 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Investigating Global News Coverage of Critical Events Such as Disasters and Terrorist Attacks
Jun 15, 2025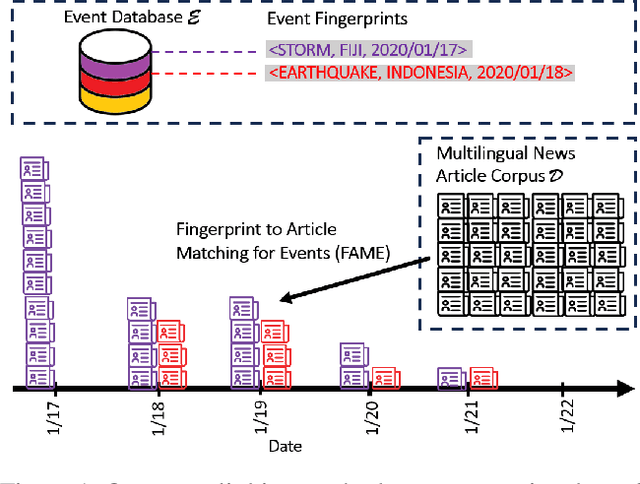

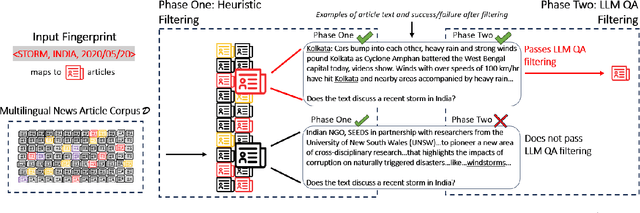
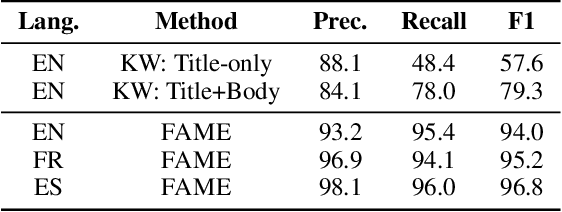
Comparative studies of news coverage are challenging to conduct because methods to identify news articles about the same event in different languages require expertise that is difficult to scale. We introduce an AI-powered method for identifying news articles based on an event FINGERPRINT, which is a minimal set of metadata required to identify critical events. Our event coverage identification method, FINGERPRINT TO ARTICLE MATCHING FOR EVENTS (FAME), efficiently identifies news articles about critical world events, specifically terrorist attacks and several types of natural disasters. FAME does not require training data and is able to automatically and efficiently identify news articles that discuss an event given its fingerprint: time, location, and class (such as storm or flood). The method achieves state-of-the-art performance and scales to massive databases of tens of millions of news articles and hundreds of events happening globally. We use FAME to identify 27,441 articles that cover 470 natural disaster and terrorist attack events that happened in 2020. To this end, we use a massive database of news articles in three languages from MediaCloud, and three widely used, expert-curated databases of critical events: EM-DAT, USGS, and GTD. Our case study reveals patterns consistent with prior literature: coverage of disasters and terrorist attacks correlates to death counts, to the GDP of a country where the event occurs, and to trade volume between the reporting country and the country where the event occurred. We share our NLP annotations and cross-country media attention data to support the efforts of researchers and media monitoring organizations.
Understanding the Effect of Knowledge Graph Extraction Error on Downstream Graph Analyses: A Case Study on Affiliation Graphs
Jun 14, 2025Knowledge graphs (KGs) are useful for analyzing social structures, community dynamics, institutional memberships, and other complex relationships across domains from sociology to public health. While recent advances in large language models (LLMs) have improved the scalability and accessibility of automated KG extraction from large text corpora, the impacts of extraction errors on downstream analyses are poorly understood, especially for applied scientists who depend on accurate KGs for real-world insights. To address this gap, we conducted the first evaluation of KG extraction performance at two levels: (1) micro-level edge accuracy, which is consistent with standard NLP evaluations, and manual identification of common error sources; (2) macro-level graph metrics that assess structural properties such as community detection and connectivity, which are relevant to real-world applications. Focusing on affiliation graphs of person membership in organizations extracted from social register books, our study identifies a range of extraction performance where biases across most downstream graph analysis metrics are near zero. However, as extraction performance declines, we find that many metrics exhibit increasingly pronounced biases, with each metric tending toward a consistent direction of either over- or under-estimation. Through simulations, we further show that error models commonly used in the literature do not capture these bias patterns, indicating the need for more realistic error models for KG extraction. Our findings provide actionable insights for practitioners and underscores the importance of advancing extraction methods and error modeling to ensure reliable and meaningful downstream analyses.
Relation Extraction Across Entire Books to Reconstruct Community Networks: The AffilKG Datasets
May 16, 2025



