 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Selection of the Optimal Strategy to Improve Precision and Power in Randomized Trials
Oct 31, 2022



Benkeser et al. demonstrate how adjustment for baseline covariates in randomized trials can meaningfully improve precision for a variety of outcome types, including binary, ordinal, and time-to-event. Their findings build on a long history, starting in 1932 with R.A. Fisher and including the more recent endorsements by the U.S. Food and Drug Administration and the European Medicines Agency. Here, we address an important practical consideration: how to select the adjustment approach -- which variables and in which form -- to maximize precision, while maintaining nominal confidence interval coverage. Balzer et al. previously proposed, evaluated, and applied Adaptive Prespecification to flexibly select, from a prespecified set, the variables that maximize empirical efficiency in small randomized trials (N<40). To avoid overfitting with few randomized units, adjustment was previously limited to a single covariate in a working generalized linear model (GLM) for the expected outcome and a single covariate in a working GLM for the propensity score. Here, we tailor Adaptive Prespecification to trials with many randomized units. Specifically, using V-fold cross-validation and the squared influence curve as the loss function, we select from an expanded set of candidate algorithms, including both parametric and semi-parametric methods, the optimal combination of estimators of the expected outcome and known propensity score. Using simulations, under a variety of data generating processes, we demonstrate the dramatic gains in precision offered by our novel approach.
Measuring Interventional Robustness in Reinforcement Learning
Sep 19, 2022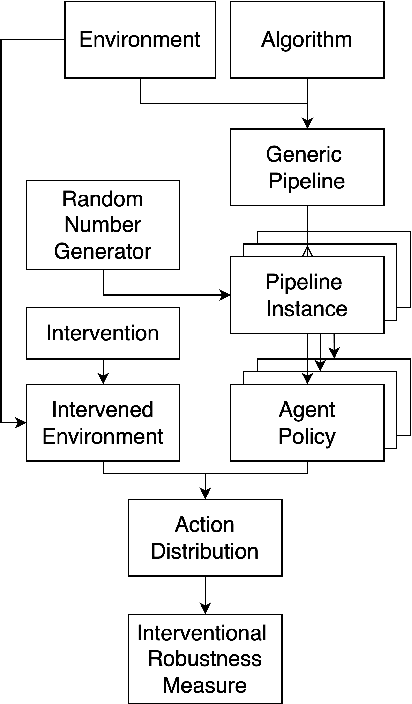
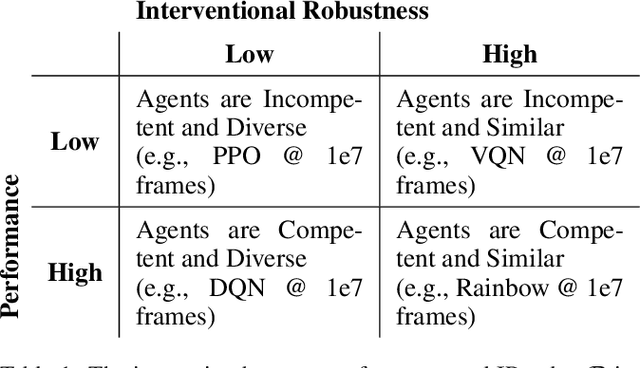
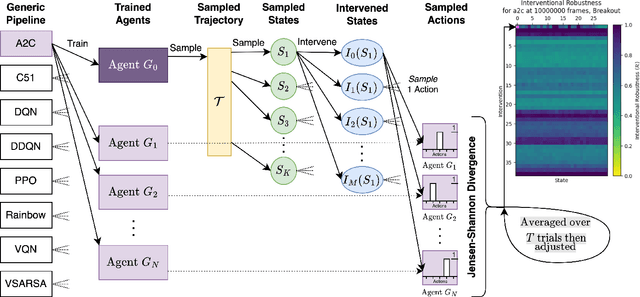

Recent work in reinforcement learning has focused on several characteristics of learned policies that go beyond maximizing reward. These properties include fairness, explainability, generalization, and robustness. In this paper, we define interventional robustness (IR), a measure of how much variability is introduced into learned policies by incidental aspects of the training procedure, such as the order of training data or the particular exploratory actions taken by agents. A training procedure has high IR when the agents it produces take very similar actions under intervention, despite variation in these incidental aspects of the training procedure. We develop an intuitive, quantitative measure of IR and calculate it for eight algorithms in three Atari environments across dozens of interventions and states. From these experiments, we find that IR varies with the amount of training and type of algorithm and that high performance does not imply high IR, as one might expect.