 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Circuit Behavior and Generalization in Mechanistic Interpretability
Nov 25, 2024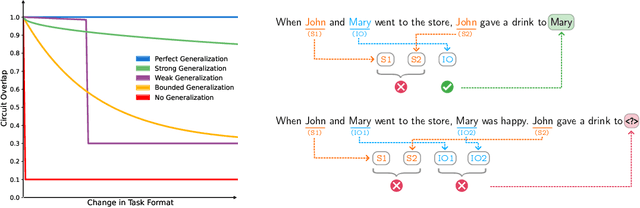

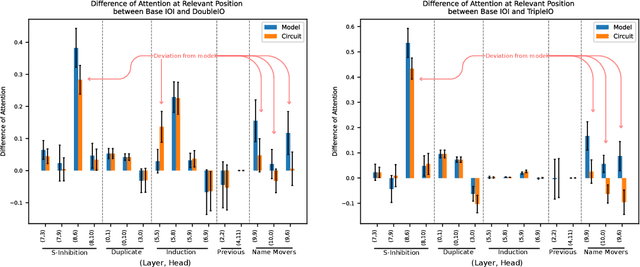
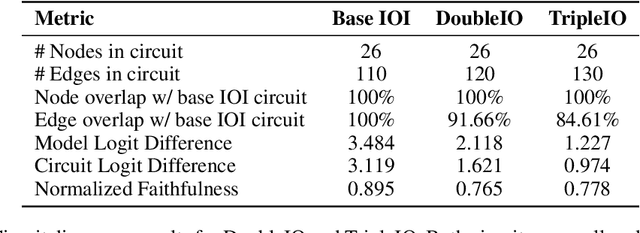
Mechanistic interpretability aims to understand the inner workings of large neural networks by identifying circuits, or minimal subgraphs within the model that implement algorithms responsible for performing specific tasks. These circuits are typically discovered and analyzed using a narrowly defined prompt format. However, given the abilities of large language models (LLMs) to generalize across various prompt formats for the same task, it remains unclear how well these circuits generalize. For instance, it is unclear whether the models generalization results from reusing the same circuit components, the components behaving differently, or the use of entirely different components. In this paper, we investigate the generality of the indirect object identification (IOI) circuit in GPT-2 small, which is well-studied and believed to implement a simple, interpretable algorithm. We evaluate its performance on prompt variants that challenge the assumptions of this algorithm. Our findings reveal that the circuit generalizes surprisingly well, reusing all of its components and mechanisms while only adding additional input edges. Notably, the circuit generalizes even to prompt variants where the original algorithm should fail; we discover a mechanism that explains this which we term S2 Hacking. Our findings indicate that circuits within LLMs may be more flexible and general than previously recognized, underscoring the importance of studying circuit generalization to better understand the broader capabilities of these models.
Compositional Models for Estimating Causal Effects
Jun 25, 2024Many real-world systems can be represented as sets of interacting components. Examples of such systems include computational systems such as query processors, natural systems such as cells, and social systems such as families. Many approaches have been proposed in traditional (associational) machine learning to model such structured systems, including statistical relational models and graph neural networks. Despite this prior work, existing approaches to estimating causal effects typically treat such systems as single units, represent them with a fixed set of variables and assume a homogeneous data-generating process. We study a compositional approach for estimating individual treatment effects (ITE) in structured systems, where each unit is represented by the composition of multiple heterogeneous components. This approach uses a modular architecture to model potential outcomes at each component and aggregates component-level potential outcomes to obtain the unit-level potential outcomes. We discover novel benefits of the compositional approach in causal inference - systematic generalization to estimate counterfactual outcomes of unseen combinations of components and improved overlap guarantees between treatment and control groups compared to the classical methods for causal effect estimation. We also introduce a set of novel environments for empirically evaluating the compositional approach and demonstrate the effectiveness of our approach using both simulated and real-world data.
