 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Insertion in Multilingual Linked Corpora: The Case of Wikipedia
Oct 05, 2024

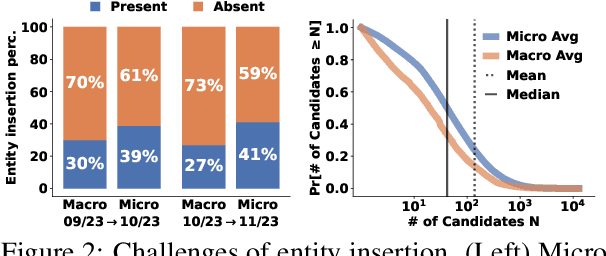

Links are a fundamental part of information networks, turning isolated pieces of knowledge into a network of information that is much richer than the sum of its parts. However, adding a new link to the network is not trivial: it requires not only the identification of a suitable pair of source and target entities but also the understanding of the content of the source to locate a suitable position for the link in the text. The latter problem has not been addressed effectively, particularly in the absence of text spans in the source that could serve as anchors to insert a link to the target entity. To bridge this gap, we introduce and operationalize the task of entity insertion in information networks. Focusing on the case of Wikipedia, we empirically show that this problem is, both, relevant and challenging for editors. We compile a benchmark dataset in 105 languages and develop a framework for entity insertion called LocEI (Localized Entity Insertion) and its multilingual variant XLocEI. We show that XLocEI outperforms all baseline models (including state-of-the-art prompt-based ranking with LLMs such as GPT-4) and that it can be applied in a zero-shot manner on languages not seen during training with minimal performance drop. These findings are important for applying entity insertion models in practice, e.g., to support editors in adding links across the more than 300 language versions of Wikipedia.
An Open Multilingual System for Scoring Readability of Wikipedia
Jun 03, 2024



With over 60M articles, Wikipedia has become the largest platform for open and freely accessible knowledge. While it has more than 15B monthly visits, its content is believed to be inaccessible to many readers due to the lack of readability of its text. However, previous investigations of the readability of Wikipedia have been restricted to English only, and there are currently no systems supporting the automatic readability assessment of the 300+ languages in Wikipedia. To bridge this gap, we develop a multilingual model to score the readability of Wikipedia articles. To train and evaluate this model, we create a novel multilingual dataset spanning 14 languages, by matching articles from Wikipedia to simplified Wikipedia and online children encyclopedias. We show that our