 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Characterizing Planning in Language Models
Aug 25, 2025Modern large language models (LLMs) have demonstrated impressive performance across a wide range of multi-step reasoning tasks. Recent work suggests that LLMs may perform planning - selecting a future target token in advance and generating intermediate tokens that lead towards it - rather than merely improvising one token at a time. However, existing studies assume fixed planning horizons and often focus on single prompts or narrow domains. To distinguish planning from improvisation across models and tasks, we present formal and causally grounded criteria for detecting planning and operationalize them as a semi-automated annotation pipeline. We apply this pipeline to both base and instruction-tuned Gemma-2-2B models on the MBPP code generation benchmark and a poem generation task where Claude 3.5 Haiku was previously shown to plan. Our findings show that planning is not universal: unlike Haiku, Gemma-2-2B solves the same poem generation task through improvisation, and on MBPP it switches between planning and improvisation across similar tasks and even successive token predictions. We further show that instruction tuning refines existing planning behaviors in the base model rather than creating them from scratch. Together, these studies provide a reproducible and scalable foundation for mechanistic studies of planning in LLMs.
Adaptive Circuit Behavior and Generalization in Mechanistic Interpretability
Nov 25, 2024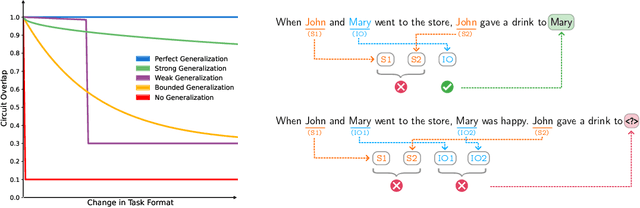

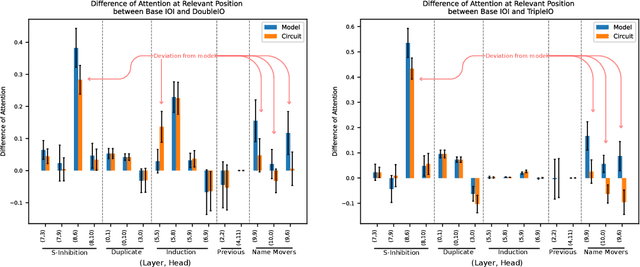
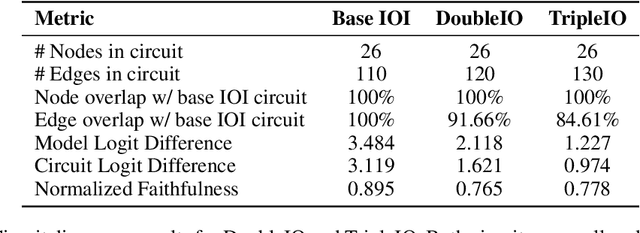
Mechanistic interpretability aims to understand the inner workings of large neural networks by identifying circuits, or minimal subgraphs within the model that implement algorithms responsible for performing specific tasks. These circuits are typically discovered and analyzed using a narrowly defined prompt format. However, given the abilities of large language models (LLMs) to generalize across various prompt formats for the same task, it remains unclear how well these circuits generalize. For instance, it is unclear whether the models generalization results from reusing the same circuit components, the components behaving differently, or the use of entirely different components. In this paper, we investigate the generality of the indirect object identification (IOI) circuit in GPT-2 small, which is well-studied and believed to implement a simple, interpretable algorithm. We evaluate its performance on prompt variants that challenge the assumptions of this algorithm. Our findings reveal that the circuit generalizes surprisingly well, reusing all of its components and mechanisms while only adding additional input edges. Notably, the circuit generalizes even to prompt variants where the original algorithm should fail; we discover a mechanism that explains this which we term S2 Hacking. Our findings indicate that circuits within LLMs may be more flexible and general than previously recognized, underscoring the importance of studying circuit generalization to better understand the broader capabilities of these models.
Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Jun 18, 2024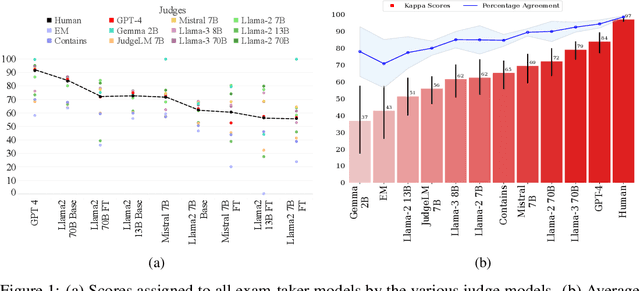

