 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Ensuring AI Safety in DeepSeek-R1 Models: The Shortcomings of Reinforcement Learning Strategies
Jan 28, 2025Large Language Models (LLMs) have achieved remarkable progress in reasoning, alignment, and task-specific performance. However, ensuring harmlessness in these systems remains a critical challenge, particularly in advanced models like DeepSeek-R1. This paper examines the limitations of Reinforcement Learning (RL) as the primary approach for reducing harmful outputs in DeepSeek-R1 and compares it with Supervised Fine-Tuning (SFT). While RL improves reasoning capabilities, it faces challenges such as reward hacking, generalization failures, language mixing, and high computational costs. We propose hybrid training approaches combining RL and SFT to achieve robust harmlessness reduction. Usage recommendations and future directions for deploying DeepSeek-R1 responsibly are also presented.
VidModEx: Interpretable and Efficient Black Box Model Extraction for High-Dimensional Spaces
Aug 04, 2024
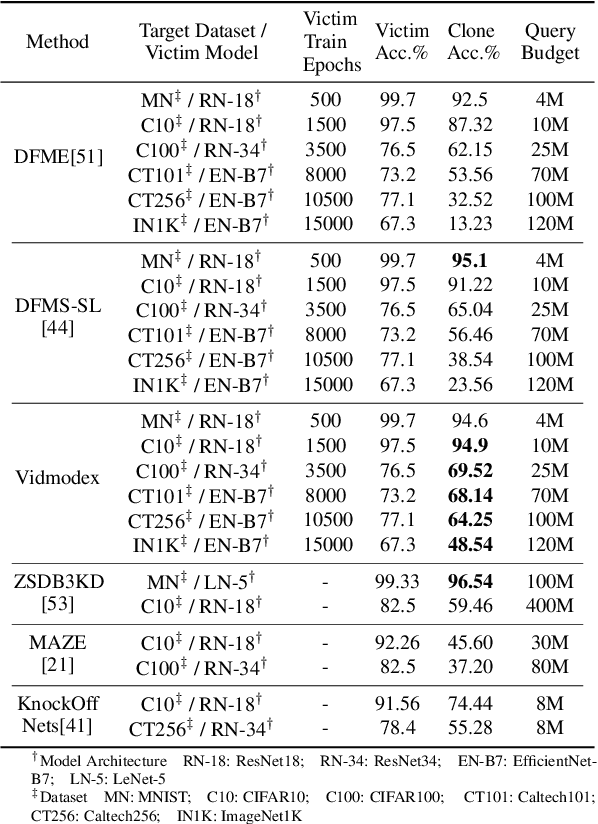

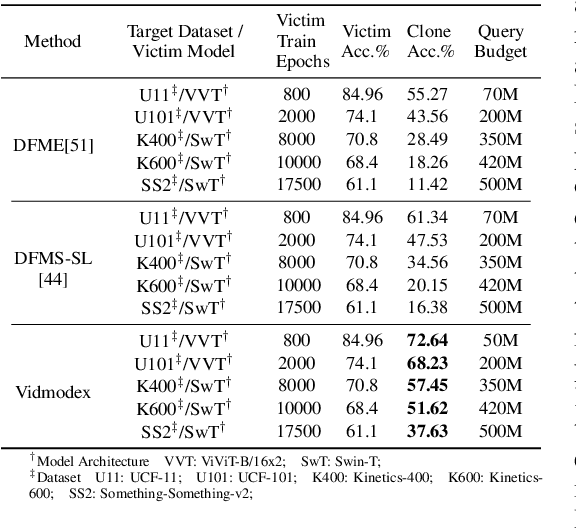
In the domain of black-box model extraction, conventional methods reliant on soft labels or surrogate datasets struggle with scaling to high-dimensional input spaces and managing the complexity of an extensive array of interrelated classes. In this work, we present a novel approach that utilizes SHAP (SHapley Additive exPlanations) to enhance synthetic data generation. SHAP quantifies the individual contributions of each input feature towards the victim model's output, facilitating the optimization of an energy-based GAN towards a desirable output. This method significantly boosts performance, achieving a 16.45% increase in the accuracy of image classification models and extending to video classification models with an average improvement of 26.11% and a maximum of 33.36% on challenging datasets such as UCF11, UCF101, Kinetics 400, Kinetics 600, and Something-Something V2. We further demonstrate the effectiveness and practical utility of our method under various scenarios, including the availability of top-k prediction probabilities, top-k prediction labels, and top-1 labels.
