 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Characterizing Planning in Language Models
Aug 25, 2025Modern large language models (LLMs) have demonstrated impressive performance across a wide range of multi-step reasoning tasks. Recent work suggests that LLMs may perform planning - selecting a future target token in advance and generating intermediate tokens that lead towards it - rather than merely improvising one token at a time. However, existing studies assume fixed planning horizons and often focus on single prompts or narrow domains. To distinguish planning from improvisation across models and tasks, we present formal and causally grounded criteria for detecting planning and operationalize them as a semi-automated annotation pipeline. We apply this pipeline to both base and instruction-tuned Gemma-2-2B models on the MBPP code generation benchmark and a poem generation task where Claude 3.5 Haiku was previously shown to plan. Our findings show that planning is not universal: unlike Haiku, Gemma-2-2B solves the same poem generation task through improvisation, and on MBPP it switches between planning and improvisation across similar tasks and even successive token predictions. We further show that instruction tuning refines existing planning behaviors in the base model rather than creating them from scratch. Together, these studies provide a reproducible and scalable foundation for mechanistic studies of planning in LLMs.
Timing Analysis Agent: Autonomous Multi-Corner Multi-Mode (MCMM) Timing Debugging with Timing Debug Relation Graph
Apr 15, 2025Timing analysis is an essential and demanding verification method for Very Large Scale Integrated (VLSI) circuit design and optimization. In addition, it also serves as the cornerstone of the final sign-off, determining whether the chip is ready to be sent to the semiconductor foundry for fabrication. Recently, as the technology advance relentlessly, smaller metal pitches and the increasing number of devices have led to greater challenges and longer turn-around-time for experienced human designers to debug timing issues from the Multi-Corner Multi-Mode (MCMM) timing reports. As a result, an efficient and intelligent methodology is highly necessary and essential for debugging timing issues and reduce the turnaround times. Recently, Large Language Models (LLMs) have shown great promise across various tasks in language understanding and interactive decision-making, incorporating reasoning and actions. In this work, we propose a timing analysis agent, that is empowered by multi-LLMs task solving, and incorporates a novel hierarchical planning and solving flow to automate the analysis of timing reports from commercial tool. In addition, we build a Timing Debug Relation Graph (TDRG) that connects the reports with the relationships of debug traces from experienced timing engineers. The timing analysis agent employs the novel Agentic Retrieval Augmented Generation (RAG) approach, that includes agent and coding to retrieve data accurately, on the developed TDRG. In our studies, the proposed timing analysis agent achieves an average 98% pass-rate on a single-report benchmark and a 90% pass-rate for multi-report benchmark from industrial designs, demonstrating its effectiveness and adaptability.
Adaptive Circuit Behavior and Generalization in Mechanistic Interpretability