model performs well in a zero-shot scenario, yielding a ranking accuracy of more than 80% across 14 languages and improving upon previous benchmarks. These results demonstrate the applicability of the model at scale for languages in which there is no ground-truth data available for model fine-tuning. Furthermore, we provide the first overview on the state of readability in Wikipedia beyond English.
Multilayer Networks for Text Analysis with Multiple Data Types
Jun 30, 2021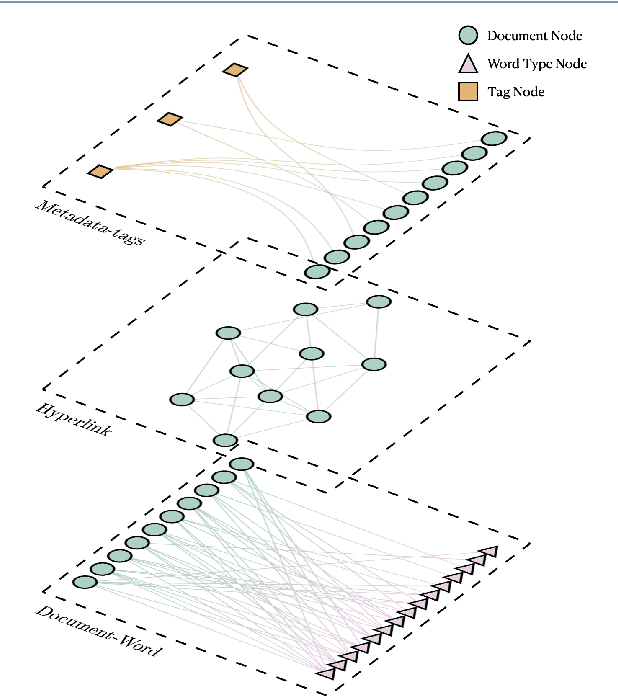
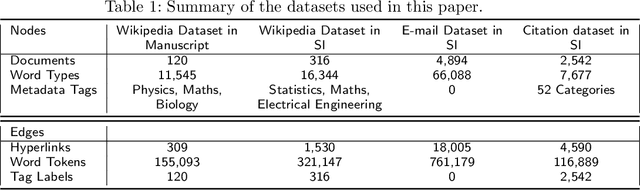
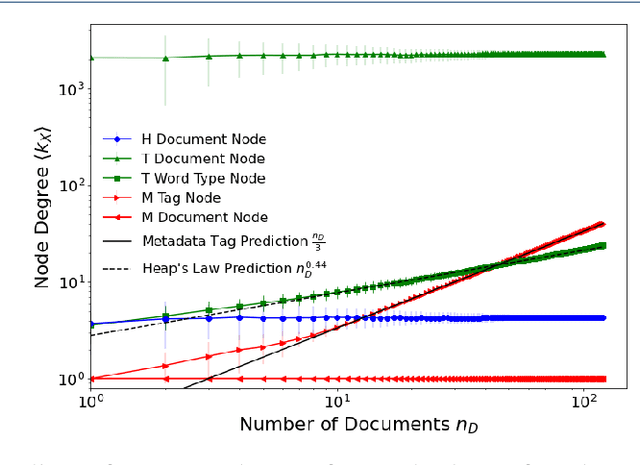

We are interested in the widespread problem of clustering documents and finding topics in large collections of written documents in the presence of metadata and hyperlinks. To tackle the challenge of accounting for these different types of datasets, we propose a novel framework based on Multilayer Networks and Stochastic Block Models. The main innovation of our approach over other techniques is that it applies the same non-parametric probabilistic framework to the different sources of datasets simultaneously. The key difference to other multilayer complex networks is the strong unbalance between the layers, with the average degree of different node types scaling differently with system size. We show that the latter observation is due to generic properties of text, such as Heaps' law, and strongly affects the inference of communities. We present and discuss the performance of our method in different datasets (hundreds of Wikipedia documents, thousands of scientific papers, and thousands of E-mails) showing that taking into account multiple types of information provides a more nuanced view on topic- and document-clusters and increases the ability to predict missing links.
* 17 pages, 6 figures
A new evaluation framework for topic modeling algorithms based on synthetic corpora
Jan 28, 2019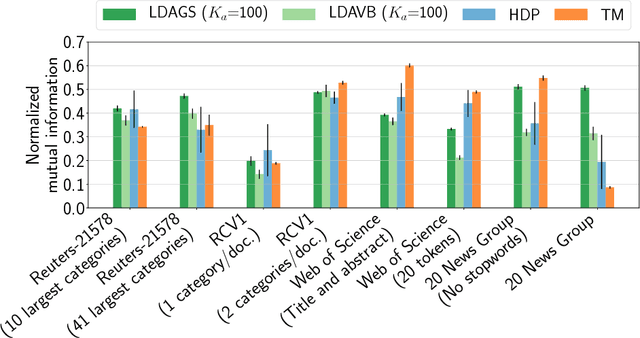
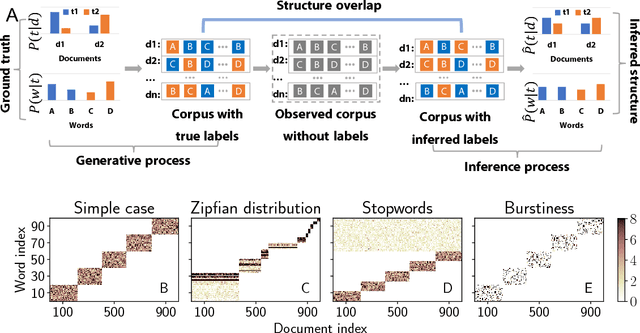
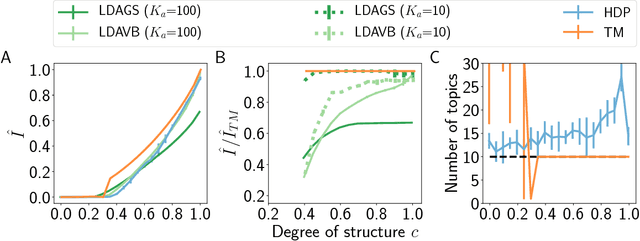
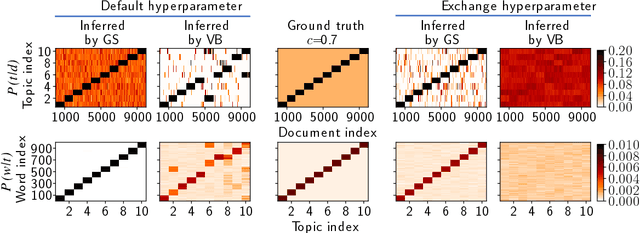
Topic models are in widespread use in natural language processing and beyond. Here, we propose a new framework for the evaluation of probabilistic topic modeling algorithms based on synthetic corpora containing an unambiguously defined ground truth topic structure. The major innovation of our approach is the ability to quantify the agreement between the planted and inferred topic structures