Enhancing TinyML Security: Study of Adversarial Attack Transferability
Jul 16, 2024



The recent strides in artificial intelligence (AI) and machine learning (ML) have propelled the rise of TinyML, a paradigm enabling AI computations at the edge without dependence on cloud connections. While TinyML offers real-time data analysis and swift responses critical for diverse applications, its devices' intrinsic resource limitations expose them to security risks. This research delves into the adversarial vulnerabilities of AI models on resource-constrained embedded hardware, with a focus on Model Extraction and Evasion Attacks. Our findings reveal that adversarial attacks from powerful host machines could be transferred to smaller, less secure devices like ESP32 and Raspberry Pi. This illustrates that adversarial attacks could be extended to tiny devices, underscoring vulnerabilities, and emphasizing the necessity for reinforced security measures in TinyML deployments. This exploration enhances the comprehension of security challenges in TinyML and offers insights for safeguarding sensitive data and ensuring device dependability in AI-powered edge computing settings.
MISLEAD: Manipulating Importance of Selected features for Learning Epsilon in Evasion Attack Deception
May 02, 2024
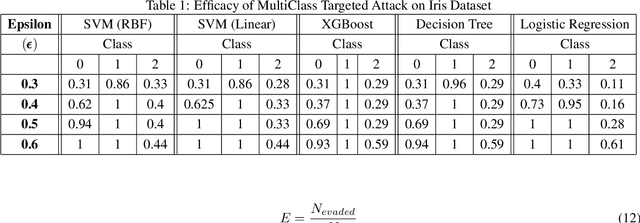

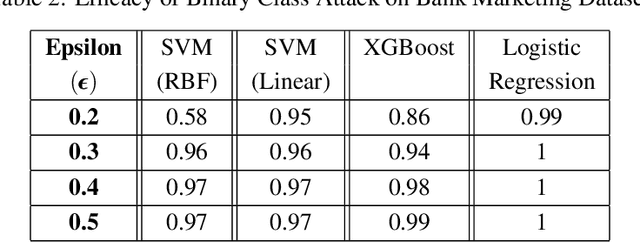
Emerging vulnerabilities in machine learning (ML) models due to adversarial attacks raise concerns about their reliability. Specifically, evasion attacks manipulate models by introducing precise perturbations to input data, causing erroneous predictions. To address this, we propose a methodology combining SHapley Additive exPlanations (SHAP) for feature importance analysis with an innovative Optimal Epsilon technique for conducting evasion attacks. Our approach begins with SHAP-based analysis to understand model vulnerabilities, crucial for devising targeted evasion strategies. The Optimal Epsilon technique, employing a Binary Search algorithm, efficiently determines the minimum epsilon needed for successful evasion. Evaluation across diverse machine learning architectures demonstrates the technique's precision in generating adversarial samples, underscoring its efficacy in manipulating model outcomes. This study emphasizes the critical importance of continuous assessment and monitoring to identify and mitigate potential security risks in machine learning systems.
On the notion of Hallucinations from the lens of Bias and Validity in Synthetic CXR Images
Dec 12, 2023Medical imaging has revolutionized disease diagnosis, yet the potential is hampered by limited access to diverse and privacy-conscious datasets. Open-source medical datasets, while valuable, suffer from data quality and clinical information disparities. Generative models, such as diffusion models, aim to mitigate these challenges. At Stanford, researchers explored the utility of a fine-tuned Stable Diffusion model (RoentGen) for medical imaging data augmentation. Our work examines specific considerations to expand the Stanford research question, Could Stable Diffusion Solve a Gap in Medical Imaging Data? from the lens of bias and validity of the generated outcomes. We leveraged RoentGen to produce synthetic Chest-XRay (CXR) images and conducted assessments on bias, validity, and hallucinations. Diagnostic accuracy was evaluated by a disease classifier, while a COVID classifier uncovered latent hallucinations. The bias analysis unveiled disparities in classification performance among various subgroups, with a pronounced impact on the Female Hispanic subgroup. Furthermore, incorporating race and gender into input prompts exacerbated fairness issues in the generated images. The quality of synthetic images exhibited variability, particularly in certain disease classes, where there was more significant uncertainty compared to the original images. Additionally, we observed latent hallucinations, with approximately 42% of the images incorrectly indicating COVID, hinting at the presence of hallucinatory elements. These identifications provide new research directions towards interpretability of synthetic CXR images, for further understanding of associated risks and patient safety in medical applications.
