 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks
Jun 16, 2025Recent advances in Large Language Models (LLMs) have showcased impressive reasoning abilities in structured tasks like mathematics and programming, largely driven by Reinforcement Learning with Verifiable Rewards (RLVR), which uses outcome-based signals that are scalable, effective, and robust against reward hacking. However, applying similar techniques to open-ended long-form reasoning tasks remains challenging due to the absence of generic, verifiable reward signals. To address this, we propose Direct Reasoning Optimization (DRO), a reinforcement learning framework for fine-tuning LLMs on open-ended, particularly long-form, reasoning tasks, guided by a new reward signal: the Reasoning Reflection Reward (R3). At its core, R3 selectively identifies and emphasizes key tokens in the reference outcome that reflect the influence of the model's preceding chain-of-thought reasoning, thereby capturing the consistency between reasoning and reference outcome at a fine-grained level. Crucially, R3 is computed internally using the same model being optimized, enabling a fully self-contained training setup. Additionally, we introduce a dynamic data filtering strategy based on R3 for open-ended reasoning tasks, reducing cost while improving downstream performance. We evaluate DRO on two diverse datasets -- ParaRev, a long-form paragraph revision task, and FinQA, a math-oriented QA benchmark -- and show that it consistently outperforms strong baselines while remaining broadly applicable across both open-ended and structured domains.
Walk the Talk? Measuring the Faithfulness of Large Language Model Explanations
Apr 19, 2025Large language models (LLMs) are capable of generating plausible explanations of how they arrived at an answer to a question. However, these explanations can misrepresent the model's "reasoning" process, i.e., they can be unfaithful. This, in turn, can lead to over-trust and misuse. We introduce a new approach for measuring the faithfulness of LLM explanations. First, we provide a rigorous definition of faithfulness. Since LLM explanations mimic human explanations, they often reference high-level concepts in the input question that purportedly influenced the model. We define faithfulness in terms of the difference between the set of concepts that LLM explanations imply are influential and the set that truly are. Second, we present a novel method for estimating faithfulness that is based on: (1) using an auxiliary LLM to modify the values of concepts within model inputs to create realistic counterfactuals, and (2) using a Bayesian hierarchical model to quantify the causal effects of concepts at both the example- and dataset-level. Our experiments show that our method can be used to quantify and discover interpretable patterns of unfaithfulness. On a social bias task, we uncover cases where LLM explanations hide the influence of social bias. On a medical question answering task, we uncover cases where LLM explanations provide misleading claims about which pieces of evidence influenced the model's decisions.
RLTHF: Targeted Human Feedback for LLM Alignment
Feb 19, 2025



Fine-tuning large language models (LLMs) to align with user preferences is challenging due to the high cost of quality human annotations in Reinforcement Learning from Human Feedback (RLHF) and the generalizability limitations of AI Feedback. To address these challenges, we propose RLTHF, a human-AI hybrid framework that combines LLM-based initial alignment with selective human annotations to achieve full-human annotation alignment with minimal effort. RLTHF identifies hard-to-annotate samples mislabeled by LLMs using a reward model's reward distribution and iteratively enhances alignment by integrating strategic human corrections while leveraging LLM's correctly labeled samples. Evaluations on HH-RLHF and TL;DR datasets show that RLTHF reaches full-human annotation-level alignment with only 6-7% of the human annotation effort. Furthermore, models trained on RLTHF's curated datasets for downstream tasks outperform those trained on fully human-annotated datasets, underscoring the effectiveness of RLTHF's strategic data curation.
Large Language Models as Co-Pilots for Causal Inference in Medical Studies
Jul 26, 2024

The validity of medical studies based on real-world clinical data, such as observational studies, depends on critical assumptions necessary for drawing causal conclusions about medical interventions. Many published studies are flawed because they violate these assumptions and entail biases such as residual confounding, selection bias, and misalignment between treatment and measurement times. Although researchers are aware of these pitfalls, they continue to occur because anticipating and addressing them in the context of a specific study can be challenging without a large, often unwieldy, interdisciplinary team with extensive expertise. To address this expertise gap, we explore the use of large language models (LLMs) as co-pilot tools to assist researchers in identifying study design flaws that undermine the validity of causal inferences. We propose a conceptual framework for LLMs as causal co-pilots that encode domain knowledge across various fields, engaging with researchers in natural language interactions to provide contextualized assistance in study design. We provide illustrative examples of how LLMs can function as causal co-pilots, propose a structured framework for their grounding in existing causal inference frameworks, and highlight the unique challenges and opportunities in adapting LLMs for reliable use in epidemiological research.