by comparing the assigned topic labels at the level of the tokens. In experiments, our approach yields novel insights about the relative strengths of topic models as corpus characteristics vary, and the first evidence of an "undetectable phase" for topic models when the planted structure is weak. We also establish the practical relevance of the insights gained for synthetic corpora by predicting the performance of topic modeling algorithms in classification tasks in real-world corpora.
A standardized Project Gutenberg corpus for statistical analysis of natural language and quantitative linguistics
Dec 19, 2018
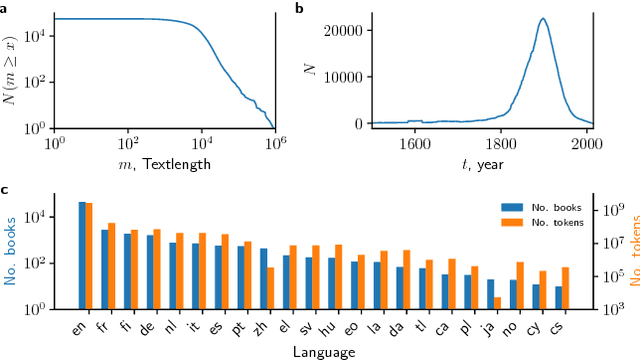
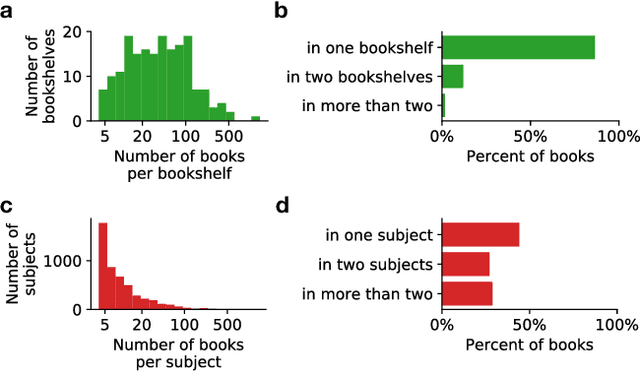
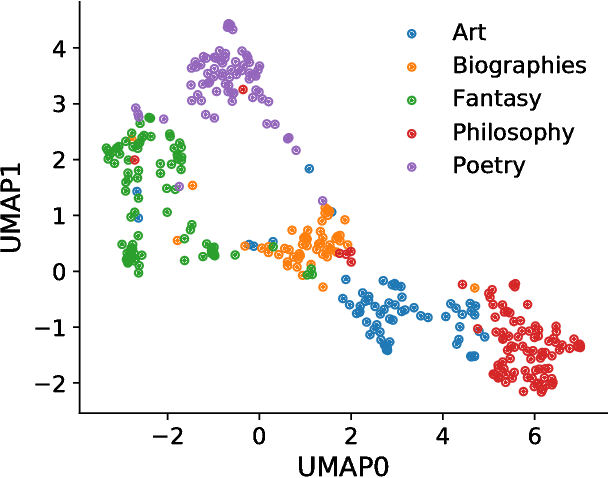
The use of Project Gutenberg (PG) as a text corpus has been extremely popular in statistical analysis of language for more than 25 years. However, in contrast to other major linguistic datasets of similar importance, no consensual full version of PG exists to date. In fact, most PG studies so far either consider only a small number of manually selected books, leading to potential biased subsets, or employ vastly different pre-processing strategies (often specified in insufficient details), raising concerns regarding the reproducibility of published results. In order to address these shortcomings, here we present the Standardized Project Gutenberg Corpus (SPGC), an open science approach to a curated version of the complete PG data containing more than 50,000 books and more than $3 \times 10^9$ word-tokens. Using different sources of annotated metadata, we not only provide a broad characterization of the content of PG, but also show different examples highlighting the potential of SPGC for investigating language variability across time, subjects, and authors. We publish our methodology in detail, the code to download and process the data, as well as the obtained corpus itself on 3 different levels of granularity (raw text, timeseries of word tokens, and counts of words). In this way, we provide a reproducible, pre-processed, full-size version of Project Gutenberg as a new scientific resource for corpus linguistics, natural language processing, and information retrieval.
A network approach to topic models