Data-Free Model Extraction Attacks in the Context of Object Detection
Aug 09, 2023A significant number of machine learning models are vulnerable to model extraction attacks, which focus on stealing the models by using specially curated queries against the target model. This task is well accomplished by using part of the training data or a surrogate dataset to train a new model that mimics a target model in a white-box environment. In pragmatic situations, however, the target models are trained on private datasets that are inaccessible to the adversary. The data-free model extraction technique replaces this problem when it comes to using queries artificially curated by a generator similar to that used in Generative Adversarial Nets. We propose for the first time, to the best of our knowledge, an adversary black box attack extending to a regression problem for predicting bounding box coordinates in object detection. As part of our study, we found that defining a loss function and using a novel generator setup is one of the key aspects in extracting the target model. We find that the proposed model extraction method achieves significant results by using reasonable queries. The discovery of this object detection vulnerability will support future prospects for securing such models.
Targeted Attacks on Timeseries Forecasting
Jan 27, 2023Real-world deep learning models developed for Time Series Forecasting are used in several critical applications ranging from medical devices to the security domain. Many previous works have shown how deep learning models are prone to adversarial attacks and studied their vulnerabilities. However, the vulnerabilities of time series models for forecasting due to adversarial inputs are not extensively explored. While the attack on a forecasting model might aim to deteriorate the performance of the model, it is more effective, if the attack is focused on a specific impact on the model's output. In this paper, we propose a novel formulation of Directional, Amplitudinal, and Temporal targeted adversarial attacks on time series forecasting models. These targeted attacks create a specific impact on the amplitude and direction of the output prediction. We use the existing adversarial attack techniques from the computer vision domain and adapt them for time series. Additionally, we propose a modified version of the Auto Projected Gradient Descent attack for targeted attacks. We examine the impact of the proposed targeted attacks versus untargeted attacks. We use KS-Tests to statistically demonstrate the impact of the attack. Our experimental results show how targeted attacks on time series models are viable and are more powerful in terms of statistical similarity. It is, hence difficult to detect through statistical methods. We believe that this work opens a new paradigm in the time series forecasting domain and represents an important consideration for developing better defenses.