Automated Discovery of Functional Actual Causes in Complex Environments
Apr 16, 2024



Reinforcement learning (RL) algorithms often struggle to learn policies that generalize to novel situations due to issues such as causal confusion, overfitting to irrelevant factors, and failure to isolate control of state factors. These issues stem from a common source: a failure to accurately identify and exploit state-specific causal relationships in the environment. While some prior works in RL aim to identify these relationships explicitly, they rely on informal domain-specific heuristics such as spatial and temporal proximity. Actual causality offers a principled and general framework for determining the causes of particular events. However, existing definitions of actual cause often attribute causality to a large number of events, even if many of them rarely influence the outcome. Prior work on actual causality proposes normality as a solution to this problem, but its existing implementations are challenging to scale to complex and continuous-valued RL environments. This paper introduces functional actual cause (FAC), a framework that uses context-specific independencies in the environment to restrict the set of actual causes. We additionally introduce Joint Optimization for Actual Cause Inference (JACI), an algorithm that learns from observational data to infer functional actual causes. We demonstrate empirically that FAC agrees with known results on a suite of examples from the actual causality literature, and JACI identifies actual causes with significantly higher accuracy than existing heuristic methods in a set of complex, continuous-valued environments.
Improving the Efficiency of the PC Algorithm by Using Model-Based Conditional Independence Tests
Nov 12, 2022


Learning causal structure is useful in many areas of artificial intelligence, including planning, robotics, and explanation. Constraint-based structure learning algorithms such as PC use conditional independence (CI) tests to infer causal structure. Traditionally, constraint-based algorithms perform CI tests with a preference for smaller-sized conditioning sets, partially because the statistical power of conventional CI tests declines rapidly as the size of the conditioning set increases. However, many modern conditional independence tests are model-based, and these tests use well-regularized models that maintain statistical power even with very large conditioning sets. This suggests an intriguing new strategy for constraint-based algorithms which may result in a reduction of the total number of CI tests performed: Test variable pairs with large conditioning sets first, as a pre-processing step that finds some conditional independencies quickly, before moving on to the more conventional strategy that favors small conditioning sets. We propose such a pre-processing step for the PC algorithm which relies on performing CI tests on a few randomly selected large conditioning sets. We perform an empirical analysis on directed acyclic graphs (DAGs) that correspond to real-world systems and both empirical and theoretical analyses for Erd\H{o}s-Renyi DAGs. Our results show that Pre-Processing Plus PC (P3PC) performs far fewer CI tests than the original PC algorithm, between 0.5% to 36%, and often less than 10%, of the CI tests that the PC algorithm alone performs. The efficiency gains are particularly significant for the DAGs corresponding to real-world systems.
Measuring Interventional Robustness in Reinforcement Learning
Sep 19, 2022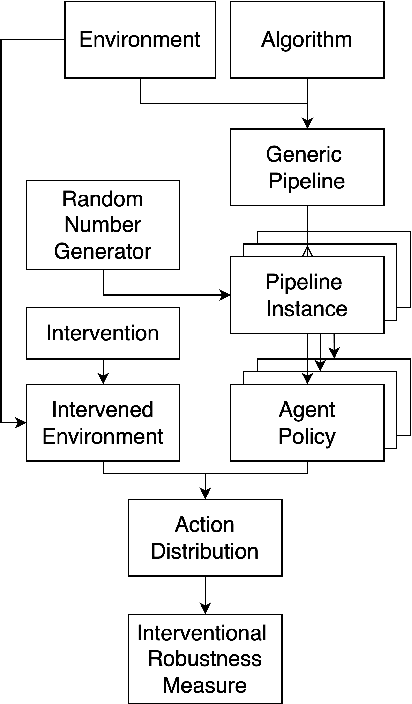
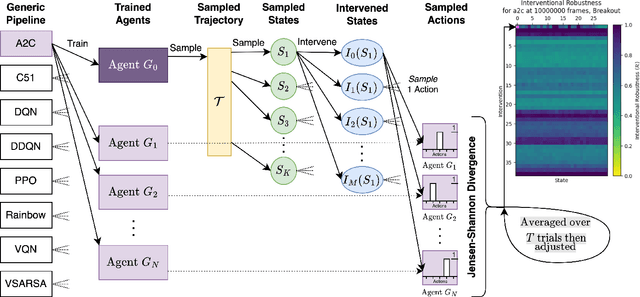

Recent work in reinforcement learning has focused on several characteristics of learned policies that go beyond maximizing reward. These properties include fairness, explainability, generalization, and robustness. In this paper, we define interventional robustness (IR), a measure of how much variability is introduced into learned policies by incidental aspects of the training procedure, such as the order of training data or the particular exploratory actions taken by agents. A training procedure has high IR when the agents it produces take very similar actions under intervention, despite variation in these incidental aspects of the training procedure. We develop an intuitive, quantitative measure of IR and calculate it for eight algorithms in three Atari environments across dozens of interventions and states. From these experiments, we find that IR varies with the amount of training and type of algorithm and that high performance does not imply high IR, as one might expect.
