 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS4: Measuring the Creativity of Large Language Models Automatically by Controlling the Number of Story-Writing Constraints
Paper and Code

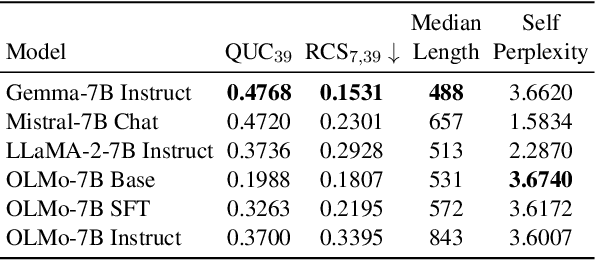

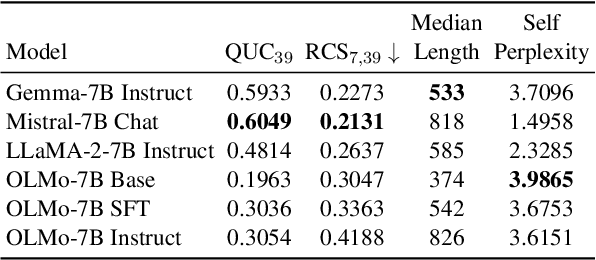
Evaluating the creativity of large language models (LLMs) in story writing is difficult because LLM-generated stories could seemingly look creative but be very similar to some existing stories in their huge and proprietary training corpus. To overcome this challenge, we introduce a novel benchmark dataset with varying levels of prompt specificity: CS4 ($\mathbf{C}$omparing the $\mathbf{S}$kill of $\mathbf{C}$reating $\mathbf{S}$tories by $\mathbf{C}$ontrolling the $\mathbf{S}$ynthesized $\mathbf{C}$onstraint $\mathbf{S}$pecificity). By increasing the number of requirements/constraints in the prompt, we can increase the prompt specificity and hinder LLMs from retelling high-quality narratives in their training data. Consequently, CS4 empowers us to indirectly measure the LLMs' creativity without human annotations. Our experiments on LLaMA, Gemma, and Mistral not only highlight the creativity challenges LLMs face when dealing with highly specific prompts but also reveal that different LLMs perform very differently under different numbers of constraints and achieve different balances between the model's instruction-following ability and narrative coherence. Additionally, our experiments on OLMo suggest that Learning from Human Feedback (LHF) can help LLMs select better stories from their training data but has limited influence in boosting LLMs' ability to produce creative stories that are unseen in the training corpora. The benchmark is released at https://github.com/anirudhlakkaraju/cs4_benchmark.