Critical Checkpoints for Evaluating Defence Models Against Adversarial Attack and Robustness
Feb 18, 2022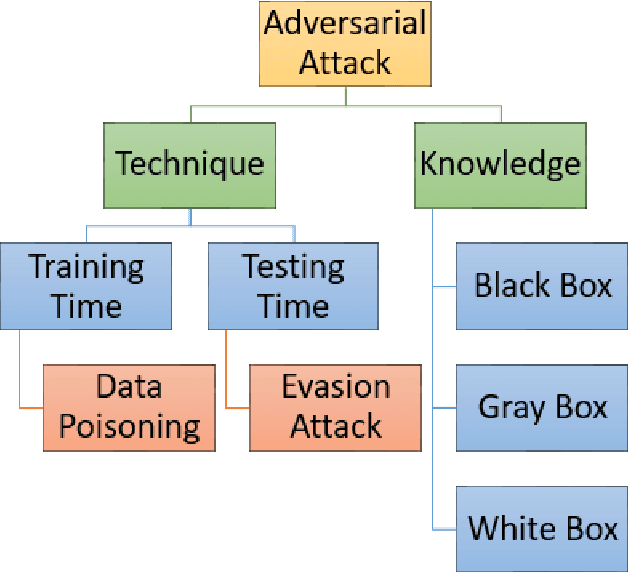
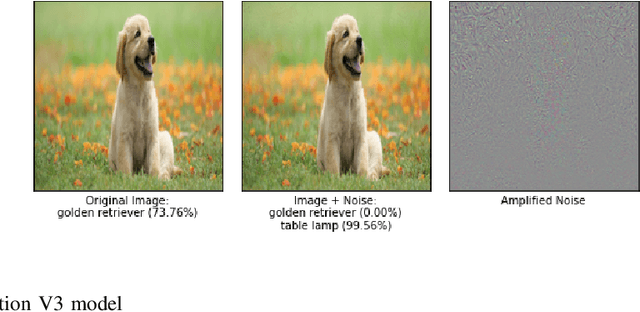

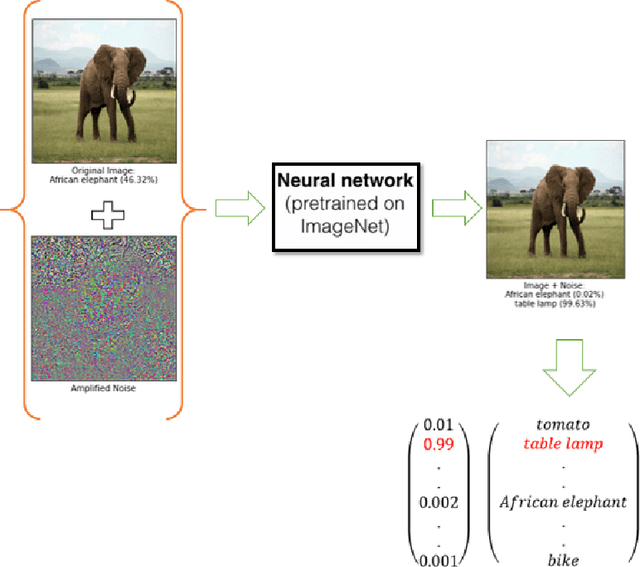
From past couple of years there is a cycle of researchers proposing a defence model for adversaries in machine learning which is arguably defensible to most of the existing attacks in restricted condition (they evaluate on some bounded inputs or datasets). And then shortly another set of researcher finding the vulnerabilities in that defence model and breaking it by proposing a stronger attack model. Some common flaws are been noticed in the past defence models that were broken in very short time. Defence models being broken so easily is a point of concern as decision of many crucial activities are taken with the help of machine learning models. So there is an utter need of some defence checkpoints that any researcher should keep in mind while evaluating the soundness of technique and declaring it to be decent defence technique. In this paper, we have suggested few checkpoints that should be taken into consideration while building and evaluating the soundness of defence models. All these points are recommended after observing why some past defence models failed and how some model remained adamant and proved their soundness against some of the very strong attacks.
Emerging AI Security Threats for Autonomous Cars -- Case Studies
Sep 10, 2021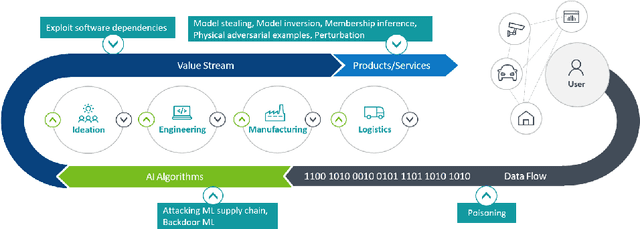
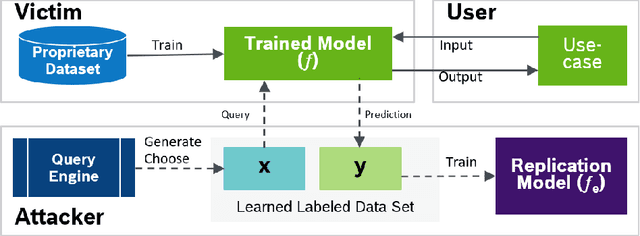
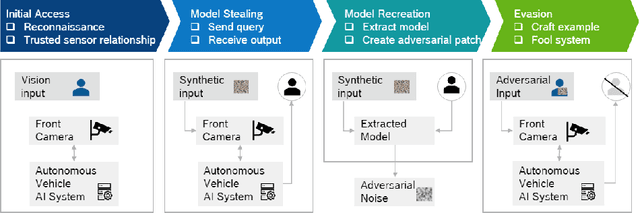
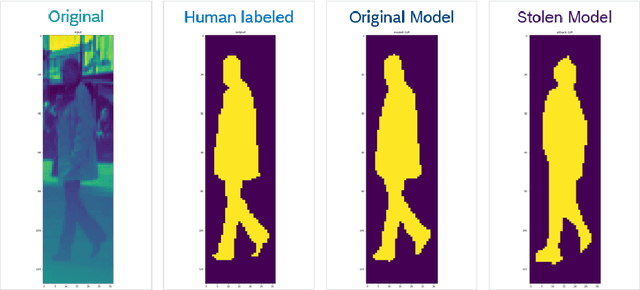
Artificial Intelligence has made a significant contribution to autonomous vehicles, from object detection to path planning. However, AI models require a large amount of sensitive training data and are usually computationally intensive to build. The commercial value of such models motivates attackers to mount various attacks. Adversaries can launch model extraction attacks for monetization purposes or step-ping-stone towards other attacks like model evasion. In specific cases, it even results in destroying brand reputation, differentiation, and value proposition. In addition, IP laws and AI-related legalities are still evolving and are not uniform across countries. We discuss model extraction attacks in detail with two use-cases and a generic kill-chain that can compromise autonomous cars. It is essential to investigate strategies to manage and mitigate the risk of model theft.