Brittle AI, Causal Confusion, and Bad Mental Models: Challenges and Successes in the XAI Program
Jun 10, 2021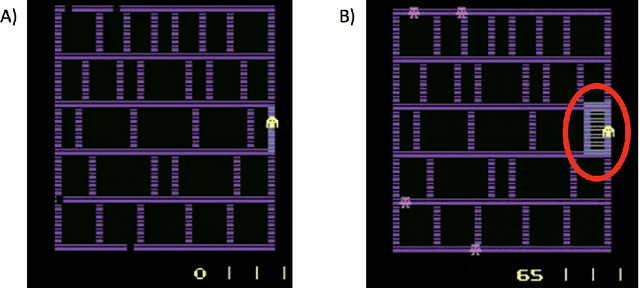
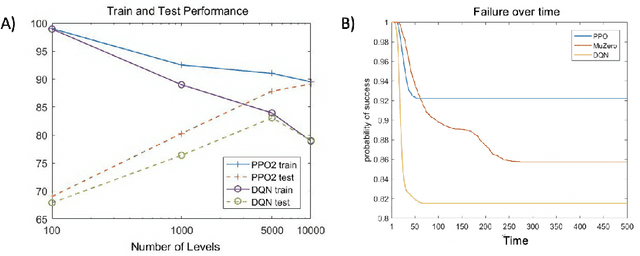
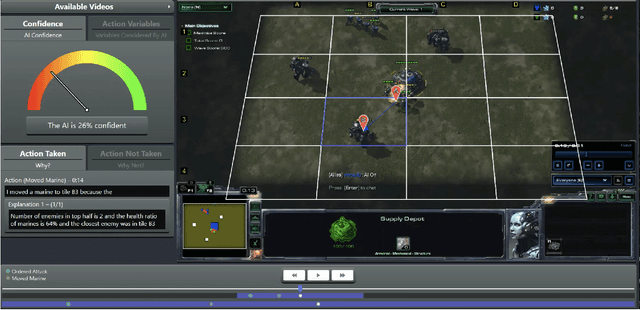
The advances in artificial intelligence enabled by deep learning architectures are undeniable. In several cases, deep neural network driven models have surpassed human level performance in benchmark autonomy tasks. The underlying policies for these agents, however, are not easily interpretable. In fact, given their underlying deep models, it is impossible to directly understand the mapping from observations to actions for any reasonably complex agent. Producing this supporting technology to "open the black box" of these AI systems, while not sacrificing performance, was the fundamental goal of the DARPA XAI program. In our journey through this program, we have several "big picture" takeaways: 1) Explanations need to be highly tailored to their scenario; 2) many seemingly high performing RL agents are extremely brittle and are not amendable to explanation; 3) causal models allow for rich explanations, but how to present them isn't always straightforward; and 4) human subjects conjure fantastically wrong mental models for AIs, and these models are often hard to break. This paper discusses the origins of these takeaways, provides amplifying information, and suggestions for future work.
