) are often equipped with multi-sample decoding strategies. An LLM implicitly defines an arithmetic code book, facilitating efficient and embarrassingly parallelizable \textbf{arithmetic sampling} to produce multiple samples using quasi-random codes. Traditional text generation methods, such as beam search and sampling-based techniques, have notable limitations: they lack parallelizability or diversity of sampled sequences. This study explores the potential of arithmetic sampling, contrasting it with ancestral sampling across two decoding tasks that employ multi-sample inference: chain-of-thought reasoning with self-consistency and machine translation with minimum Bayes risk decoding. Our results demonstrate that arithmetic sampling produces more diverse samples, significantly improving reasoning and translation performance as the sample size increases. We observe a $\mathbf{3\text{-}5\%}$ point increase in accuracy on the GSM8K dataset and a $\mathbf{0.45\text{-}0.89\%}$ point increment in COMET score for WMT19 tasks using arithmetic sampling without any significant computational overhead.
Automated Model Selection for Tabular Data
Jan 01, 2024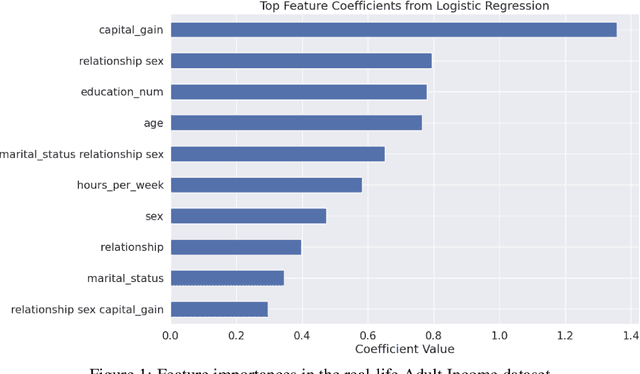

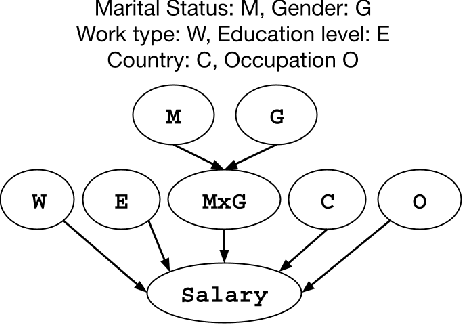
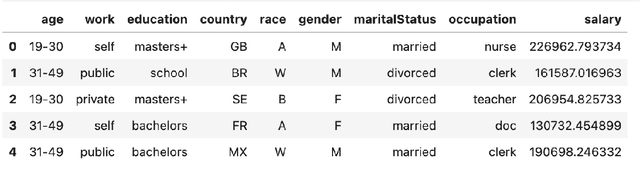
Structured data in the form of tabular datasets contain features that are distinct and discrete, with varying individual and relative importances to the target. Combinations of one or more features may be more predictive and meaningful than simple individual feature contributions. R's mixed effect linear models library allows users to provide such interactive feature combinations in the model design. However, given many features and possible interactions to select from, model selection becomes an exponentially difficult task. We aim to automate the model selection process for predictions on tabular datasets incorporating feature interactions while keeping computational costs small. The framework includes two distinct approaches for feature selection: a Priority-based Random Grid Search and a Greedy Search method. The Priority-based approach efficiently explores feature combinations using prior probabilities to guide the search. The Greedy method builds the solution iteratively by adding or removing features based on their impact. Experiments on synthetic demonstrate the ability to effectively capture predictive feature combinations.
Targeted Attacks on Timeseries Forecasting
Jan 27, 2023Real-world deep learning models developed for Time Series Forecasting are used in several critical applications ranging from medical devices to the security domain. Many previous works have shown how deep learning models are prone to adversarial attacks and studied their vulnerabilities. However, the vulnerabilities of time series models for forecasting due to adversarial inputs are not extensively explored. While the attack on a forecasting model might aim to deteriorate the performance of the model, it is more effective, if the attack is focused on a specific impact on the model's output. In this paper, we propose a novel formulation of Directional, Amplitudinal, and Temporal targeted adversarial attacks on time series forecasting models. These targeted attacks create a specific impact on the amplitude and direction of the output prediction. We use the existing adversarial attack techniques from the computer vision domain and adapt them for time series. Additionally, we propose a modified version of the Auto Projected Gradient Descent attack for targeted attacks. We examine the impact of the proposed targeted attacks versus untargeted attacks. We use KS-Tests to statistically demonstrate the impact of the attack. Our experimental results show how targeted attacks on time series models are viable and are more powerful in terms of statistical similarity. It is, hence difficult to detect through statistical methods. We believe that this work opens a new paradigm in the time series forecasting domain and represents an important consideration for developing better defenses.
Discrete Control in Real-World Driving Environments using Deep Reinforcement Learning
Nov 30, 2022Training self-driving cars is often challenging since they require a vast amount of labeled data in multiple real-world contexts, which is computationally and memory intensive. Researchers often resort to driving simulators to train the agent and transfer the knowledge to a real-world setting. Since simulators lack realistic behavior, these methods are quite inefficient. To address this issue, we introduce a framework (perception, planning, and control) in a real-world driving environment that transfers the real-world environments into gaming environments by setting up a reliable Markov Decision Process (MDP). We propose variations of existing Reinforcement Learning (RL) algorithms in a multi-agent setting to learn and execute the discrete control in real-world environments. Experiments show that the multi-agent setting outperforms the single-agent setting in all the scenarios. We also propose reliable initialization, data augmentation, and training techniques that enable the agents to learn and generalize to navigate in a real-world environment with minimal input video data, and with minimal training. Additionally, to show the efficacy of our proposed algorithm, we deploy our method in the virtual driving environment TORCS.