Mapping of Real World Problems to Nature Inspired Algorithm using Goal based Classification and TRIZ
Oct 08, 2020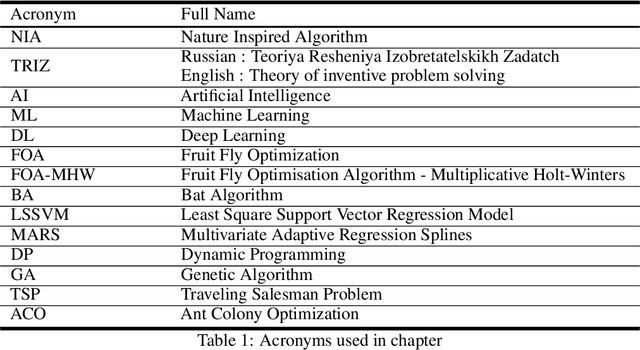
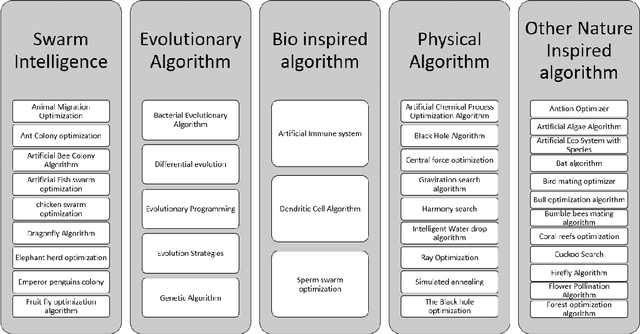
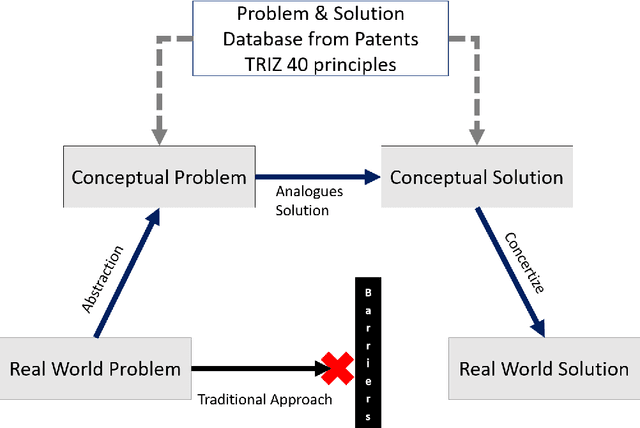
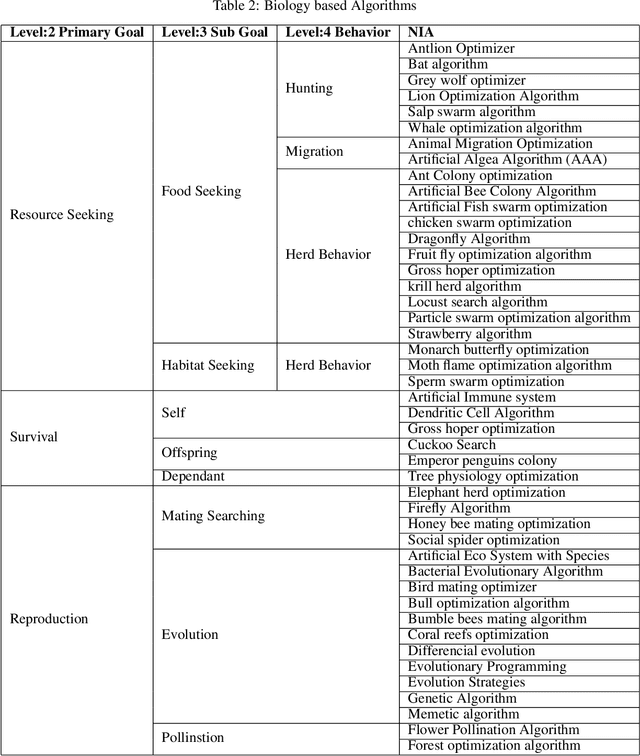
The technologies and algorithms are growing at an exponential rate. The technologies are capable enough to solve technically challenging and complex problems which seemed impossible task. However, the trending methods and approaches are facing multiple challenges on various fronts of data, algorithms, software, computational complexities, and energy efficiencies. Nature also faces similar challenges. Nature has solved those challenges and formulation of those are available as Nature Inspired Algorithms (NIA), which are derived based on the study of nature. A novel method based on TRIZ to map the real-world problems to nature problems is explained here.TRIZ is a Theory of inventive problem solving. Using the proposed framework, best NIA can be identified to solve the real-world problems. For this framework to work, a novel classification of NIA based on the end goal that nature is trying to achieve is devised. The application of the this framework along with examples is also discussed.