A Simulation-Based Test of Identifiability for Bayesian Causal Inference
Feb 23, 2021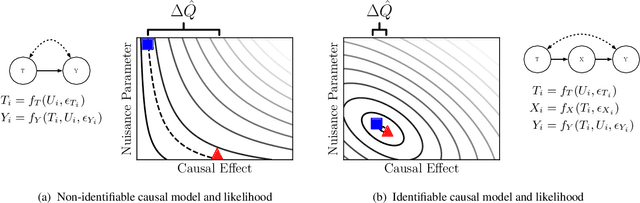

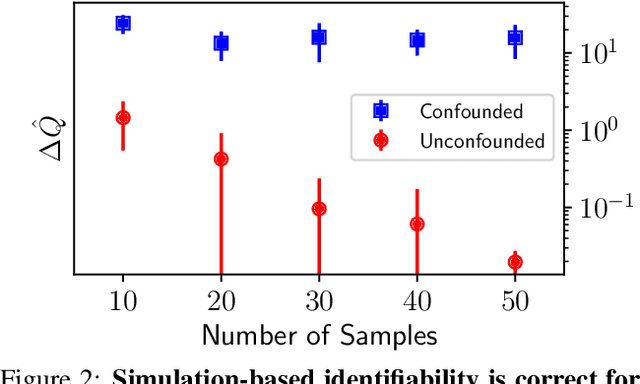
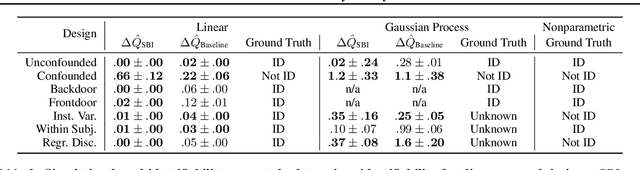
This paper introduces a procedure for testing the identifiability of Bayesian models for causal inference. Although the do-calculus is sound and complete given a causal graph, many practical assumptions cannot be expressed in terms of graph structure alone, such as the assumptions required by instrumental variable designs, regression discontinuity designs, and within-subjects designs. We present simulation-based identifiability (SBI), a fully automated identification test based on a particle optimization scheme with simulated observations. This approach expresses causal assumptions as priors over functions in a structural causal model, including flexible priors using Gaussian processes. We prove that SBI is asymptotically sound and complete, and produces practical finite-sample bounds. We also show empirically that SBI agrees with known results in graph-based identification as well as with widely-held intuitions for designs in which graph-based methods are inconclusive.
Preserving Privacy in Personalized Models for Distributed Mobile Services
Jan 14, 2021
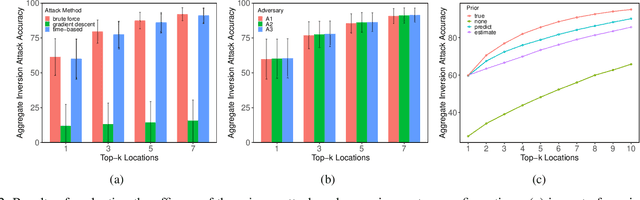
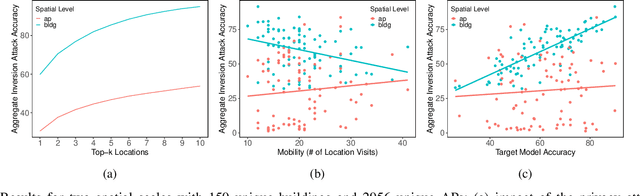
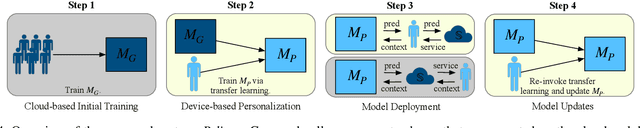
The ubiquity of mobile devices has led to the proliferation of mobile services that provide personalized and context-aware content to their users. Modern mobile services are distributed between end-devices, such as smartphones, and remote servers that reside in the cloud. Such services thrive on their ability to predict future contexts to pre-fetch content of make context-specific recommendations. An increasingly common method to predict future contexts, such as location, is via machine learning (ML) models. Recent work in context prediction has focused on ML model personalization where a personalized model is learned for each individual user in order to tailor predictions or recommendations to a