Nov 25, 2024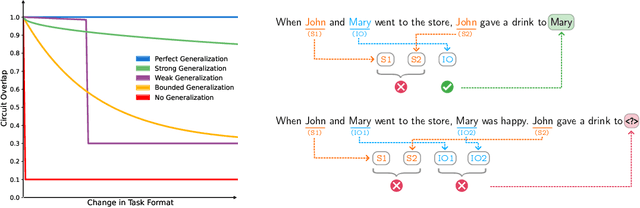

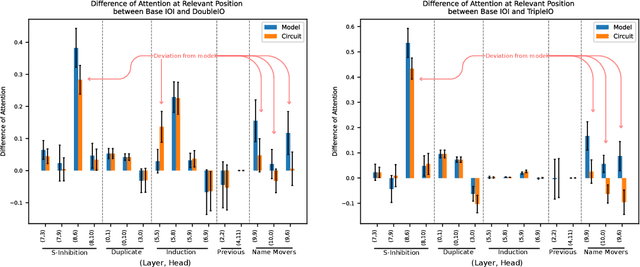
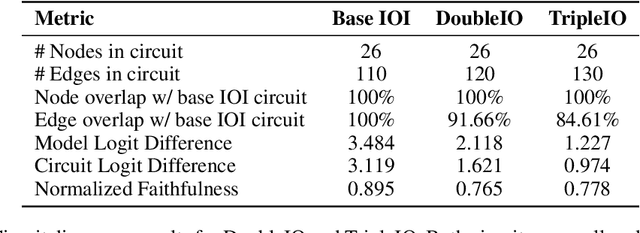
Mechanistic interpretability aims to understand the inner workings of large neural networks by identifying circuits, or minimal subgraphs within the model that implement algorithms responsible for performing specific tasks. These circuits are typically discovered and analyzed using a narrowly defined prompt format. However, given the abilities of large language models (LLMs) to generalize across various prompt formats for the same task, it remains unclear how well these circuits generalize. For instance, it is unclear whether the models generalization results from reusing the same circuit components, the components behaving differently, or the use of entirely different components. In this paper, we investigate the generality of the indirect object identification (IOI) circuit in GPT-2 small, which is well-studied and believed to implement a simple, interpretable algorithm. We evaluate its performance on prompt variants that challenge the assumptions of this algorithm. Our findings reveal that the circuit generalizes surprisingly well, reusing all of its components and mechanisms while only adding additional input edges. Notably, the circuit generalizes even to prompt variants where the original algorithm should fail; we discover a mechanism that explains this which we term S2 Hacking. Our findings indicate that circuits within LLMs may be more flexible and general than previously recognized, underscoring the importance of studying circuit generalization to better understand the broader capabilities of these models.
CS4: Measuring the Creativity of Large Language Models Automatically by Controlling the Number of Story-Writing Constraints
Oct 05, 2024
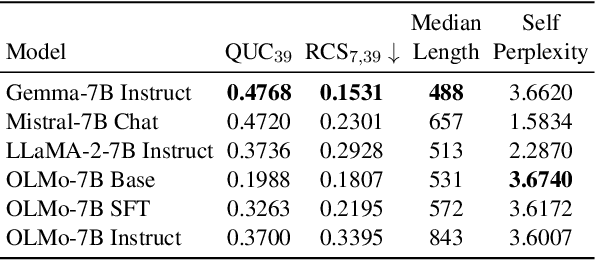

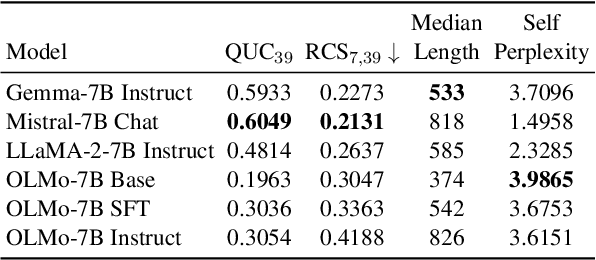
Evaluating the creativity of large language models (LLMs) in story writing is difficult because LLM-generated stories could seemingly look creative but be very similar to some existing stories in their huge and proprietary training corpus. To overcome this challenge, we introduce a novel benchmark dataset with varying levels of prompt specificity: CS4 ($\mathbf{C}$omparing the $\mathbf{S}$kill of $\mathbf{C}$reating $\mathbf{S}$tories by $\mathbf{C}$ontrolling the $\mathbf{S}$ynthesized $\mathbf{C}$onstraint $\mathbf{S}$pecificity). By increasing the number of requirements/constraints in the prompt, we can increase the prompt specificity and hinder LLMs from retelling high-quality narratives in their training data. Consequently, CS4 empowers us to indirectly measure the LLMs' creativity without human annotations. Our experiments on LLaMA, Gemma, and Mistral not only highlight the creativity challenges LLMs face when dealing with highly specific prompts but also reveal that different LLMs perform very differently under different numbers of constraints and achieve different balances between the model's instruction-following ability and narrative coherence. Additionally, our experiments on OLMo suggest that Learning from Human Feedback (LHF) can help LLMs select better stories from their training data but has limited influence in boosting LLMs' ability to produce creative stories that are unseen in the training corpora. The benchmark is released at https://github.com/anirudhlakkaraju/cs4_benchmark.