Jul 19, 2018One of the main computational and scientific challenges in the modern age is to extract useful information from unstructured texts. Topic models are one popular machine-learning approach which infers the latent topical structure of a collection of documents. Despite their success --- in particular of its most widely used variant called Latent Dirichlet Allocation (LDA) --- and numerous applications in sociology, history, and linguistics, topic models are known to suffer from severe conceptual and practical problems, e.g. a lack of justification for the Bayesian priors, discrepancies with statistical properties of real texts, and the inability to properly choose the number of topics. Here we obtain a fresh view on the problem of identifying topical structures by relating it to the problem of finding communities in complex networks. This is achieved by representing text corpora as bipartite networks of documents and words. By adapting existing community-detection methods -- using a stochastic block model (SBM) with non-parametric priors -- we obtain a more versatile and principled framework for topic modeling (e.g., it automatically detects the number of topics and hierarchically clusters both the words and documents). The analysis of artificial and real corpora demonstrates that our SBM approach leads to better topic models than LDA in terms of statistical model selection. More importantly, our work shows how to formally relate methods from community detection and topic modeling, opening the possibility of cross-fertilization between these two fields.
* 22 pages, 10 figures, code available at https://topsbm.github.io/
Generalized Entropies and the Similarity of Texts
Nov 11, 2016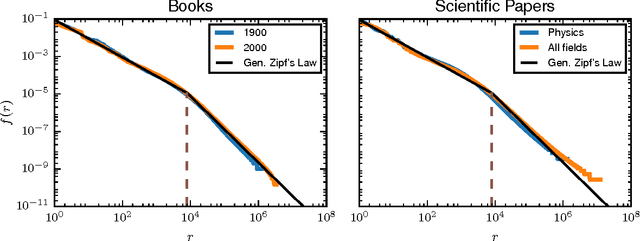
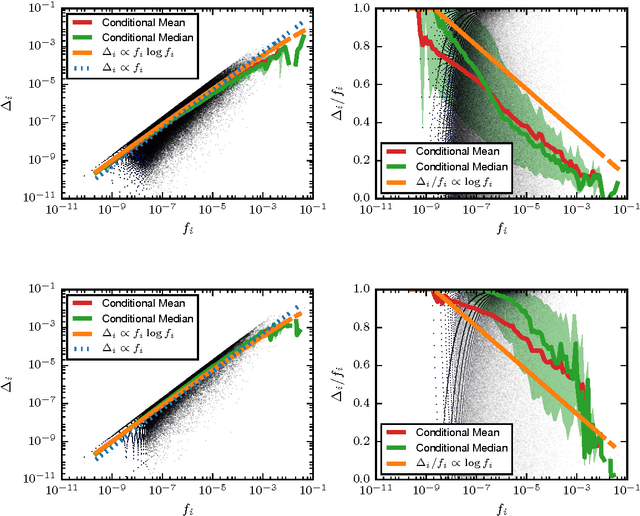
We show how generalized Gibbs-Shannon entropies can provide new insights on the statistical properties of texts. The universal distribution of word frequencies (Zipf's law) implies that the generalized entropies, computed at the word level, are dominated by words in a specific range of frequencies. Here we show that this is the case not only for the generalized entropies but also for the generalized (Jensen-Shannon) divergences, used to compute the similarity between different texts. This finding allows us to identify the contribution of specific words (and word frequencies) for the different generalized entropies and also to estimate the size of the databases needed to obtain a reliable estimation of the divergences. We test our results in large databases of books (from the Google n-gram database) and scientific papers (indexed by Web of Science).
