 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrittle AI, Causal Confusion, and Bad Mental Models: Challenges and Successes in the XAI Program
Jun 10, 2021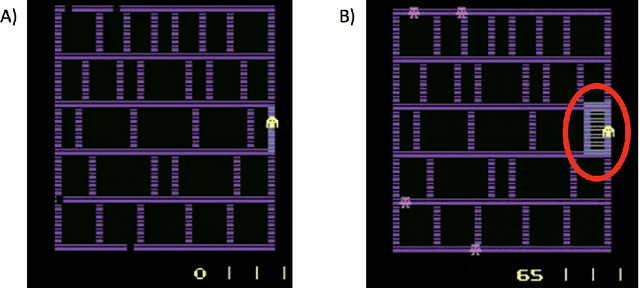
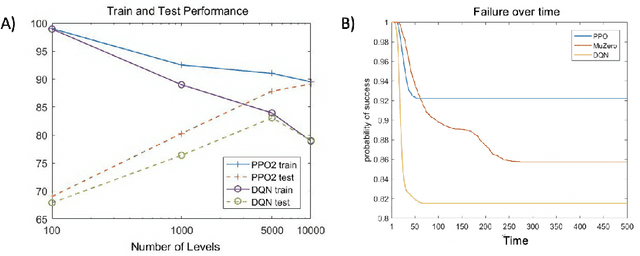
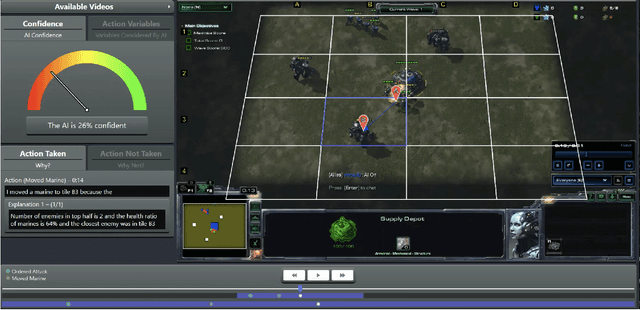
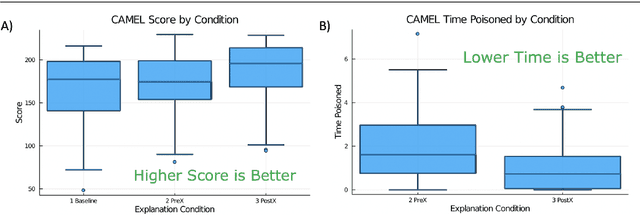
The advances in artificial intelligence enabled by deep learning architectures are undeniable. In several cases, deep neural network driven models have surpassed human level performance in benchmark autonomy tasks. The underlying policies for these agents, however, are not easily interpretable. In fact, given their underlying deep models, it is impossible to directly understand the mapping from observations to actions for any reasonably complex agent. Producing this supporting technology to "open the black box" of these AI systems, while not sacrificing performance, was the fundamental goal of the DARPA XAI program. In our journey through this program, we have several "big picture" takeaways: 1) Explanations need to be highly tailored to their scenario; 2) many seemingly high performing RL agents are extremely brittle and are not amendable to explanation; 3) causal models allow for rich explanations, but how to present them isn't always straightforward; and 4) human subjects conjure fantastically wrong mental models for AIs, and these models are often hard to break. This paper discusses the origins of these takeaways, provides amplifying information, and suggestions for future work.