Evaluating Brain-Inspired Modular Training in Automated Circuit Discovery for Mechanistic Interpretability
Jan 08, 2024Large Language Models (LLMs) have experienced a rapid rise in AI, changing a wide range of applications with their advanced capabilities. As these models become increasingly integral to decision-making, the need for thorough interpretability has never been more critical. Mechanistic Interpretability offers a pathway to this understanding by identifying and analyzing specific sub-networks or 'circuits' within these complex systems. A crucial aspect of this approach is Automated Circuit Discovery, which facilitates the study of large models like GPT4 or LLAMA in a feasible manner. In this context, our research evaluates a recent method, Brain-Inspired Modular Training (BIMT), designed to enhance the interpretability of neural networks. We demonstrate how BIMT significantly improves the efficiency and quality of Automated Circuit Discovery, overcoming the limitations of manual methods. Our comparative analysis further reveals that BIMT outperforms existing models in terms of circuit quality, discovery time, and sparsity. Additionally, we provide a comprehensive computational analysis of BIMT, including aspects such as training duration, memory allocation requirements, and inference speed. This study advances the larger objective of creating trustworthy and transparent AI systems in addition to demonstrating how well BIMT works to make neural networks easier to understand.
ZeroSearch: Local Image Search from Text with Zero Shot Learning
May 01, 2023The problem of organizing and finding images in a user's directory has become increasingly challenging due to the rapid growth in the number of images captured on personal devices. This paper presents a solution that utilizes zero shot learning to create image queries with only user provided text descriptions. The paper's primary contribution is the development of an algorithm that utilizes pre-trained models to extract features from images. The algorithm uses OWL to check for the presence of bounding boxes and sorts images based on cosine similarity scores. The algorithm's output is a list of images sorted in descending order of similarity, helping users to locate specific images more efficiently. The paper's experiments were conducted using a custom dataset to simulate a user's image directory and evaluated the accuracy, inference time, and size of the models. The results showed that the VGG model achieved the highest accuracy, while the Resnet50 and InceptionV3 models had the lowest inference time and size. The papers proposed algorithm provides an effective and efficient solution for organizing and finding images in a users local directory. The algorithm's performance and flexibility make it suitable for various applications, including personal image organization and search engines. Code and dataset for zero-search are available at: https://github.com/NainaniJatinZ/zero-search
Feature-Rich Long-term Bitcoin Trading Assistant
Sep 14, 2022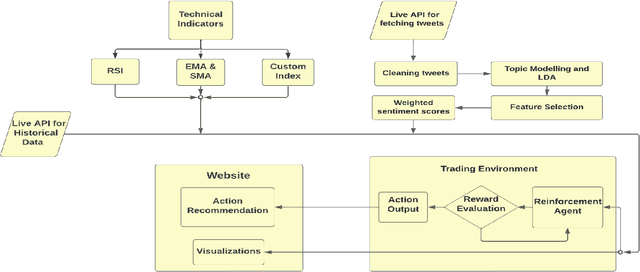
For a long time predicting, studying and analyzing financial indices has been of major interest for the financial community. Recently, there has been a growing interest in the Deep-Learning community to make use of reinforcement learning which has surpassed many of the previous benchmarks in a lot of fields. Our method provides a feature rich environment for the reinforcement learning agent to work on. The aim is to provide long term profits to the user so, we took into consideration the most reliable technical indicators. We have also developed a custom indicator which would provide better insights of the Bitcoin market to the user. The Bitcoin market follows the emotions and sentiments of the traders, so another element of our trading environment is the overall daily Sentiment Score of the market on Twitter. The agent is tested for a period of 685 days which also included the volatile period of Covid-19. It has been capable of providing reliable recommendations which give an average profit of about 69%. Finally, the agent is also capable of suggesting the optimal actions to the user through a website. Users on the website can also access the visualizations of the indicators to help fortify their decisions.