 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes quantization affect models' performance on long-context tasks?
May 27, 2025Large language models (LLMs) now support context windows exceeding 128K tokens, but this comes with significant memory requirements and high inference latency. Quantization can mitigate these costs, but may degrade performance. In this work, we present the first systematic evaluation of quantized LLMs on tasks with long-inputs (>64K tokens) and long-form outputs. Our evaluation spans 9.7K test examples, five quantization methods (FP8, GPTQ-int8, AWQ-int4, GPTQ-int4, BNB-nf4), and five models (Llama-3.1 8B and 70B; Qwen-2.5 7B, 32B, and 72B). We find that, on average, 8-bit quantization preserves accuracy (~0.8% drop), whereas 4-bit methods lead to substantial losses, especially for tasks involving long context inputs (drops of up to 59%). This degradation tends to worsen when the input is in a language other than English. Crucially, the effects of quantization depend heavily on the quantization method, model, and task. For instance, while Qwen-2.5 72B remains robust under BNB-nf4, Llama-3.1 70B experiences a 32% performance drop on the same task. These findings highlight the importance of a careful, task-specific evaluation before deploying quantized LLMs, particularly in long-context scenarios and with languages other than English.
CS4: Measuring the Creativity of Large Language Models Automatically by Controlling the Number of Story-Writing Constraints
Oct 05, 2024
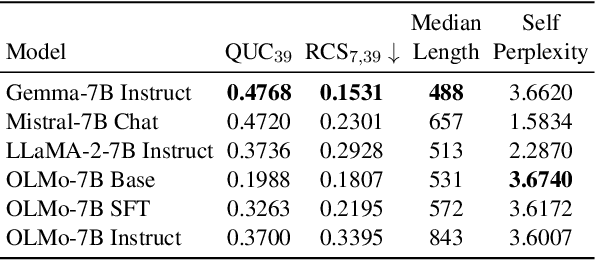

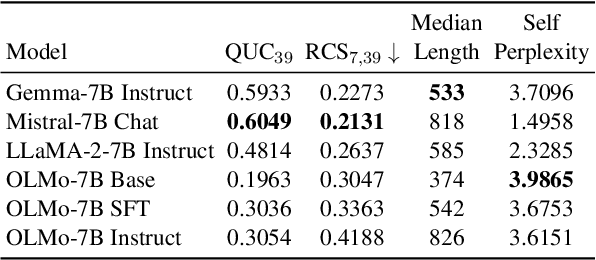
Evaluating the creativity of large language models (LLMs) in story writing is difficult because LLM-generated stories could seemingly look creative but be very similar to some existing stories in their huge and proprietary training corpus. To overcome this challenge, we introduce a novel benchmark dataset with varying levels of prompt specificity: CS4 ($\mathbf{C}$omparing the $\mathbf{S}$kill of $\mathbf{C}$reating $\mathbf{S}$tories by $\mathbf{C}$ontrolling the $\mathbf{S}$ynthesized $\mathbf{C}$onstraint $\mathbf{S}$pecificity). By increasing the number of requirements/constraints in the prompt, we can increase the prompt specificity and hinder LLMs from retelling high-quality narratives in their training data. Consequently, CS4 empowers us to indirectly measure the LLMs' creativity without human annotations. Our experiments on LLaMA, Gemma, and Mistral not only highlight the creativity challenges LLMs face when dealing with highly specific prompts but also reveal that different LLMs perform very differently under different numbers of constraints and achieve different balances between the model's instruction-following ability and narrative coherence. Additionally, our experiments on OLMo suggest that Learning from Human Feedback (LHF) can help LLMs select better stories from their training data but has limited influence in boosting LLMs' ability to produce creative stories that are unseen in the training corpora. The benchmark is released at https://github.com/anirudhlakkaraju/cs4_benchmark.