A Glitch in the Matrix? Locating and Detecting Language Model Grounding with Fakepedia
Dec 04, 2023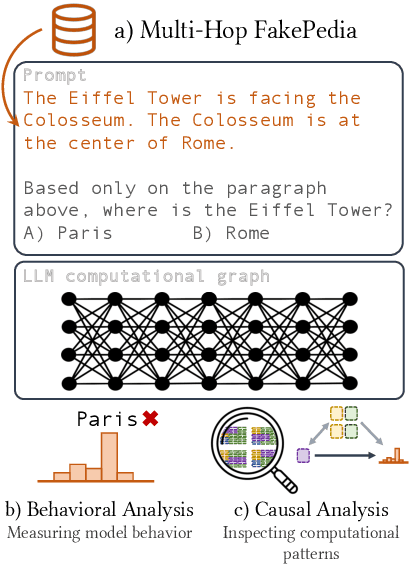
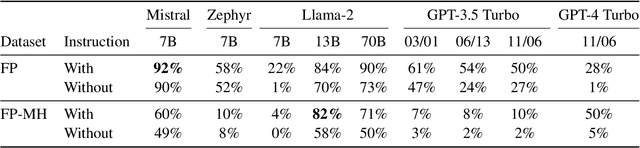
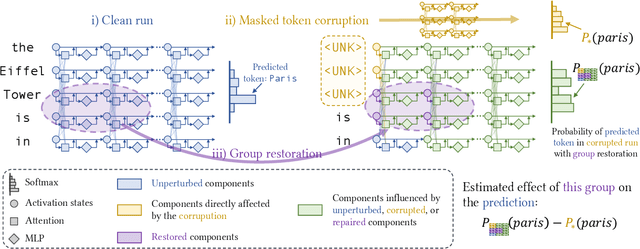
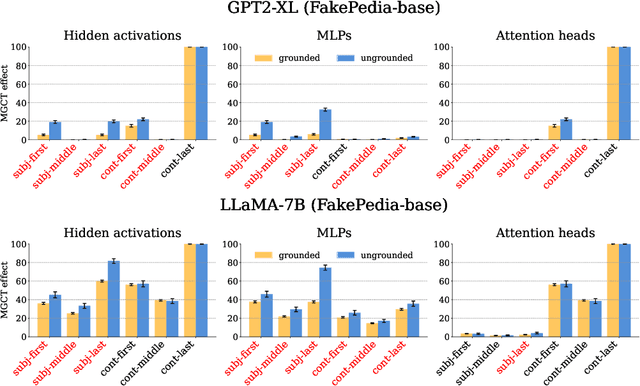
Large language models (LLMs) have demonstrated impressive capabilities in storing and recalling factual knowledge, but also in adapting to novel in-context information. Yet, the mechanisms underlying their in-context grounding remain unknown, especially in situations where in-context information contradicts factual knowledge embedded in the parameters. This is critical for retrieval-augmented generation methods, which enrich the context with up-to-date information, hoping that grounding can rectify the outdated parametric knowledge. In this study, we introduce Fakepedia, a counterfactual dataset designed to evaluate grounding abilities when the parametric knowledge clashes with the in-context information. We benchmark various LLMs with Fakepedia and discover that GPT-4-turbo has a strong preference for its parametric knowledge. Mistral-7B, on the contrary, is the model that most robustly chooses the grounded answer. Then, we conduct causal mediation analysis on LLM components when answering Fakepedia queries. We demonstrate that inspection of the computational graph alone can predict LLM grounding with 92.8% accuracy, especially because few MLPs in the Transformer can predict non-grounded behavior. Our results, together with existing findings about factual recall mechanisms, provide a coherent narrative of how grounding and factual recall mechanisms interact within LLMs.
