 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning to optimize precision in the analysis of randomized trials: A journey in pre-specified, yet data-adaptive learning
Dec 15, 2025Covariate adjustment is an approach to improve the precision of trial analyses by adjusting for baseline variables that are prognostic of the primary endpoint. Motivated by the SEARCH Universal HIV Test-and-Treat Trial (2013-2017), we tell our story of developing, evaluating, and implementing a machine learning-based approach for covariate adjustment. We provide the rationale for as well as the practical concerns with such an approach for estimating marginal effects. Using schematics, we illustrate our procedure: targeted machine learning estimation (TMLE) with Adaptive Pre-specification. Briefly, sample-splitting is used to data-adaptively select the combination of estimators of the outcome regression (i.e., the conditional expectation of the outcome given the trial arm and covariates) and known propensity score (i.e., the conditional probability of being randomized to the intervention given the covariates) that minimizes the cross-validated variance estimate and, thereby, maximizes empirical efficiency. We discuss our approach for evaluating finite sample performance with parametric and plasmode simulations, pre-specifying the Statistical Analysis Plan, and unblinding in real-time on video conference with our colleagues from around the world. We present the results from applying our approach in the primary, pre-specified analysis of 8 recently published trials (2022-2024). We conclude with practical recommendations and an invitation to implement our approach in the primary analysis of your next trial.
Large Language Models as Co-Pilots for Causal Inference in Medical Studies
Jul 26, 2024

The validity of medical studies based on real-world clinical data, such as observational studies, depends on critical assumptions necessary for drawing causal conclusions about medical interventions. Many published studies are flawed because they violate these assumptions and entail biases such as residual confounding, selection bias, and misalignment between treatment and measurement times. Although researchers are aware of these pitfalls, they continue to occur because anticipating and addressing them in the context of a specific study can be challenging without a large, often unwieldy, interdisciplinary team with extensive expertise. To address this expertise gap, we explore the use of large language models (LLMs) as co-pilot tools to assist researchers in identifying study design flaws that undermine the validity of causal inferences. We propose a conceptual framework for LLMs as causal co-pilots that encode domain knowledge across various fields, engaging with researchers in natural language interactions to provide contextualized assistance in study design. We provide illustrative examples of how LLMs can function as causal co-pilots, propose a structured framework for their grounding in existing causal inference frameworks, and highlight the unique challenges and opportunities in adapting LLMs for reliable use in epidemiological research.
Adaptive Selection of the Optimal Strategy to Improve Precision and Power in Randomized Trials
Oct 31, 2022



Benkeser et al. demonstrate how adjustment for baseline covariates in randomized trials can meaningfully improve precision for a variety of outcome types, including binary, ordinal, and time-to-event. Their findings build on a long history, starting in 1932 with R.A. Fisher and including the more recent endorsements by the U.S. Food and Drug Administration and the European Medicines Agency. Here, we address an important practical consideration: how to select the adjustment approach -- which variables and in which form -- to maximize precision, while maintaining nominal confidence interval coverage. Balzer et al. previously proposed, evaluated, and applied Adaptive Prespecification to flexibly select, from a prespecified set, the variables that maximize empirical efficiency in small randomized trials (N<40). To avoid overfitting with few randomized units, adjustment was previously limited to a single covariate in a working generalized linear model (GLM) for the expected outcome and a single covariate in a working GLM for the propensity score. Here, we tailor Adaptive Prespecification to trials with many randomized units. Specifically, using V-fold cross-validation and the squared influence curve as the loss function, we select from an expanded set of candidate algorithms, including both parametric and semi-parametric methods, the optimal combination of estimators of the expected outcome and known propensity score. Using simulations, under a variety of data generating processes, we demonstrate the dramatic gains in precision offered by our novel approach.