user's mobile behavior. While the use of personalized models increases efficacy of the mobile service, we argue that it increases privacy risk since a personalized model encodes contextual behavior unique to each user. To demonstrate these privacy risks, we present several attribute inference-based privacy attacks and show that such attacks can leak privacy with up to 78% efficacy for top-3 predictions. We present Pelican, a privacy-preserving personalization system for context-aware mobile services that leverages both device and cloud resources to personalize ML models while minimizing the risk of privacy leakage for users. We evaluate Pelican using real world traces for location-aware mobile services and show that Pelican can substantially reduce privacy leakage by up to 75%.
Using Experimental Data to Evaluate Methods for Observational Causal Inference
Oct 06, 2020

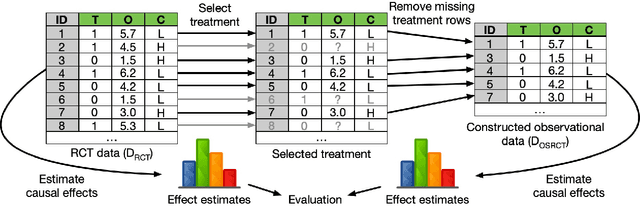
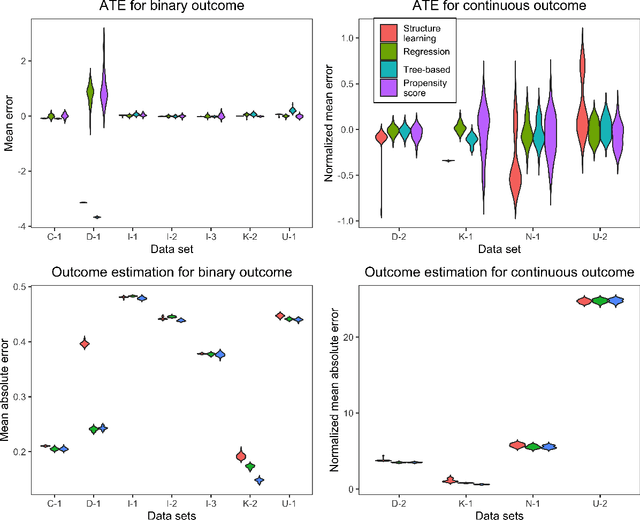
Methods that infer causal dependence from observational data are central to many areas of science, including medicine, economics, and the social sciences. A variety of theoretical properties of these methods have been proven, but empirical evaluation remains a challenge, largely due to the lack of observational data sets for which treatment effect is known. We propose and analyze observational sampling from randomized controlled trials (OSRCT), a method for evaluating causal inference methods using data from randomized controlled trials (RCTs). This method can be used to create constructed observational data sets with corresponding unbiased estimates of treatment effect, substantially increasing the number of data sets available for evaluating causal inference methods. We show that, in expectation, OSRCT creates data sets that are equivalent to those produced by randomly sampling from empirical data sets in which all potential outcomes are available. We analyze several properties of OSRCT theoretically and empirically, and we demonstrate its use by comparing the performance of four causal inference methods using data from eleven RCTs.
