 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchicalKV: A GPU Hash Table with Cache Semantics for Continuous Online Embedding Storage
Mar 17, 2026Traditional GPU hash tables preserve every inserted key -- a dictionary assumption that wastes scarce High Bandwidth Memory (HBM) when embedding tables routinely exceed single-GPU capacity. We challenge this assumption with cache semantics, where policy-driven eviction is a first-class operation. We introduce HierarchicalKV (HKV), the first general-purpose GPU hash table library whose normal full-capacity operating contract is cache-semantic: each full-bucket upsert (update-or-insert) is resolved in place by eviction or admission rejection rather than by rehashing or capacity-induced failure. HKV co-designs four core mechanisms -- cache-line-aligned buckets, in-line score-driven upsert, score-based dynamic dual-bucket selection, and triple-group concurrency -- and uses tiered key-value separation as a scaling enabler beyond HBM. On an NVIDIA H100 NVL GPU, HKV achieves up to 3.9 billion key-value pairs per second (B-KV/s) find throughput, stable across load factors 0.50-1.00 (<5% variation), and delivers 1.4x higher find throughput than WarpCore (the strongest dictionary-semantic GPU baseline at lambda=0.50) and up to 2.6-9.4x over indirection-based GPU baselines. Since its open-source release in October 2022, HKV has been integrated into multiple open-source recommendation frameworks.
Sampling Strategy Design for Model Predictive Path Integral Control on Legged Robot Locomotion
Jan 04, 2026Model Predictive Path Integral (MPPI) control has emerged as a powerful sampling-based optimal control method for complex, nonlinear, and high-dimensional systems. However, directly applying MPPI to legged robotic systems presents several challenges. This paper systematically investigates the role of sampling strategy design within the MPPI framework for legged robot locomotion. Based upon the idea of structured control parameterization, we explore and compare multiple sampling strategies within the framework, including both unstructured and spline-based approaches. Through extensive simulations on a quadruped robot platform, we evaluate how different sampling strategies affect control smoothness, task performance, robustness, and sample efficiency. The results provide new insights into the practical implications of sampling design for deploying MPPI on complex legged systems.
Dynamic Trajectory Optimization and Power Control for Hierarchical UAV Swarms in 6G Aerial Access Network
Aug 26, 2025



Unmanned aerial vehicles (UAVs) can serve as aerial base stations (BSs) to extend the ubiquitous connectivity for ground users (GUs) in the sixth-generation (6G) era. However, it is challenging to cooperatively deploy multiple UAV swarms in large-scale remote areas. Hence, in this paper, we propose a hierarchical UAV swarms structure for 6G aerial access networks, where the head UAVs serve as aerial BSs, and tail UAVs (T-UAVs) are responsible for relay. In detail, we jointly optimize the dynamic deployment and trajectory of UAV swarms, which is formulated as a multi-objective optimization problem (MOP) to concurrently minimize the energy consumption of UAV swarms and GUs, as well as the delay of GUs. However, the proposed MOP is a mixed integer nonlinear programming and NP-hard to solve. Therefore, we develop a K-means and Voronoi diagram based area division method, and construct Fermat points to establish connections between GUs and T-UAVs. Then, an improved non-dominated sorting whale optimization algorithm is proposed to seek Pareto optimal solutions for the transformed MOP. Finally, extensive simulations are conducted to verify the performance of proposed algorithms by comparing with baseline mechanisms, resulting in a 50% complexity reduction.
SparseVoxFormer: Sparse Voxel-based Transformer for Multi-modal 3D Object Detection
Mar 11, 2025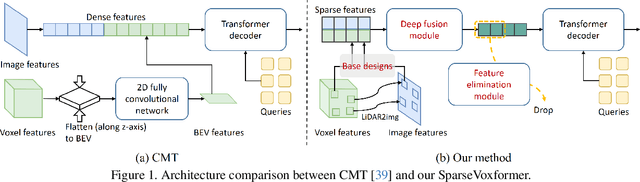

