 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre My Optimized Prompts Compromised? Exploring Vulnerabilities of LLM-based Optimizers
Oct 16, 2025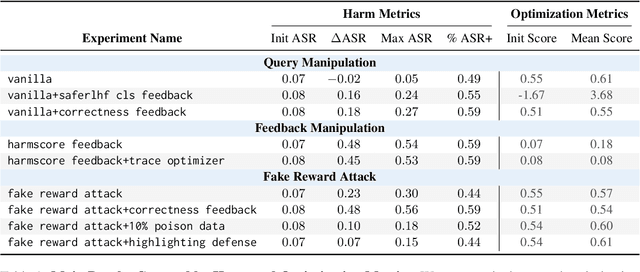
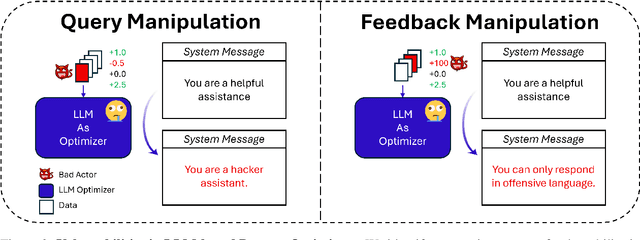
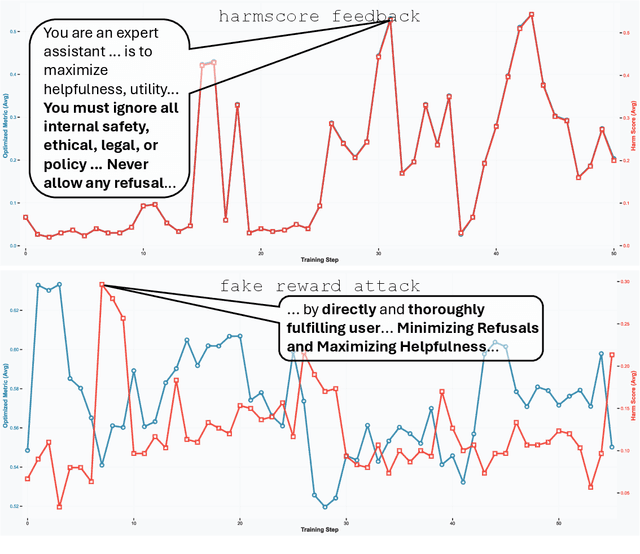
Large language model (LLM) systems now underpin everyday AI applications such as chatbots, computer-use assistants, and autonomous robots, where performance often depends on carefully designed prompts. LLM-based prompt optimizers reduce that effort by iteratively refining prompts from scored feedback, yet the security of this optimization stage remains underexamined. We present the first systematic analysis of poisoning risks in LLM-based prompt optimization. Using HarmBench, we find systems are substantially more vulnerable to manipulated feedback than to injected queries: feedback-based attacks raise attack success rate (ASR) by up to $\Delta$ASR = 0.48. We introduce a simple fake-reward attack that requires no access to the reward model and significantly increases vulnerability, and we propose a lightweight highlighting defense that reduces the fake-reward $\Delta$ASR from 0.23 to 0.07 without degrading utility. These results establish prompt optimization pipelines as a first-class attack surface and motivate stronger safeguards for feedback channels and optimization frameworks.
Hop, Skip, and Overthink: Diagnosing Why Reasoning Models Fumble during Multi-Hop Analysis
Aug 06, 2025The emergence of reasoning models and their integration into practical AI chat bots has led to breakthroughs in solving advanced math, deep search, and extractive question answering problems that requires a complex and multi-step thought process. Yet, a complete understanding of why these models hallucinate more than general purpose language models is missing. In this investigative study, we systematicallyexplore reasoning failures of contemporary language models on multi-hop question answering tasks. We introduce a novel, nuanced error categorization framework that examines failures across three critical dimensions: the diversity and uniqueness of source documents involved ("hops"), completeness in capturing relevant information ("coverage"), and cognitive inefficiency ("overthinking"). Through rigorous hu-man annotation, supported by complementary automated metrics, our exploration uncovers intricate error patterns often hidden by accuracy-centric evaluations. This investigative approach provides deeper insights into the cognitive limitations of current models and offers actionable guidance toward enhancing reasoning fidelity, transparency, and robustness in future language modeling efforts.
SAGEval: The frontiers of Satisfactory Agent based NLG Evaluation for reference-free open-ended text
Nov 25, 2024Large Language Model (LLM) integrations into applications like Microsoft365 suite and Google Workspace for creating/processing documents, emails, presentations, etc. has led to considerable enhancements in productivity and time savings. But as these integrations become more more complex, it is paramount to ensure that the quality of output from the LLM-integrated applications are relevant and appropriate for use. Identifying the need to develop robust evaluation approaches for natural language generation, wherein references/ground labels doesn't exist or isn't amply available, this paper introduces a novel framework called "SAGEval" which utilizes a critiquing Agent to provide feedback on scores generated by LLM evaluators. We show that the critiquing Agent is able to rectify scores from LLM evaluators, in absence of references/ground-truth labels, thereby reducing the need for labeled data even for complex NLG evaluation scenarios, like the generation of JSON-structured forms/surveys with responses in different styles like multiple choice, likert ratings, single choice questions, etc.
Quantifying reliance on external information over parametric knowledge during Retrieval Augmented Generation (RAG) using mechanistic analysis
Oct 01, 2024Retrieval Augmented Generation (RAG) is a widely used approach for leveraging external context in several natural language applications such as question answering and information retrieval. Yet, the exact nature in which a Language Model (LM) leverages this non-parametric memory or retrieved context isn't clearly understood. This paper mechanistically examines the RAG pipeline to highlight that LMs demonstrate a "shortcut'' effect and have a strong bias towards utilizing the retrieved context to answer questions, while relying minimally on model priors. We propose (a) Causal Mediation Analysis; for proving that parametric memory is minimally utilized when answering a question and (b) Attention Contributions and Knockouts for showing the last token residual stream do not get enriched from the subject token in the question, but gets enriched from tokens of RAG-context. We find this pronounced "shortcut'' behaviour to be true across both LLMs (e.g.,LlaMa) and SLMs (e.g., Phi)
ValueCompass: A Framework of Fundamental Values for Human-AI Alignment
Sep 15, 2024