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
May 08, 2023The causal capabilities of large language models (LLMs) is a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We further our understanding of LLMs and their causal implications, considering the distinctions between different types of causal reasoning tasks, as well as the entangled threats of construct and measurement validity. LLM-based methods establish new state-of-the-art accuracies on multiple causal benchmarks. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain), and actual causality (86% accuracy in determining necessary and sufficient causes in vignettes). At the same time, LLMs exhibit unpredictable failure modes and we provide some techniques to interpret their robustness. Crucially, LLMs perform these causal tasks while relying on sources of knowledge and methods distinct from and complementary to non-LLM based approaches. Specifically, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. We envision LLMs to be used alongside existing causal methods, as a proxy for human domain knowledge and to reduce human effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. We also see existing causal methods as promising tools for LLMs to formalize, validate, and communicate their reasoning especially in high-stakes scenarios. In capturing common sense and domain knowledge about causal mechanisms and supporting translation between natural language and formal methods, LLMs open new frontiers for advancing the research, practice, and adoption of causality.
Language Model Decoding as Likelihood-Utility Alignment
Oct 13, 2022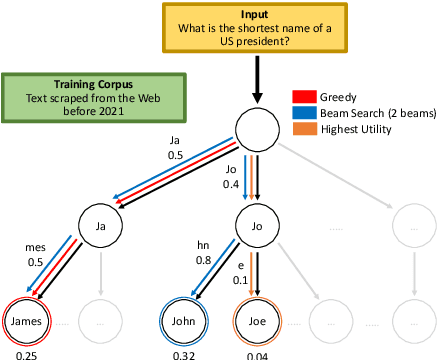

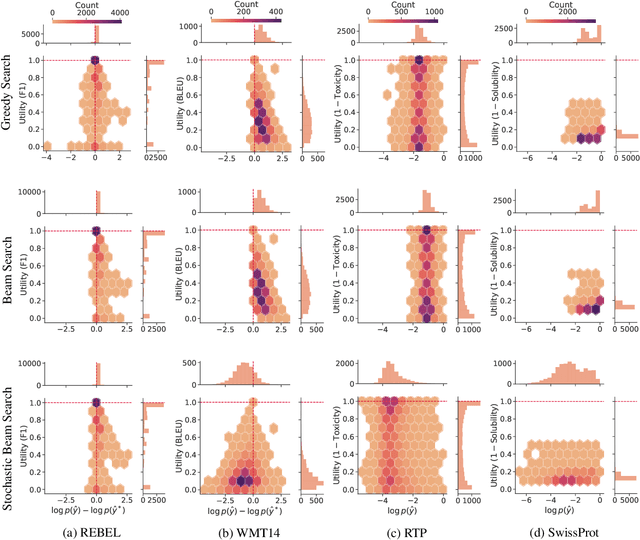
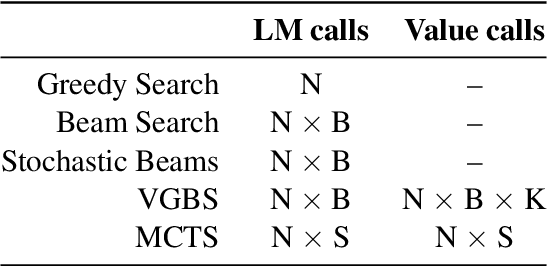
A critical component of a successful language generation pipeline is the decoding algorithm. However, the general principles that should guide the choice of decoding algorithm remain unclear. Previous works only compare decoding algorithms in narrow scenarios and their findings do not generalize across tasks. To better structure the discussion, we introduce a taxonomy that groups decoding strategies based on their implicit assumptions about how well the model's likelihood is aligned with the task-specific notion of utility. We argue that this taxonomy allows a broader view of the decoding problem and can lead to generalizable statements because it is grounded on the interplay between the decoding algorithms and the likelihood-utility misalignment. Specifically, by analyzing the correlation between the likelihood and the utility of predictions across a diverse set of tasks, we provide the first empirical evidence supporting the proposed taxonomy, and a set of principles to structure reasoning when choosing a decoding algorithm. Crucially, our analysis is the first one to relate likelihood-based decoding strategies with strategies that rely on external information such as value-guided methods and prompting, and covers the most diverse set of tasks up-to-date.
DoWhy: Addressing Challenges in Expressing and Validating Causal Assumptions
Aug 27, 2021
Estimation of causal effects involves crucial assumptions about the data-generating process, such as directionality of effect, presence of instrumental variables or mediators, and whether all relevant confounders are observed. Violation of any of these assumptions leads to significant error in the effect estimate. However, unlike cross-validation for predictive models, there is no global validator method for a causal estimate. As a result, expressing different causal assumptions formally and validating them (to the extent possible) becomes critical for any analysis. We present DoWhy, a framework that allows explicit declaration of assumptions through a causal graph and provides multiple validation tests to check a subset of these assumptions. Our experience with DoWhy highlights a number of open questions for future research: developing new ways beyond causal graphs to express assumptions, the role of causal discovery in learning relevant parts of the graph, and developing validation tests that can better detect errors, both for average and conditional treatment effects. DoWhy is available at https://github.com/microsoft/dowhy.
