 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
Jun 14, 2025



Robust unlearning is crucial for safely deploying large language models (LLMs) in environments where data privacy, model safety, and regulatory compliance must be ensured. Yet the task is inherently challenging, partly due to difficulties in reliably measuring whether unlearning has truly occurred. Moreover, fragmentation in current methodologies and inconsistent evaluation metrics hinder comparative analysis and reproducibility. To unify and accelerate research efforts, we introduce OpenUnlearning, a standardized and extensible framework designed explicitly for benchmarking both LLM unlearning methods and metrics. OpenUnlearning integrates 9 unlearning algorithms and 16 diverse evaluations across 3 leading benchmarks (TOFU, MUSE, and WMDP) and also enables analyses of forgetting behaviors across 450+ checkpoints we publicly release. Leveraging OpenUnlearning, we propose a novel meta-evaluation benchmark focused specifically on assessing the faithfulness and robustness of evaluation metrics themselves. We also benchmark diverse unlearning methods and provide a comparative analysis against an extensive evaluation suite. Overall, we establish a clear, community-driven pathway toward rigorous development in LLM unlearning research.
Does quantization affect models' performance on long-context tasks?
May 27, 2025
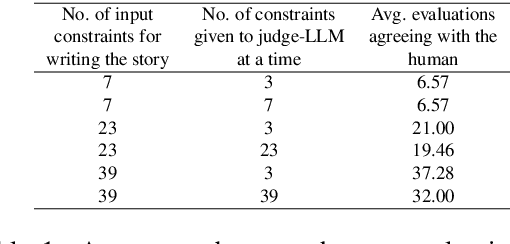


Large language models (LLMs) now support context windows exceeding 128K tokens, but this comes with significant memory requirements and high inference latency. Quantization can mitigate these costs, but may degrade performance. In this work, we present the first systematic evaluation of quantized LLMs on tasks with long-inputs (>64K tokens) and long-form outputs. Our evaluation spans 9.7K test examples, five quantization methods (FP8, GPTQ-int8, AWQ-int4, GPTQ-int4, BNB-nf4), and five models (Llama-3.1 8B and 70B; Qwen-2.5 7B, 32B, and 72B). We find that, on average, 8-bit quantization preserves accuracy (~0.8% drop), whereas 4-bit methods lead to substantial losses, especially for tasks involving long context inputs (drops of up to 59%). This degradation tends to worsen when the input is in a language other than English. Crucially, the effects of quantization depend heavily on the quantization method, model, and task. For instance, while Qwen-2.5 72B remains robust under BNB-nf4, Llama-3.1 70B experiences a 32% performance drop on the same task. These findings highlight the importance of a careful, task-specific evaluation before deploying quantized LLMs, particularly in long-context scenarios and with languages other than English.
Automated Model Selection for Tabular Data
Jan 01, 2024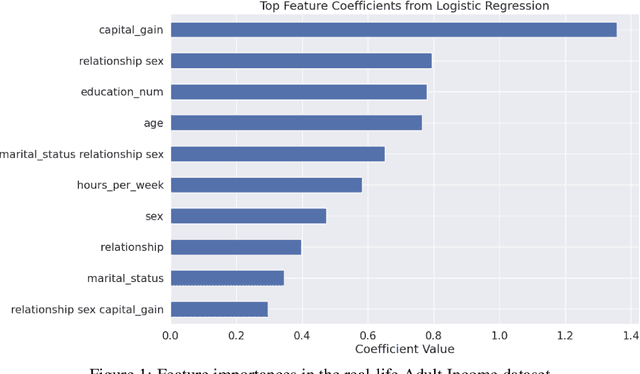

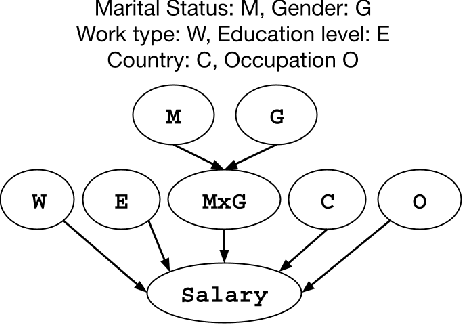
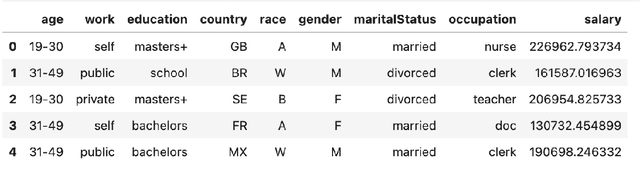
Structured data in the form of tabular datasets contain features that are distinct and discrete, with varying individual and relative importances to the target. Combinations of one or more features may be more predictive and meaningful than simple individual feature contributions. R's mixed effect linear models library allows users to provide such interactive feature combinations in the model design. However, given many features and possible interactions to select from, model selection becomes an exponentially difficult task. We aim to automate the model selection process for predictions on tabular datasets incorporating feature interactions while keeping computational costs small. The framework includes two distinct approaches for feature selection: a Priority-based Random Grid Search and a Greedy Search method. The Priority-based approach efficiently explores feature combinations using prior probabilities to guide the search. The Greedy method builds the solution iteratively by adding or removing features based on their impact. Experiments on synthetic demonstrate the ability to effectively capture predictive feature combinations.
Using Early Readouts to Mediate Featural Bias in Distillation
Oct 28, 2023Deep networks tend to learn spurious feature-label correlations in real-world supervised learning tasks. This vulnerability is aggravated in distillation, where a student model may have lesser representational capacity than the corresponding teacher model. Often, knowledge of specific spurious correlations is used to reweight instances & rebalance the learning process. We propose a novel early readout mechanism whereby we attempt to predict the label using representations from earlier network layers. We show that these early readouts automatically identify problem instances or groups in the form of confident, incorrect predictions. Leveraging these signals to modulate the distillation loss on an instance level allows us to substantially improve not only group fairness measures across benchmark datasets, but also overall accuracy of the student model. We also provide secondary analyses that bring insight into the role of feature learning in supervision and distillation.