 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilayer Networks for Text Analysis with Multiple Data Types
Jun 30, 2021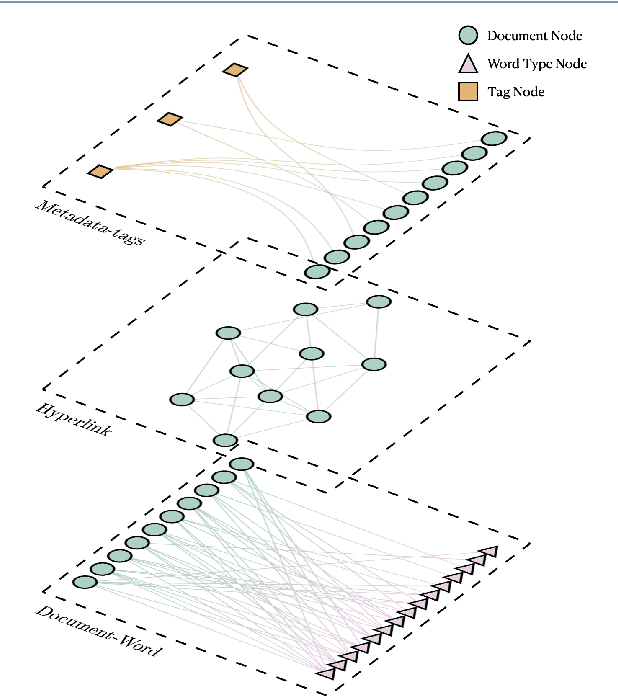
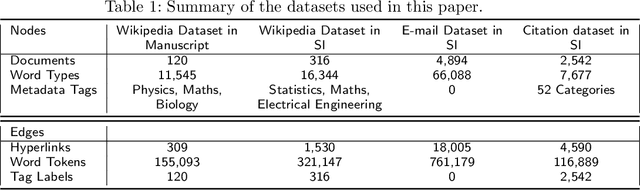
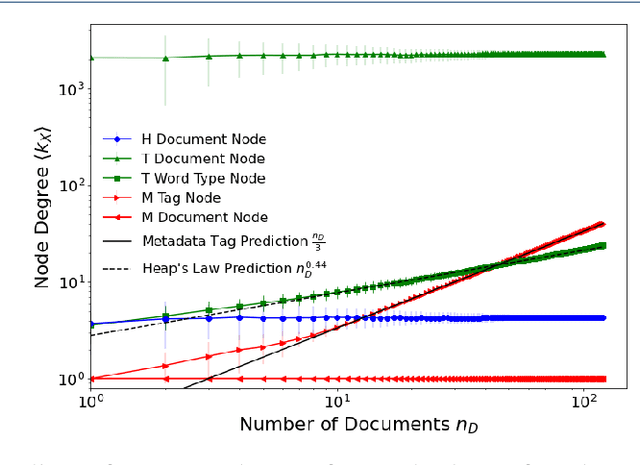

We are interested in the widespread problem of clustering documents and finding topics in large collections of written documents in the presence of metadata and hyperlinks. To tackle the challenge of accounting for these different types of datasets, we propose a novel framework based on Multilayer Networks and Stochastic Block Models. The main innovation of our approach over other techniques is that it applies the same non-parametric probabilistic framework to the different sources of datasets simultaneously. The key difference to other multilayer complex networks is the strong unbalance between the layers, with the average degree of different node types scaling differently with system size. We show that the latter observation is due to generic properties of text, such as Heaps' law, and strongly affects the inference of communities. We present and discuss the performance of our method in different datasets (hundreds of Wikipedia documents, thousands of scientific papers, and thousands of E-mails) showing that taking into account multiple types of information provides a more nuanced view on topic- and document-clusters and increases the ability to predict missing links.
* 17 pages, 6 figures