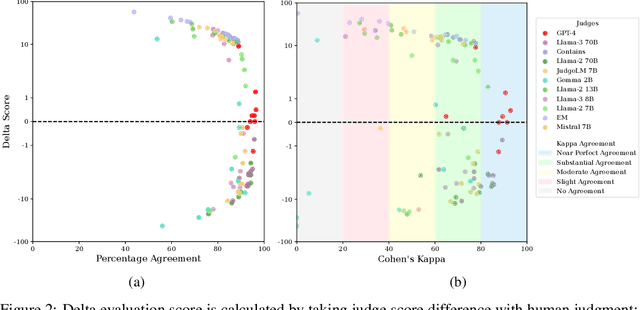

Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges. We leverage TriviaQA as a benchmark for assessing objective knowledge reasoning of LLMs and evaluate them alongside human annotations which we found to have a high inter-annotator agreement. Our study includes 9 judge models and 9 exam taker models -- both base and instruction-tuned. We assess the judge model's alignment across different model sizes, families, and judge prompts. Among other results, our research rediscovers the importance of using Cohen's kappa as a metric of alignment as opposed to simple percent agreement, showing that judges with high percent agreement can still assign vastly different scores. We find that both Llama-3 70B and GPT-4 Turbo have an excellent alignment with humans, but in terms of ranking exam taker models, they are outperformed by both JudgeLM-7B and the lexical judge Contains, which have up to 34 points lower human alignment. Through error analysis and various other studies, including the effects of instruction length and leniency bias, we hope to provide valuable lessons for using LLMs as judges in the future.
Automated Discovery of Functional Actual Causes in Complex Environments
Apr 16, 2024



Reinforcement learning (RL) algorithms often struggle to learn policies that generalize to novel situations due to issues such as causal confusion, overfitting to irrelevant factors, and failure to isolate control of state factors. These issues stem from a common source: a failure to accurately identify and exploit state-specific causal relationships in the environment. While some prior works in RL aim to identify these relationships explicitly, they rely on informal domain-specific heuristics such as spatial and temporal proximity. Actual causality offers a principled and general framework for determining the causes of particular events. However, existing definitions of actual cause often attribute causality to a large number of events, even if many of them rarely influence the outcome. Prior work on actual causality proposes normality as a solution to this problem, but its existing implementations are challenging to scale to complex and continuous-valued RL environments. This paper introduces functional actual cause (FAC), a framework that uses context-specific independencies in the environment to restrict the set of actual causes. We additionally introduce Joint Optimization for Actual Cause Inference (JACI), an algorithm that learns from observational data to infer functional actual causes. We demonstrate empirically that FAC agrees with known results on a suite of examples from the actual causality literature, and JACI identifies actual causes with significantly higher accuracy than existing heuristic methods in a set of complex, continuous-valued environments.
Hypergraph Clustering: A Modularity Maximization Approach
Dec 28, 2018

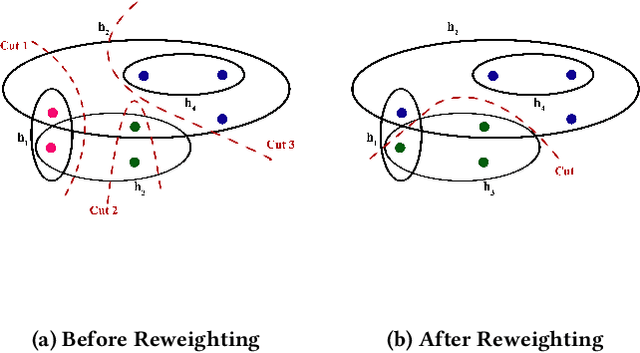
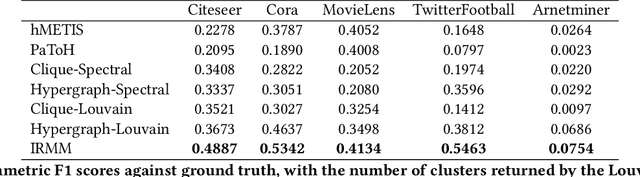
Clustering on hypergraphs has been garnering increased attention with potential applications in network analysis, VLSI design and computer vision, among others. In this work, we generalize the framework of modularity maximization for clustering on hypergraphs. To this end, we introduce a hypergraph null model, analogous to the configuration model on undirected graphs, and a node-degree preserving reduction to work with this model. This is used to define a modularity function that can be maximized using the popular and fast Louvain algorithm. We additionally propose a refinement over this clustering, by reweighting cut hyperedges in an iterative fashion. The efficacy and efficiency of our methods are demonstrated on several real-world datasets.