* 13 pages, 6 figures; Results presented at the StatPhys-2016 meeting in Lyon
Similarity of symbol frequency distributions with heavy tails
Apr 15, 2016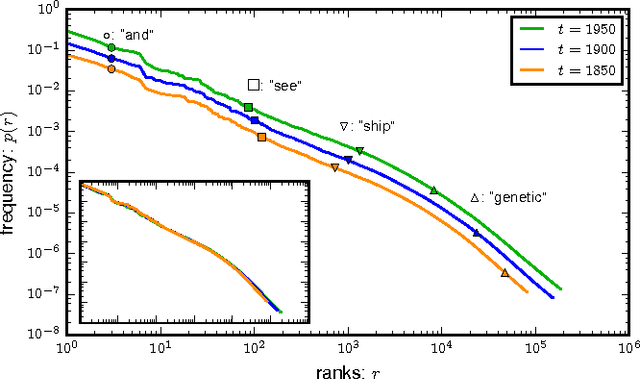
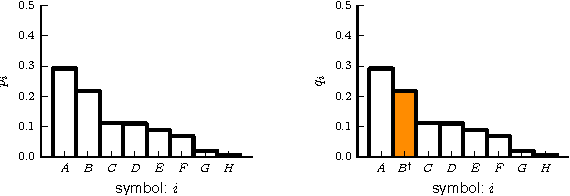

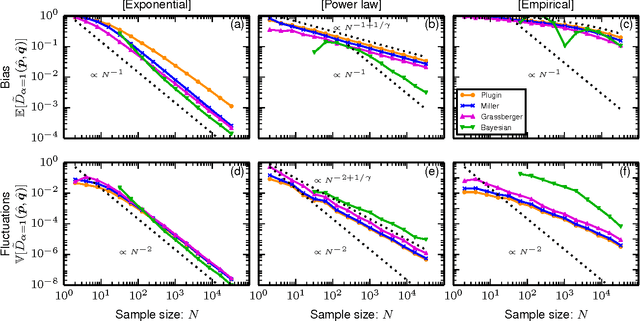
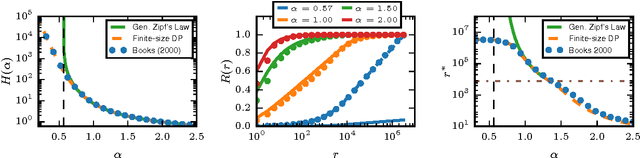
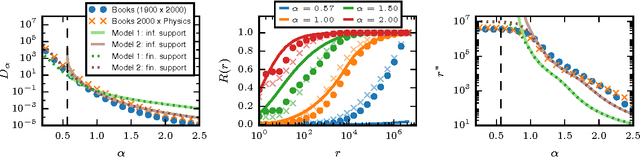
Quantifying the similarity between symbolic sequences is a traditional problem in Information Theory which requires comparing the frequencies of symbols in different sequences. In numerous modern applications, ranging from DNA over music to texts, the distribution of symbol frequencies is characterized by heavy-tailed distributions (e.g., Zipf's law). The large number of low-frequency symbols in these distributions poses major difficulties to the estimation of the similarity between sequences, e.g., they hinder an accurate finite-size estimation of entropies. Here we show analytically how the systematic (bias) and statistical (fluctuations) errors in these estimations depend on the sample size~$N$ and on the exponent~$\gamma$ of the heavy-tailed distribution. Our results are valid for the Shannon entropy $(\alpha=1)$, its corresponding similarity measures (e.g., the Jensen-Shanon divergence), and also for measures based on the generalized entropy of order $\alpha$. For small $\alpha$'s, including $\alpha=1$, the errors decay slower than the $1/N$-decay observed in short-tailed distributions. For $\alpha$ larger than a critical value $\alpha^* = 1+1/\gamma \leq 2$, the $1/N$-decay is recovered. We show the practical significance of our results by quantifying the evolution of the English language over the last two centuries using a complete $\alpha$-spectrum of measures. We find that frequent words change more slowly than less frequent words and that $\alpha=2$ provides the most robust measure to quantify language change.