Evaluating shifts in mobility and COVID-19 case rates in U.S. counties: A demonstration of modified treatment policies for causal inference with continuous exposures
Oct 27, 2021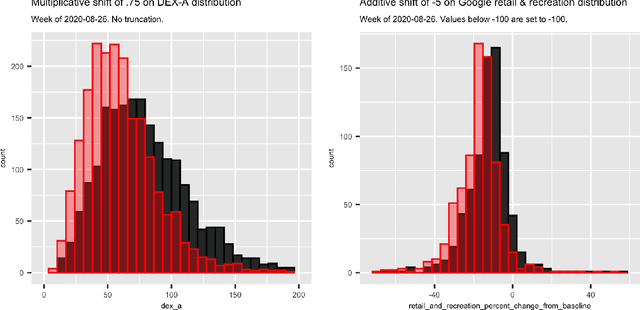
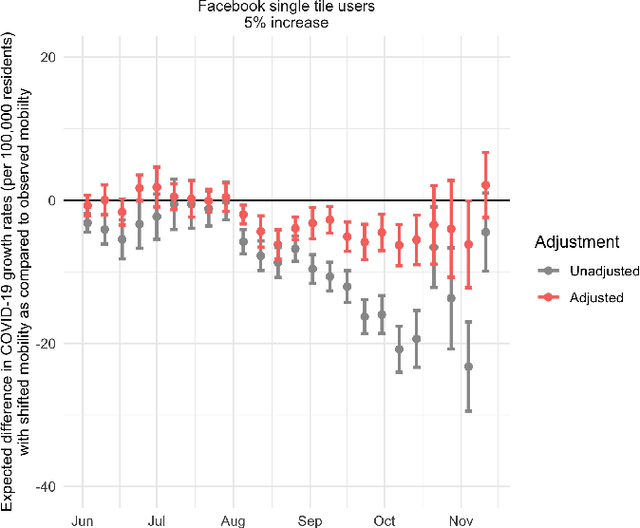
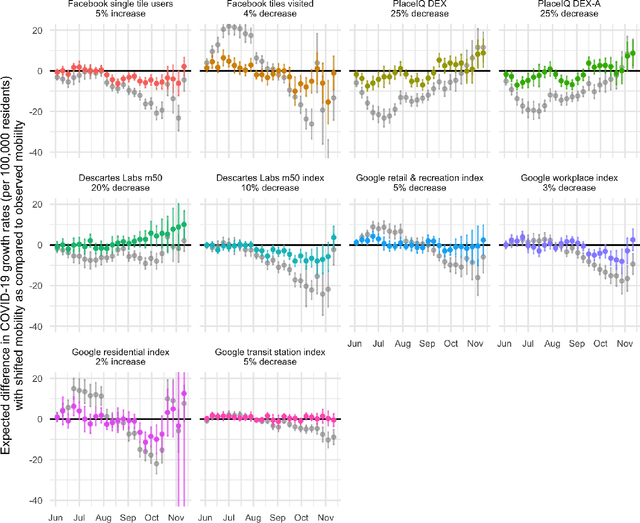
Previous research has shown mixed evidence on the associations between mobility data and COVID-19 case rates, analysis of which is complicated by differences between places on factors influencing both behavior and health outcomes. We aimed to evaluate the county-level impact of shifting the distribution of mobility on the growth in COVID-19 case rates from June 1 - November 14, 2020. We utilized a modified treatment policy (MTP) approach, which considers the impact of shifting an exposure away from its observed value. The MTP approach facilitates studying the effects of continuous exposures while minimizing parametric modeling assumptions. Ten mobility indices were selected to capture several aspects of behavior expected to influence and be influenced by COVID-19 case rates. The outcome was defined as the number of new cases per 100,000 residents two weeks ahead of each mobility measure. Primary analyses used targeted minimum loss-based estimation (TMLE) with a Super Learner ensemble of machine learning algorithms, considering over 20 potential confounders capturing counties' recent case rates as well as social, economic, health, and demographic variables. For comparison, we also implemented unadjusted analyses. For most weeks considered, unadjusted analyses suggested strong associations between mobility indices and subsequent growth in case rates. However, after confounder adjustment, none of the indices showed consistent associations after hypothetical shifts to reduce mobility. While identifiability concerns limit our ability to make causal claims in this analysis, MTPs are a powerful and underutilized tool for studying the effects of continuous exposures.