Causal Inference using Gaussian Processes with Structured Latent Confounders
Jul 14, 2020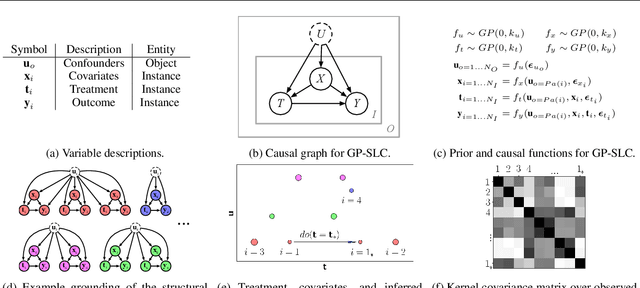
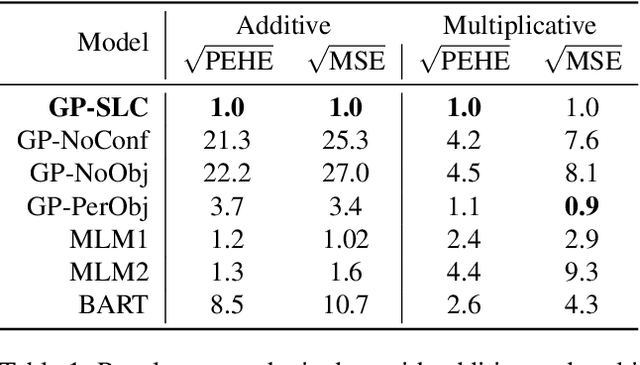
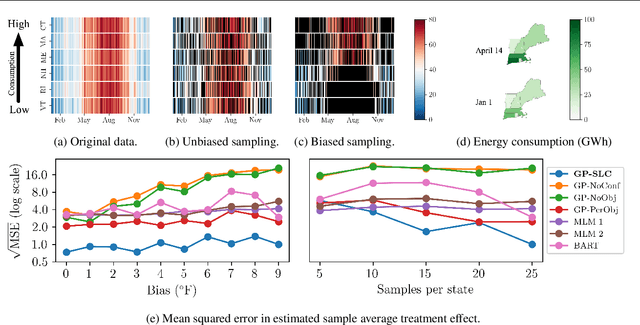
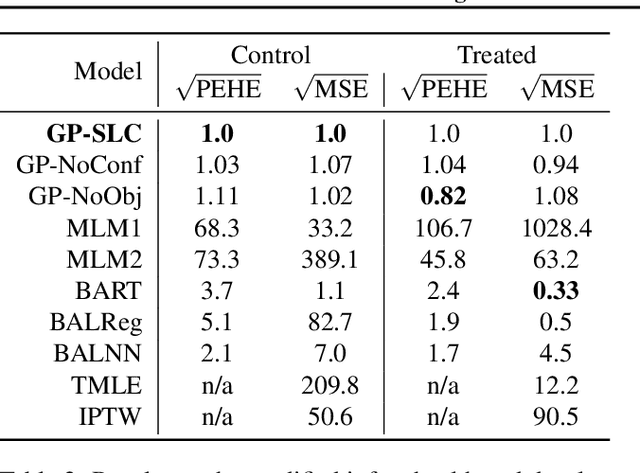
Latent confounders---unobserved variables that influence both treatment and outcome---can bias estimates of causal effects. In some cases, these confounders are shared across observations, e.g. all students taking a course are influenced by the course's difficulty in addition to any educational interventions they receive individually. This paper shows how to semiparametrically model latent confounders that have this structure and thereby improve estimates of causal effects. The key innovations are a hierarchical Bayesian model, Gaussian processes with structured latent confounders (GP-SLC), and a Monte Carlo inference algorithm for this model based on elliptical slice sampling. GP-SLC provides principled Bayesian uncertainty estimates of individual treatment effect with minimal assumptions about the functional forms relating confounders, covariates, treatment, and outcome. Finally, this paper shows GP-SLC is competitive with or more accurate than widely used causal inference techniques on three benchmark datasets, including the Infant Health and Development Program and a dataset showing the effect of changing temperatures on state-wide energy consumption across New England.