* 13 pages, 7 figures
Statistical laws in linguistics
Feb 11, 2015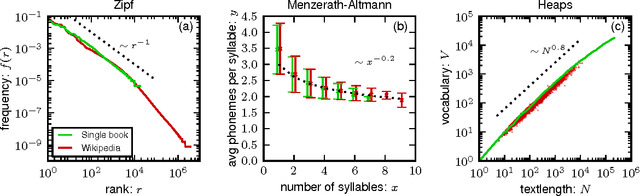
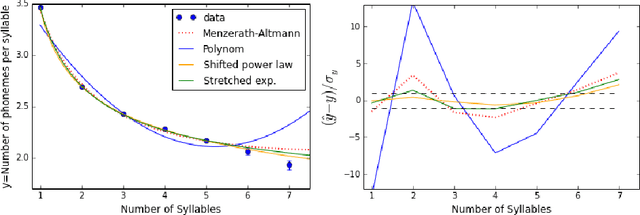
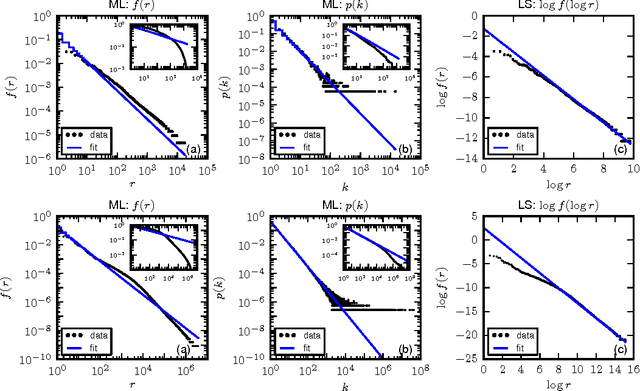
Zipf's law is just one out of many universal laws proposed to describe statistical regularities in language. Here we review and critically discuss how these laws can be statistically interpreted, fitted, and tested (falsified). The modern availability of large databases of written text allows for tests with an unprecedent statistical accuracy and also a characterization of the fluctuations around the typical behavior. We find that fluctuations are usually much larger than expected based on simplifying statistical assumptions (e.g., independence and lack of correlations between observations).These simplifications appear also in usual statistical tests so that the large fluctuations can be erroneously interpreted as a falsification of the law. Instead, here we argue that linguistic laws are only meaningful (falsifiable) if accompanied by a model for which the fluctuations can be computed (e.g., a generative model of the text). The large fluctuations we report show that the constraints imposed by linguistic laws on the creativity process of text generation are not as tight as one could expect.