Formation of Social Ties Influences Food Choice: A Campus-Wide Longitudinal Study
Feb 17, 2021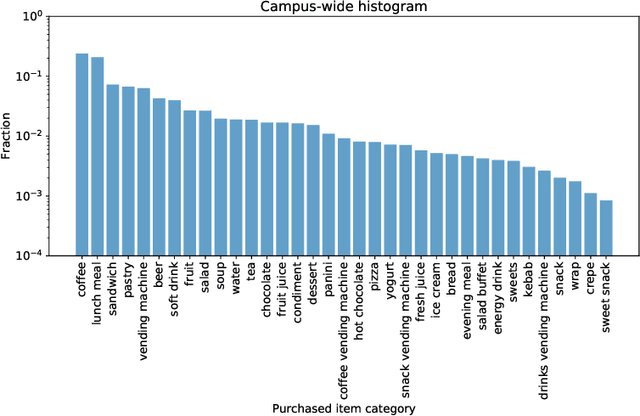
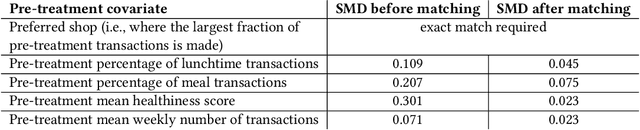
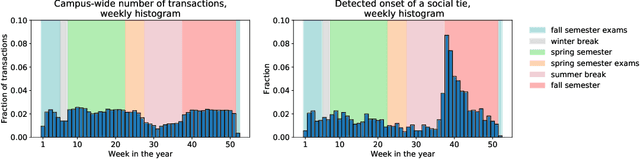
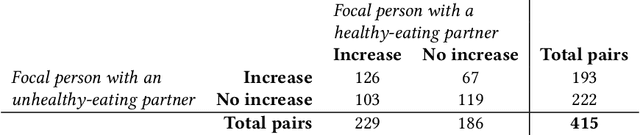
Nutrition is a key determinant of long-term health, and social influence has long been theorized to be a key determinant of nutrition. It has been difficult to quantify the postulated role of social influence on nutrition using traditional methods such as surveys, due to the typically small scale and short duration of studies. To overcome these limitations, we leverage a novel source of data: logs of 38 million food purchases made over an 8-year period on the Ecole Polytechnique Federale de Lausanne (EPFL) university campus, linked to anonymized individuals via the smartcards used to make on-campus purchases. In a longitudinal observational study, we ask: How is a person's food choice affected by eating with someone else whose own food choice is healthy vs. unhealthy? To estimate causal effects from the passively observed log data, we control confounds in a matched quasi-experimental design: we identify focal users who at first do not have any regular eating partners but then start eating with a fixed partner regularly, and we match focal users into comparison pairs such that paired users are nearly identical with respect to covariates measured before acquiring the partner, where the two focal users' new eating partners diverge in the healthiness of their respective food choice. A difference-in-differences analysis of the paired data yields clear evidence of social influence: focal users acquiring a healthy-eating partner change their habits significantly more toward healthy foods than focal users acquiring an unhealthy-eating partner. We further identify foods whose purchase frequency is impacted significantly by the eating partner's healthiness of food choice. Beyond the main results, the work demonstrates the utility of passively sensed food purchase logs for deriving insights, with the potential of informing the design of public health interventions and food offerings.
Causal Inference in the Presence of Interference in Sponsored Search Advertising
Oct 15, 2020


In classical causal inference, inferring cause-effect relations from data relies on the assumption that units are independent and identically distributed. This assumption is violated in settings where units are related through a network of dependencies. An example of such a setting is ad placement in sponsored search advertising, where the clickability of a particular ad is potentially influenced by where it is placed and where other ads are placed on the search result page. In such scenarios, confounding arises due to not only the individual ad-level covariates but also the placements and covariates of other ads in the system. In this paper, we leverage the language of causal inference in the presence of interference to model interactions among the ads. Quantification of such interactions allows us to better understand the click behavior of users, which in turn impacts the revenue of the host search engine and enhances user satisfaction. We illustrate the utility of our formalization through experiments carried out on the ad placement system of the Bing search engine.