 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization
Aug 06, 2025



Tokenization is the first -- and often least scrutinized -- step of most NLP pipelines. Standard algorithms for learning tokenizers rely on frequency-based objectives, which favor languages dominant in the training data and consequently leave lower-resource languages with tokenizations that are disproportionately longer, morphologically implausible, or even riddled with <UNK> placeholders. This phenomenon ultimately amplifies computational and financial inequalities between users from different language backgrounds. To remedy this, we introduce Parity-aware Byte Pair Encoding (BPE), a variant of the widely-used BPE algorithm. At every merge step, Parity-aware BPE maximizes the compression gain of the currently worst-compressed language, trading a small amount of global compression for cross-lingual parity. We find empirically that Parity-aware BPE leads to more equitable token counts across languages, with negligible impact on global compression rate and no substantial effect on language-model performance in downstream tasks.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Creativity in AI: Progresses and Challenges
Oct 22, 2024



Creativity is the ability to produce novel, useful, and surprising ideas, and has been widely studied as a crucial aspect of human cognition. Machine creativity on the other hand has been a long-standing challenge. With the rise of advanced generative AI, there has been renewed interest and debate regarding AI's creative capabilities. Therefore, it is imperative to revisit the state of creativity in AI and identify key progresses and remaining challenges. In this work, we survey leading works studying the creative capabilities of AI systems, focusing on creative problem-solving, linguistic, artistic, and scientific creativity. Our review suggests that while the latest AI models are largely capable of producing linguistically and artistically creative outputs such as poems, images, and musical pieces, they struggle with tasks that require creative problem-solving, abstract thinking and compositionality and their generations suffer from a lack of diversity, originality, long-range incoherence and hallucinations. We also discuss key questions concerning copyright and authorship issues with generative models. Furthermore, we highlight the need for a comprehensive evaluation of creativity that is process-driven and considers several dimensions of creativity. Finally, we propose future research directions to improve the creativity of AI outputs, drawing inspiration from cognitive science and psychology.
Entity Insertion in Multilingual Linked Corpora: The Case of Wikipedia
Oct 05, 2024

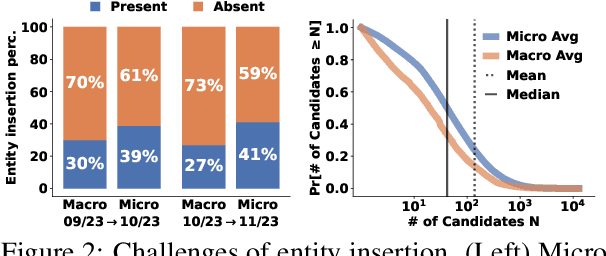

Links are a fundamental part of information networks, turning isolated pieces of knowledge into a network of information that is much richer than the sum of its parts. However, adding a new link to the network is not trivial: it requires not only the identification of a suitable pair of source and target entities but also the understanding of the content of the source to locate a suitable position for the link in the text. The latter problem has not been addressed effectively, particularly in the absence of text spans in the source that could serve as anchors to insert a link to the target entity. To bridge this gap, we introduce and operationalize the task of entity insertion in information networks. Focusing on the case of Wikipedia, we empirically show that this problem is, both, relevant and challenging for editors. We compile a benchmark dataset in 105 languages and develop a framework for entity insertion called LocEI (Localized Entity Insertion) and its multilingual variant XLocEI. We show that XLocEI outperforms all baseline models (including state-of-the-art prompt-based ranking with LLMs such as GPT-4) and that it can be applied in a zero-shot manner on languages not seen during training with minimal performance drop. These findings are important for applying entity insertion models in practice, e.g., to support editors in adding links across the more than 300 language versions of Wikipedia.
A Logical Fallacy-Informed Framework for Argument Generation
Aug 07, 2024