Scaling laws and fluctuations in the statistics of word frequencies
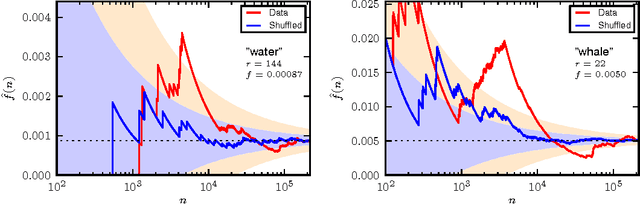
Nov 04, 2014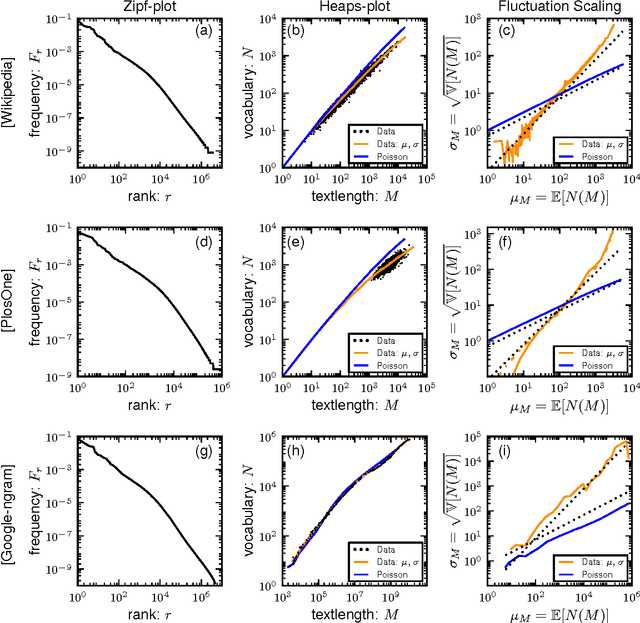
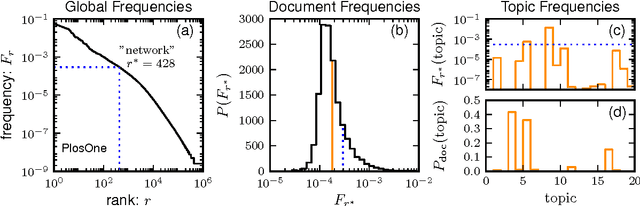
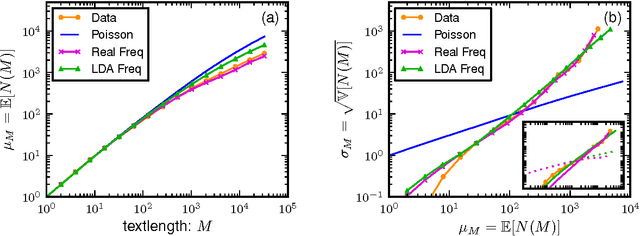
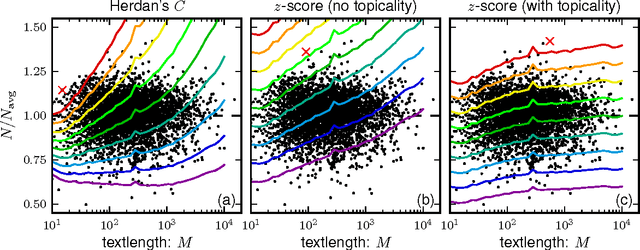
In this paper we combine statistical analysis of large text databases and simple stochastic models to explain the appearance of scaling laws in the statistics of word frequencies. Besides the sublinear scaling of the vocabulary size with database size (Heaps' law), here we report a new scaling of the fluctuations around this average (fluctuation scaling analysis). We explain both scaling laws by modeling the usage of words by simple stochastic processes in which the overall distribution of word-frequencies is fat tailed (Zipf's law) and the frequency of a single word is subject to fluctuations across documents (as in topic models). In this framework, the mean and the variance of the vocabulary size can be expressed as quenched averages, implying that: i) the inhomogeneous dissemination of words cause a reduction of the average vocabulary size in comparison to the homogeneous case, and ii) correlations in the co-occurrence of words lead to an increase in the variance and the vocabulary size becomes a non-self-averaging quantity. We address the implications of these observations to the measurement of lexical richness. We test our results in three large text databases (Google-ngram, Enlgish Wikipedia, and a collection of scientific articles).
* 19 pages, 4 figures