When knowledge graphs (KGs) are automatically extracted from text, are they accurate enough for downstream analysis? Unfortunately, current annotated datasets can not be used to evaluate this question, since their KGs are highly disconnected, too small, or overly complex. To address this gap, we introduce AffilKG (https://doi.org/10.5281/zenodo.15427977), which is a collection of six datasets that are the first to pair complete book scans with large, labeled knowledge graphs. Each dataset features affiliation graphs, which are simple KGs that capture Member relationships between Person and Organization entities -- useful in studies of migration, community interactions, and other social phenomena. In addition, three datasets include expanded KGs with a wider variety of relation types. Our preliminary experiments demonstrate significant variability in model performance across datasets, underscoring AffilKG's ability to enable two critical advances: (1) benchmarking how extraction errors propagate to graph-level analyses (e.g., community structure), and (2) validating KG extraction methods for real-world social science research.
A Monte Carlo Language Model Pipeline for Zero-Shot Sociopolitical Event Extraction
May 24, 2023
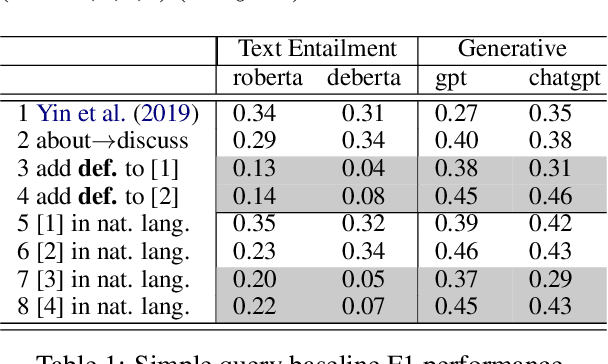


We consider dyadic zero-shot event extraction (EE) to identify actions between pairs of actors. The \emph{zero-shot} setting allows social scientists or other non-computational researchers to extract any customized, user-specified set of events without training, resulting in a \emph{dyadic} event database, allowing insight into sociopolitical relational dynamics among actors and the higher level organizations or countries they represent. Unfortunately, we find that current zero-shot EE methods perform poorly for the task, with issues including word sense ambiguity, modality mismatch, and efficiency. Straightforward application of large language model prompting typically performs even worse. We address these challenges with a new fine-grained, multi-stage generative question-answer method, using a Monte Carlo approach to exploit and overcome the randomness of generative outputs. It performs 90\% fewer queries than a previous approach, with strong performance on the widely-used Automatic Content Extraction dataset. Finally, we extend our method to extract affiliations of actor arguments and demonstrate our method and findings on a dyadic international relations case study.
Improving the Efficiency of the PC Algorithm by Using Model-Based Conditional Independence Tests
Nov 12, 2022


Learning causal structure is useful in many areas of artificial intelligence, including planning, robotics, and explanation. Constraint-based structure learning algorithms such as PC use conditional independence (CI) tests to infer causal structure. Traditionally, constraint-based algorithms perform CI tests with a preference for smaller-sized conditioning sets, partially because the statistical power of conventional CI tests declines rapidly as the size of the conditioning set increases. However, many modern conditional independence tests are model-based, and these tests use well-regularized models that maintain statistical power even with very large conditioning sets. This suggests an intriguing new strategy for constraint-based algorithms which may result in a reduction of the total number of CI tests performed: Test variable pairs with large conditioning sets first, as a pre-processing step that finds some conditional independencies quickly, before moving on to the more conventional strategy that favors small conditioning sets. We propose such a pre-processing step for the PC algorithm which relies on performing CI tests on a few randomly selected large conditioning sets. We perform an empirical analysis on directed acyclic graphs (DAGs) that correspond to real-world systems and both empirical and theoretical analyses for Erd\H{o}s-Renyi DAGs. Our results show that Pre-Processing Plus PC (P3PC) performs far fewer CI tests than the original PC algorithm, between 0.5% to 36%, and often less than 10%, of the CI tests that the PC algorithm alone performs. The efficiency gains are particularly significant for the DAGs corresponding to real-world systems.
Adaptive Selection of the Optimal Strategy to Improve Precision and Power in Randomized Trials
Oct 31, 2022