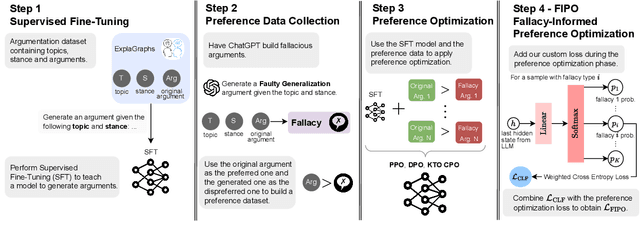
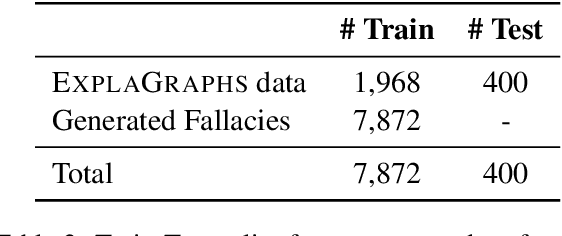
Despite the remarkable performance of Large Language Models (LLMs), they still struggle with generating logically sound arguments, resulting in potential risks such as spreading misinformation. An important factor contributing to LLMs' suboptimal performance in generating coherent arguments is their oversight of logical fallacies. To address this issue, we introduce FIPO, a fallacy-informed framework that leverages preference optimization methods to steer LLMs toward logically sound arguments. FIPO includes a classification loss, to capture the fine-grained information on fallacy categories. Our results on argumentation datasets show that our method reduces the fallacy errors by up to 17.5%. Furthermore, our human evaluation results indicate that the quality of the generated arguments by our method significantly outperforms the fine-tuned baselines, as well as prior preference optimization methods, such as DPO. These findings highlight the importance of ensuring models are aware of logical fallacies for effective argument generation.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning
Feb 23, 2024Large language models (LLMs) have been shown to perform better when asked to reason step-by-step before answering a question. However, it is unclear to what degree the model's final answer is faithful to the stated reasoning steps. In this paper, we perform a causal mediation analysis on twelve LLMs to examine how intermediate reasoning steps generated by the LLM influence the final outcome and find that LLMs do not reliably use their intermediate reasoning steps when generating an answer. To address this issue, we introduce FRODO, a framework to tailor small-sized LMs to generate correct reasoning steps and robustly reason over these steps. FRODO consists of an inference module that learns to generate correct reasoning steps using an implicit causal reward function and a reasoning module that learns to faithfully reason over these intermediate inferences using a counterfactual and causal preference objective. Our experiments show that FRODO significantly outperforms four competitive baselines. Furthermore, FRODO improves the robustness and generalization ability of the reasoning LM, yielding higher performance on out-of-distribution test sets. Finally, we find that FRODO's rationales are more faithful to its final answer predictions than standard supervised fine-tuning.
δ-CAUSAL: Exploring Defeasibility in Causal Reasoning
Jan 06, 2024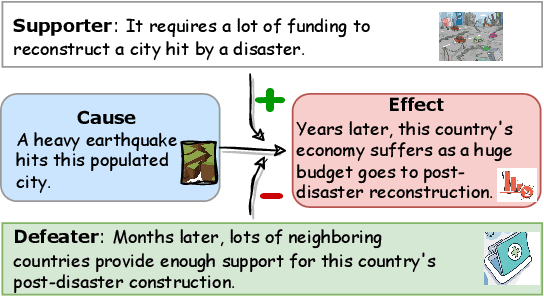

