 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Research Evolve? Tracing Cross-Domain Trajectories in NLP, ML, and CV with Claim-Grounded Typed Citations
Jun 21, 2026How does research evolve, and what substrate would let us forecast where it goes next? Scientific progress is not simply a uniform accumulation of facts: ideas extend prior methods, address known limitations, realize proposed future directions, and sometimes dispute earlier claims. Existing citation graphs usually collapse these roles into a single homogeneous edge type, limiting how we can analyze scientific progress. We address this gap by proposing the SciTraj corpus, the first claim-grounded typed citation graph in which each edge is linked to the specific claim sentence that motivates it. Claim-bearing sentences are extracted from paper sections; four claim-driven relations are verified by NLI entailment against in-paper context, while two similarity-only relations are gated by abstract cosine and year-gap rules. SciTraj contains 32,559 papers from NLP, ML, and Vision (2015--2024), connected by 573,126 directed edges across six relation types, with NLI-verified claim seeds. Using SciTraj, we identify disciplinary siloing in typed citation flow and topic emergence concentrated in Vision and LLM-related work. The corpus also contains 287M typed trajectories of length $\geq 3$, covering 72.8% of papers, and supports a temporally split typed link-prediction benchmark. A year-shuffle falsifiability test separates temporal structure from year-correlated content, and a 3-annotator pilot reports $κ= 0.74$ with 79.9% precision.
Short-form Text Rewriting with Phi Silica
May 30, 2026Short-form text rewriting is a constrained variant of paraphrasing in which limited context and high semantic density leave little room for variation. While large language models perform well on general paraphrasing, small language models (SLMs) often struggle with semantic fidelity and hallucination robustness in short-form settings. In this work, we present an empirical study of adapting an SLM, Phi Silica, for short-form rewrite through dataset curation, prompt distillation, parameter-efficient fine-tuning, and evaluation. We curate a dataset of short presentation-style text from public slide decks and use GPT-5-chat both to generate rewrite supervision and to conduct LLM-as-a-judge evaluation. Our results show that finetuning improves semantic fidelity, reduces hallucinations, and increases preference win rate against GPT-5-chat rewrites. The findings suggest that targeted adaptation for SLMs can substantially narrow the gap to cloud models and provide practical guidance for adapting SLMs to precision-critical rewrite tasks.
Auto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation
Aug 07, 2025



The increasing adoption of foundation models as agents across diverse domains necessitates a robust evaluation framework. Current methods, such as LLM-as-a-Judge, focus only on final outputs, overlooking the step-by-step reasoning that drives agentic decision-making. Meanwhile, existing Agent-as-a-Judge systems, where one agent evaluates another's task completion, are typically designed for narrow, domain-specific settings. To address this gap, we propose a generalizable, modular framework for evaluating agent task completion independent of the task domain. The framework emulates human-like evaluation by decomposing tasks into sub-tasks and validating each step using available information, such as the agent's output and reasoning. Each module contributes to a specific aspect of the evaluation process, and their outputs are aggregated to produce a final verdict on task completion. We validate our framework by evaluating the Magentic-One Actor Agent on two benchmarks, GAIA and BigCodeBench. Our Judge Agent predicts task success with closer agreement to human evaluations, achieving 4.76% and 10.52% higher alignment accuracy, respectively, compared to the GPT-4o based LLM-as-a-Judge baseline. This demonstrates the potential of our proposed general-purpose evaluation framework.
SAGEval: The frontiers of Satisfactory Agent based NLG Evaluation for reference-free open-ended text
Nov 25, 2024Large Language Model (LLM) integrations into applications like Microsoft365 suite and Google Workspace for creating/processing documents, emails, presentations, etc. has led to considerable enhancements in productivity and time savings. But as these integrations become more more complex, it is paramount to ensure that the quality of output from the LLM-integrated applications are relevant and appropriate for use. Identifying the need to develop robust evaluation approaches for natural language generation, wherein references/ground labels doesn't exist or isn't amply available, this paper introduces a novel framework called "SAGEval" which utilizes a critiquing Agent to provide feedback on scores generated by LLM evaluators. We show that the critiquing Agent is able to rectify scores from LLM evaluators, in absence of references/ground-truth labels, thereby reducing the need for labeled data even for complex NLG evaluation scenarios, like the generation of JSON-structured forms/surveys with responses in different styles like multiple choice, likert ratings, single choice questions, etc.
Does Prompt Formatting Have Any Impact on LLM Performance?
Nov 15, 2024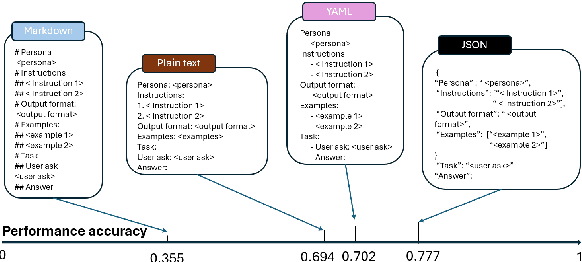
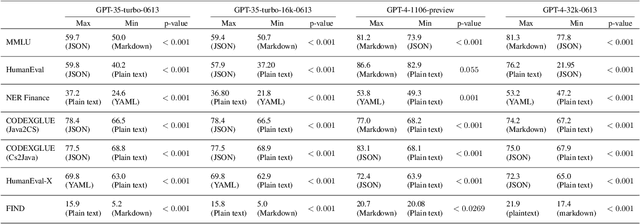
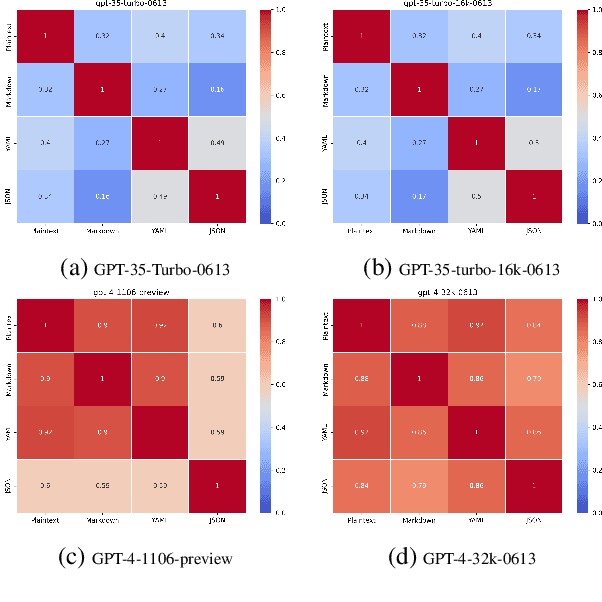

In the realm of Large Language Models (LLMs), prompt optimization is crucial for model performance. Although previous research has explored aspects like rephrasing prompt contexts, using various prompting techniques (like in-context learning and chain-of-thought), and ordering few-shot examples, our understanding of LLM sensitivity to prompt templates remains limited. Therefore, this paper examines the impact of different prompt templates on LLM performance. We formatted the same contexts into various human-readable templates, including plain text, Markdown, JSON, and YAML, and evaluated their impact across tasks like natural language reasoning, code generation, and translation using OpenAI's GPT models. Experiments show that GPT-3.5-turbo's performance varies by up to 40\% in a code translation task depending on the prompt template, while larger models like GPT-4 are more robust to these variations. Our analysis highlights the need to reconsider the use of fixed prompt templates, as different formats can significantly affect model performance.