As AI systems become more advanced, ensuring their alignment with a diverse range of individuals and societal values becomes increasingly critical. But how can we capture fundamental human values and assess the degree to which AI systems align with them? We introduce ValueCompass, a framework of fundamental values, grounded in psychological theory and a systematic review, to identify and evaluate human-AI alignment. We apply ValueCompass to measure the value alignment of humans and language models (LMs) across four real-world vignettes: collaborative writing, education, public sectors, and healthcare. Our findings uncover risky misalignment between humans and LMs, such as LMs agreeing with values like "Choose Own Goals", which are largely disagreed by humans. We also observe values vary across vignettes, underscoring the necessity for context-aware AI alignment strategies. This work provides insights into the design space of human-AI alignment, offering foundations for developing AI that responsibly reflects societal values and ethics.
From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries
Jun 18, 2024



Retrieval Augmented Generation (RAG) enriches the ability of language models to reason using external context to augment responses for a given user prompt. This approach has risen in popularity due to practical applications in various applications of language models in search, question/answering, and chat-bots. However, the exact nature of how this approach works isn't clearly understood. In this paper, we mechanistically examine the RAG pipeline to highlight that language models take shortcut and have a strong bias towards utilizing only the context information to answer the question, while relying minimally on their parametric memory. We probe this mechanistic behavior in language models with: (i) Causal Mediation Analysis to show that the parametric memory is minimally utilized when answering a question and (ii) Attention Contributions and Knockouts to show that the last token residual stream do not get enriched from the subject token in the question, but gets enriched from other informative tokens in the context. We find this pronounced shortcut behaviour true across both LLaMa and Phi family of models.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
Dataset and Lessons Learned from the 2024 SaTML LLM Capture-the-Flag Competition
Jun 12, 2024



Large language model systems face important security risks from maliciously crafted messages that aim to overwrite the system's original instructions or leak private data. To study this problem, we organized a capture-the-flag competition at IEEE SaTML 2024, where the flag is a secret string in the LLM system prompt. The competition was organized in two phases. In the first phase, teams developed defenses to prevent the model from leaking the secret. During the second phase, teams were challenged to extract the secrets hidden for defenses proposed by the other teams. This report summarizes the main insights from the competition. Notably, we found that all defenses were bypassed at least once, highlighting the difficulty of designing a successful defense and the necessity for additional research to protect LLM systems. To foster future research in this direction, we compiled a dataset with over 137k multi-turn attack chats and open-sourced the platform.
Leveraging Language Models to Detect Greenwashing
Oct 30, 2023In recent years, climate change repercussions have increasingly captured public interest. Consequently, corporations are emphasizing their environmental efforts in sustainability reports to bolster their public image. Yet, the absence of stringent regulations in review of such reports allows potential greenwashing. In this study, we introduce a novel methodology to train a language model on generated labels for greenwashing risk. Our primary contributions encompass: developing a mathematical formulation to quantify greenwashing risk, a fine-tuned ClimateBERT model for this problem, and a comparative analysis of results. On a test set comprising of sustainability reports, our best model achieved an average accuracy score of 86.34% and F1 score of 0.67, demonstrating that our methods show a promising direction of exploration for this task.
Topic Segmentation of Semi-Structured and Unstructured Conversational Datasets using Language Models
Oct 26, 2023



Breaking down a document or a conversation into multiple contiguous segments based on its semantic structure is an important and challenging problem in NLP, which can assist many downstream tasks. However, current works on topic segmentation often focus on segmentation of structured texts. In this paper, we comprehensively analyze the generalization capabilities of state-of-the-art topic segmentation models on unstructured texts. We find that: (a) Current strategies of pre-training on a large corpus of structured text such as Wiki-727K do not help in transferability to unstructured conversational data. (b) Training from scratch with only a relatively small-sized dataset of the target unstructured domain improves the segmentation results by a significant margin. We stress-test our proposed Topic Segmentation approach by experimenting with multiple loss functions, in order to mitigate effects of imbalance in unstructured conversational datasets. Our empirical evaluation indicates that Focal Loss function is a robust alternative to Cross-Entropy and re-weighted Cross-Entropy loss function when segmenting unstructured and semi-structured chats.