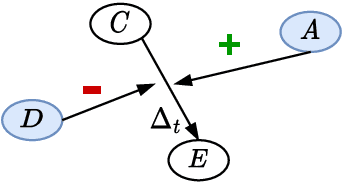

Defeasibility in causal reasoning implies that the causal relationship between cause and effect can be strengthened or weakened. Namely, the causal strength between cause and effect should increase or decrease with the incorporation of strengthening arguments (supporters) or weakening arguments (defeaters), respectively. However, existing works ignore defeasibility in causal reasoning and fail to evaluate existing causal strength metrics in defeasible settings. In this work, we present {\delta}-CAUSAL, the first benchmark dataset for studying defeasibility in causal reasoning. {\delta}-CAUSAL includes around 11K events spanning ten domains, featuring defeasible causality pairs, i.e., cause-effect pairs accompanied by supporters and defeaters. We further show current causal strength metrics fail to reflect the change of causal strength with the incorporation of supporters or defeaters in {\delta}-CAUSAL. To this end, we propose CESAR (Causal Embedding aSsociation with Attention Rating), a metric that measures causal strength based on token-level causal relationships. CESAR achieves a significant 69.7% relative improvement over existing metrics, increasing from 47.2% to 80.1% in capturing the causal strength change brought by supporters and defeaters. We further demonstrate even Large Language Models (LLMs) like GPT-3.5 still lag 4.5 and 10.7 points behind humans in generating supporters and defeaters, emphasizing the challenge posed by {\delta}-CAUSAL.
CRAB: Assessing the Strength of Causal Relationships Between Real-world Events
Nov 07, 2023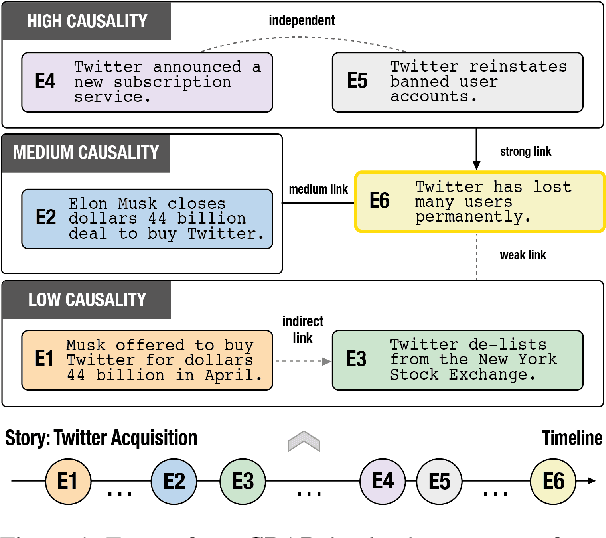
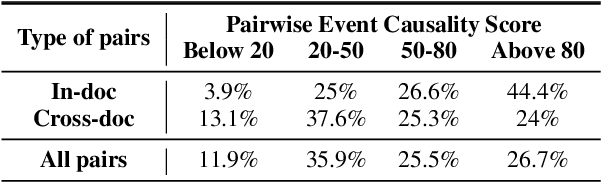
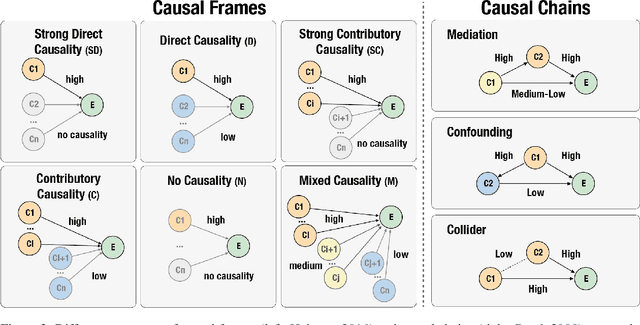
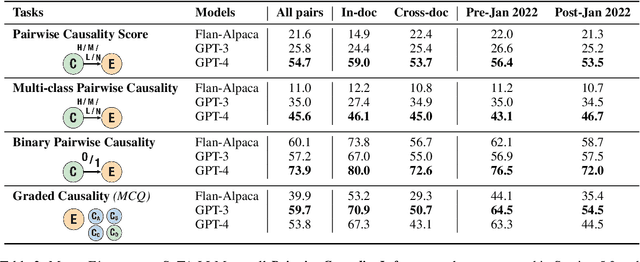
Understanding narratives requires reasoning about the cause-and-effect relationships between events mentioned in the text. While existing foundation models yield impressive results in many NLP tasks requiring reasoning, it is unclear whether they understand the complexity of the underlying network of causal relationships of events in narratives. In this work, we present CRAB, a new Causal Reasoning Assessment Benchmark designed to evaluate causal understanding of events in real-world narratives. CRAB contains fine-grained, contextual causality annotations for ~2.7K pairs of real-world events that describe various newsworthy event timelines (e.g., the acquisition of Twitter by Elon Musk). Using CRAB, we measure the performance of several large language models, demonstrating that most systems achieve poor performance on the task. Motivated by classical causal principles, we also analyze the causal structures of groups of events in CRAB, and find that models perform worse on causal reasoning when events are derived from complex causal structures compared to simple linear causal chains. We make our dataset and code available to the research community.
CRoW: Benchmarking Commonsense Reasoning in Real-World Tasks
Oct 23, 2023Recent efforts in natural language processing (NLP) commonsense reasoning research have yielded a considerable number of new datasets and benchmarks. However, most of these datasets formulate commonsense reasoning challenges in artificial scenarios that are not reflective of the tasks which real-world NLP systems are designed to solve. In this work, we present CRoW, a manually-curated, multi-task benchmark that evaluates the ability of models to apply commonsense reasoning in the context of six real-world NLP tasks. CRoW is constructed using a multi-stage data collection pipeline that rewrites examples from existing datasets using commonsense-violating perturbations. We use CRoW to study how NLP systems perform across different dimensions of commonsense knowledge, such as physical, temporal, and social reasoning. We find a significant performance gap when NLP systems are evaluated on CRoW compared to humans, showcasing that commonsense reasoning is far from being solved in real-world task settings. We make our dataset and leaderboard available to the research community at https://github.com/mismayil/crow.