 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLS-GAN: Human Motion Synthesis with Latent-space GANs
Dec 30, 2024



Human motion synthesis conditioned on textual input has gained significant attention in recent years due to its potential applications in various domains such as gaming, film production, and virtual reality. Conditioned Motion synthesis takes a text input and outputs a 3D motion corresponding to the text. While previous works have explored motion synthesis using raw motion data and latent space representations with diffusion models, these approaches often suffer from high training and inference times. In this paper, we introduce a novel framework that utilizes Generative Adversarial Networks (GANs) in the latent space to enable faster training and inference while achieving results comparable to those of the state-of-the-art diffusion methods. We perform experiments on the HumanML3D, HumanAct12 benchmarks and demonstrate that a remarkably simple GAN in the latent space achieves a FID of 0.482 with more than 91% in FLOPs reduction compared to latent diffusion model. Our work opens up new possibilities for efficient and high-quality motion synthesis using latent space GANs.
Safe to Serve: Aligning Instruction-Tuned Models for Safety and Helpfulness
Nov 26, 2024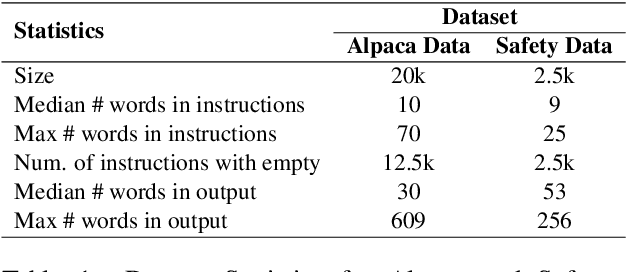
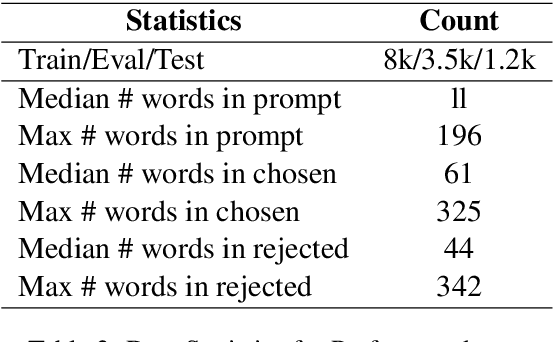
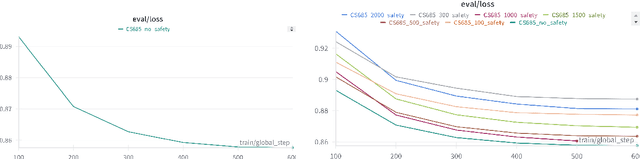
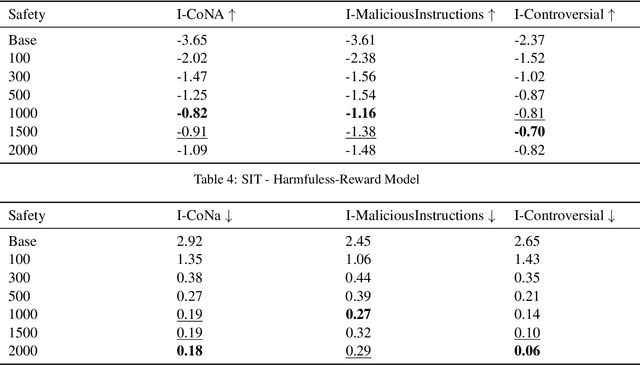
Large language models (LLMs) have demonstrated remarkable capabilities in complex reasoning and text generation. However, these models can inadvertently generate unsafe or biased responses when prompted with problematic inputs, raising significant ethical and practical concerns for real-world deployment. This research addresses the critical challenge of developing language models that generate both helpful and harmless content, navigating the delicate balance between model performance and safety. We demonstrate that incorporating safety-related instructions during the instruction-tuning of pre-trained models significantly reduces toxic responses to unsafe prompts without compromising performance on helpfulness datasets. We found Direct Preference Optimization (DPO) to be particularly effective, outperforming both SIT and RAFT by leveraging both chosen and rejected responses for learning. Our approach increased safe responses from 40$\%$ to over 90$\%$ across various harmfulness benchmarks. In addition, we discuss a rigorous evaluation framework encompassing specialized metrics and diverse datasets for safety and helpfulness tasks ensuring a comprehensive assessment of the model's capabilities.
Automated Model Selection for Tabular Data
Jan 01, 2024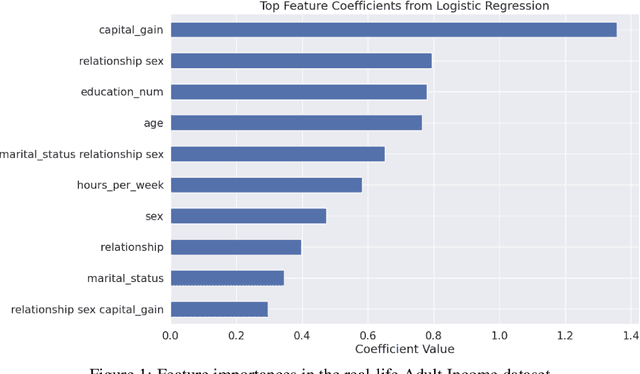

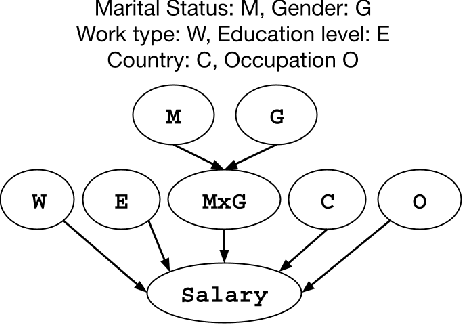
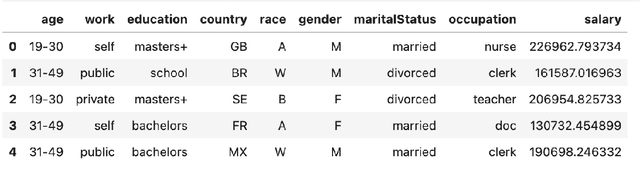
Structured data in the form of tabular datasets contain features that are distinct and discrete, with varying individual and relative importances to the target. Combinations of one or more features may be more predictive and meaningful than simple individual feature contributions. R's mixed effect linear models library allows users to provide such interactive feature combinations in the model design. However, given many features and possible interactions to select from, model selection becomes an exponentially difficult task. We aim to automate the model selection process for predictions on tabular datasets incorporating feature interactions while keeping computational costs small. The framework includes two distinct approaches for feature selection: a Priority-based Random Grid Search and a Greedy Search method. The Priority-based approach efficiently explores feature combinations using prior probabilities to guide the search. The Greedy method builds the solution iteratively by adding or removing features based on their impact. Experiments on synthetic demonstrate the ability to effectively capture predictive feature combinations.