Benkeser et al. demonstrate how adjustment for baseline covariates in randomized trials can meaningfully improve precision for a variety of outcome types, including binary, ordinal, and time-to-event. Their findings build on a long history, starting in 1932 with R.A. Fisher and including the more recent endorsements by the U.S. Food and Drug Administration and the European Medicines Agency. Here, we address an important practical consideration: how to select the adjustment approach -- which variables and in which form -- to maximize precision, while maintaining nominal confidence interval coverage. Balzer et al. previously proposed, evaluated, and applied Adaptive Prespecification to flexibly select, from a prespecified set, the variables that maximize empirical efficiency in small randomized trials (N<40). To avoid overfitting with few randomized units, adjustment was previously limited to a single covariate in a working generalized linear model (GLM) for the expected outcome and a single covariate in a working GLM for the propensity score. Here, we tailor Adaptive Prespecification to trials with many randomized units. Specifically, using V-fold cross-validation and the squared influence curve as the loss function, we select from an expanded set of candidate algorithms, including both parametric and semi-parametric methods, the optimal combination of estimators of the expected outcome and known propensity score. Using simulations, under a variety of data generating processes, we demonstrate the dramatic gains in precision offered by our novel approach.
Measuring Interventional Robustness in Reinforcement Learning
Sep 19, 2022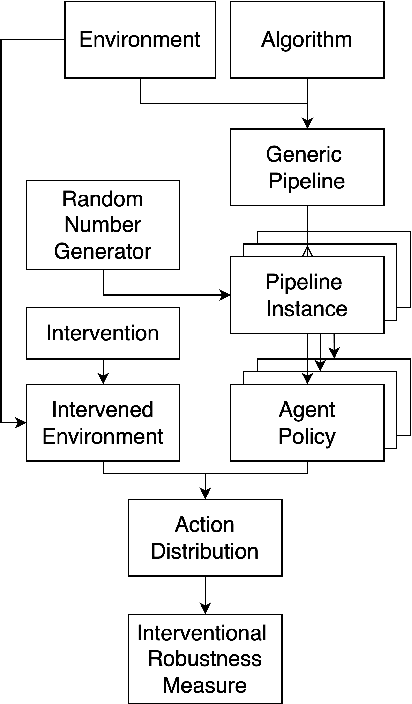
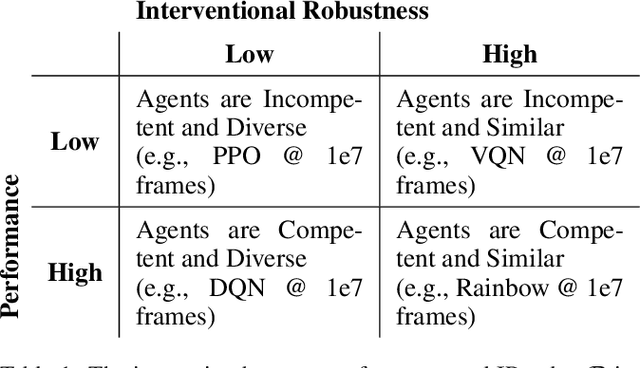
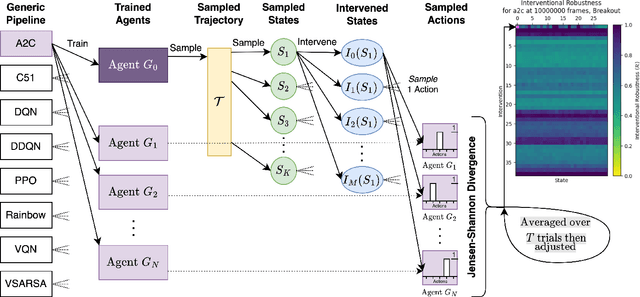

Recent work in reinforcement learning has focused on several characteristics of learned policies that go beyond maximizing reward. These properties include fairness, explainability, generalization, and robustness. In this paper, we define interventional robustness (IR), a measure of how much variability is introduced into learned policies by incidental aspects of the training procedure, such as the order of training data or the particular exploratory actions taken by agents. A training procedure has high IR when the agents it produces take very similar actions under intervention, despite variation in these incidental aspects of the training procedure. We develop an intuitive, quantitative measure of IR and calculate it for eight algorithms in three Atari environments across dozens of interventions and states. From these experiments, we find that IR varies with the amount of training and type of algorithm and that high performance does not imply high IR, as one might expect.