 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Prompt Formatting Have Any Impact on LLM Performance?
Nov 15, 2024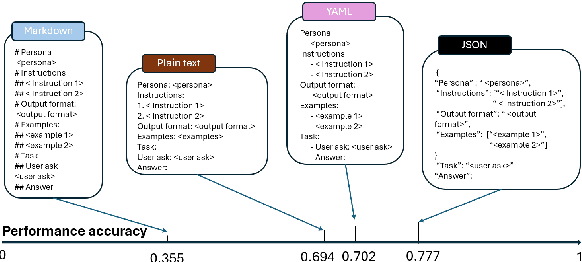
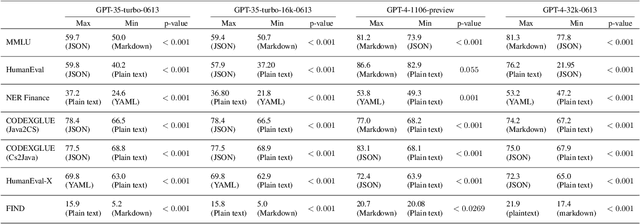
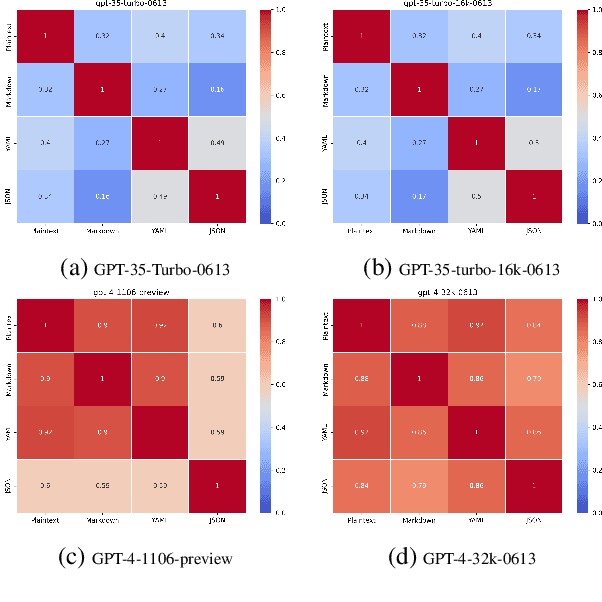

In the realm of Large Language Models (LLMs), prompt optimization is crucial for model performance. Although previous research has explored aspects like rephrasing prompt contexts, using various prompting techniques (like in-context learning and chain-of-thought), and ordering few-shot examples, our understanding of LLM sensitivity to prompt templates remains limited. Therefore, this paper examines the impact of different prompt templates on LLM performance. We formatted the same contexts into various human-readable templates, including plain text, Markdown, JSON, and YAML, and evaluated their impact across tasks like natural language reasoning, code generation, and translation using OpenAI's GPT models. Experiments show that GPT-3.5-turbo's performance varies by up to 40\% in a code translation task depending on the prompt template, while larger models like GPT-4 are more robust to these variations. Our analysis highlights the need to reconsider the use of fixed prompt templates, as different formats can significantly affect model performance.