Two-Stage TMLE to Reduce Bias and Improve Efficiency in Cluster Randomized Trials
Jun 29, 2021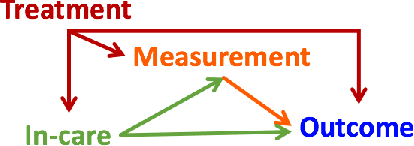

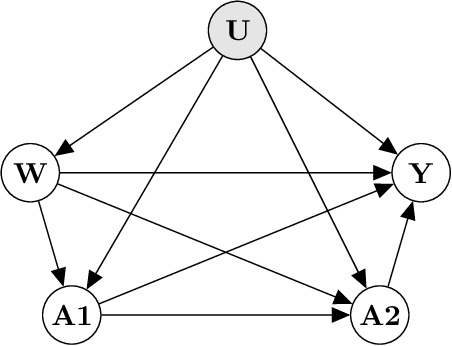
Cluster randomized trials (CRTs) randomly assign an intervention to groups of individuals (e.g., clinics or communities), and measure outcomes on individuals in those groups. While offering many advantages, this experimental design introduces challenges that are only partially addressed by existing analytic approaches. First, outcomes are often missing for some individuals within clusters. Failing to appropriately adjust for differential outcome measurement can result in biased estimates and inference. Second, CRTs often randomize limited numbers of clusters, resulting in chance imbalances on baseline outcome predictors between arms. Failing to adaptively adjust for these imbalances and other predictive covariates can result in efficiency losses. To address these methodological gaps, we propose and evaluate a novel two-stage targeted minimum loss-based estimator (TMLE) to adjust for baseline covariates in a manner that optimizes precision, after controlling for baseline and post-baseline causes of missing outcomes. Finite sample simulations illustrate that our approach can nearly eliminate bias due to differential outcome measurement, while other common CRT estimators yield misleading results and inferences. Application to real data from the SEARCH community randomized trial demonstrates the gains in efficiency afforded through adaptive adjustment for cluster-level covariates, after controlling for missingness on individual-level outcomes.
A Primer on Causality in Data Science
Sep 07, 2018
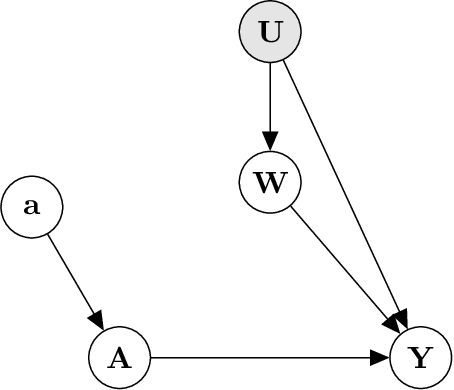

Many questions in Data Science are fundamentally causal in that our objective is to learn the effect of some exposure (randomized or not) on an outcome interest. Even studies that are seemingly non-causal (e.g. prediction or prevalence estimation) have causal elements, such as differential censoring or measurement. As a result, we, as Data Scientists, need to consider the underlying causal mechanisms that gave rise to the data, rather than simply the pattern or association observed in the data. In this work, we review the "Causal Roadmap", a formal framework to augment our traditional statistical analyses in an effort to answer the causal questions driving our research. Specific steps of the Roadmap include clearly stating the scientific question, defining of the causal model, translating the scientific question into a causal parameter, assessing the assumptions needed to translate the causal parameter into a statistical estimand, implementation of statistical estimators including parametric and semi-parametric methods, and interpretation of our findings. Throughout we focus on the effect of an exposure occurring at a single time point and provide extensions to more advanced settings.