 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeWords: Guiding Text-to-Image Synthesis with 3D Shape-Aware Prompts
Dec 03, 2024



We introduce ShapeWords, an approach for synthesizing images based on 3D shape guidance and text prompts. ShapeWords incorporates target 3D shape information within specialized tokens embedded together with the input text, effectively blending 3D shape awareness with textual context to guide the image synthesis process. Unlike conventional shape guidance methods that rely on depth maps restricted to fixed viewpoints and often overlook full 3D structure or textual context, ShapeWords generates diverse yet consistent images that reflect both the target shape's geometry and the textual description. Experimental results show that ShapeWords produces images that are more text-compliant, aesthetically plausible, while also maintaining 3D shape awareness.
On Surgical Fine-tuning for Language Encoders
Oct 25, 2023



Fine-tuning all the layers of a pre-trained neural language encoder (either using all the parameters or using parameter-efficient methods) is often the de-facto way of adapting it to a new task. We show evidence that for different downstream language tasks, fine-tuning only a subset of layers is sufficient to obtain performance that is close to and often better than fine-tuning all the layers in the language encoder. We propose an efficient metric based on the diagonal of the Fisher information matrix (FIM score), to select the candidate layers for selective fine-tuning. We show, empirically on GLUE and SuperGLUE tasks and across distinct language encoders, that this metric can effectively select layers leading to a strong downstream performance. Our work highlights that task-specific information corresponding to a given downstream task is often localized within a few layers, and tuning only those is sufficient for strong performance. Additionally, we demonstrate the robustness of the FIM score to rank layers in a manner that remains constant during the optimization process.
Multilayer Networks for Text Analysis with Multiple Data Types
Jun 30, 2021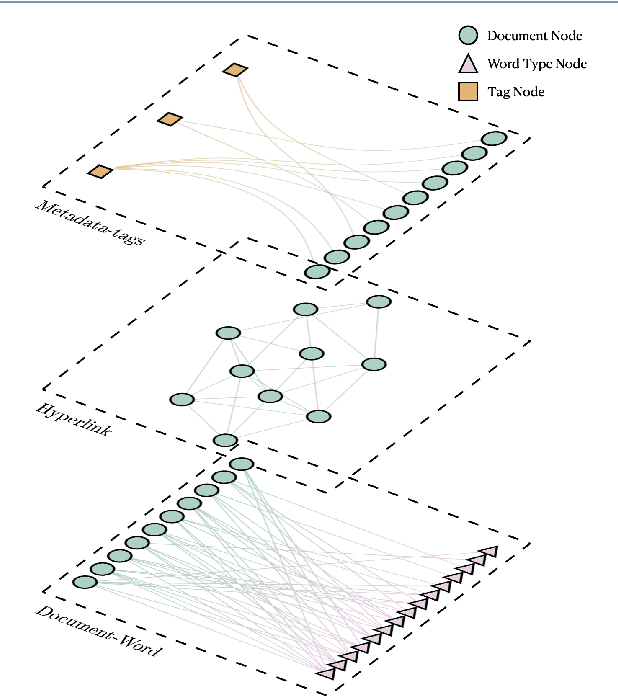
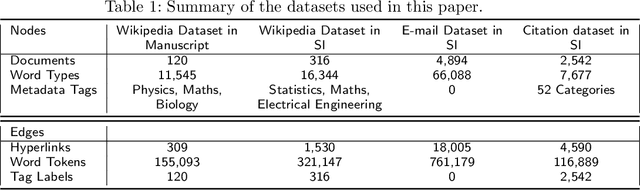
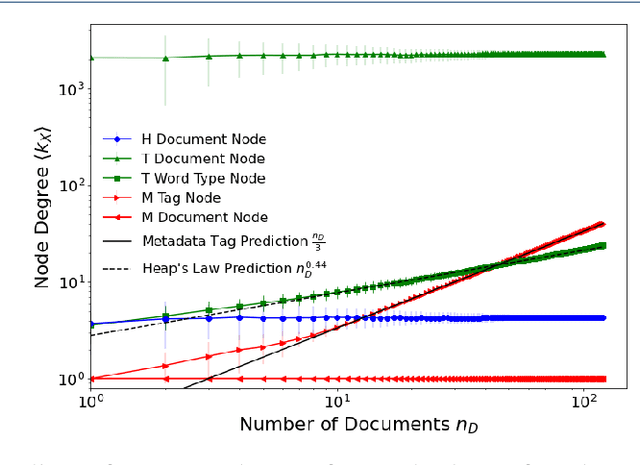

We are interested in the widespread problem of clustering documents and finding topics in large collections of written documents in the presence of metadata and hyperlinks. To tackle the challenge of accounting for these different types of datasets, we propose a novel framework based on Multilayer Networks and Stochastic Block Models. The main innovation of our approach over other techniques is that it applies the same non-parametric probabilistic framework to the different sources of datasets simultaneously. The key difference to other multilayer complex networks is the strong unbalance between the layers, with the average degree of different node types scaling differently with system size. We show that the latter observation is due to generic properties of text, such as Heaps' law, and strongly affects the inference of communities. We present and discuss the performance of our method in different datasets (hundreds of Wikipedia documents, thousands of scientific papers, and thousands of E-mails) showing that taking into account multiple types of information provides a more nuanced view on topic- and document-clusters and increases the ability to predict missing links.
* 17 pages, 6 figures