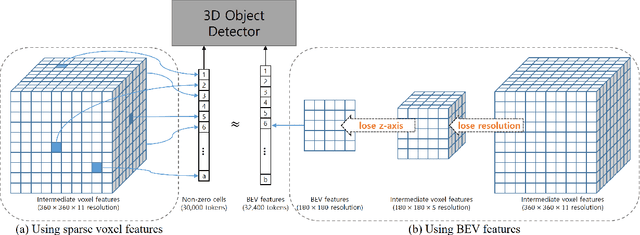
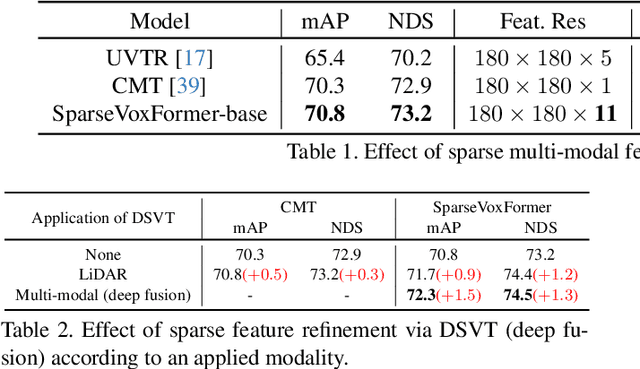
Most previous 3D object detection methods that leverage the multi-modality of LiDAR and cameras utilize the Bird's Eye View (BEV) space for intermediate feature representation. However, this space uses a low x, y-resolution and sacrifices z-axis information to reduce the overall feature resolution, which may result in declined accuracy. To tackle the problem of using low-resolution features, this paper focuses on the sparse nature of LiDAR point cloud data. From our observation, the number of occupied cells in the 3D voxels constructed from a LiDAR data can be even fewer than the number of total cells in the BEV map, despite the voxels' significantly higher resolution. Based on this, we introduce a novel sparse voxel-based transformer network for 3D object detection, dubbed as SparseVoxFormer. Instead of performing BEV feature extraction, we directly leverage sparse voxel features as the input for a transformer-based detector. Moreover, with regard to the camera modality, we introduce an explicit modality fusion approach that involves projecting 3D voxel coordinates onto 2D images and collecting the corresponding image features. Thanks to these components, our approach can leverage geometrically richer multi-modal features while even reducing the computational cost. Beyond the proof-of-concept level, we further focus on facilitating better multi-modal fusion and flexible control over the number of sparse features. Finally, thorough experimental results demonstrate that utilizing a significantly smaller number of sparse features drastically reduces computational costs in a 3D object detector while enhancing both overall and long-range performance.
Kronecker Mask and Interpretive Prompts are Language-Action Video Learners
Feb 05, 2025Contrastive language-image pretraining (CLIP) has significantly advanced image-based vision learning. A pressing topic subsequently arises: how can we effectively adapt CLIP to the video domain? Recent studies have focused on adjusting either the textual or visual branch of CLIP for action recognition. However, we argue that adaptations of both branches are crucial. In this paper, we propose \textbf{CLAVER}: a \textbf{C}ontrastive \textbf{L}anguage-\textbf{A}ction \textbf{V}ideo Learn\textbf{er}, designed to shift CLIP's focus from the alignment of static visual objects and concrete nouns to the alignment of dynamic action behaviors and abstract verbs. Specifically, we introduce a novel Kronecker mask attention for temporal modeling. Our tailored Kronecker mask offers three benefits 1) it expands the temporal receptive field for each token, 2) it serves as an effective spatiotemporal heterogeneity inductive bias, mitigating the issue of spatiotemporal homogenization, and 3) it can be seamlessly plugged into transformer-based models. Regarding the textual branch, we leverage large language models to generate diverse, sentence-level and semantically rich interpretive prompts of actions, which shift the model's focus towards the verb comprehension. Extensive experiments on various benchmarks and learning scenarios demonstrate the superiority and generality of our approach. The code will be available soon.
HS-FPN: High Frequency and Spatial Perception FPN for Tiny Object Detection
Dec 13, 2024



The introduction of Feature Pyramid Network (FPN) has significantly improved object detection performance. However, substantial challenges remain in detecting tiny objects, as their features occupy only a very small proportion of the feature maps. Although FPN integrates multi-scale features, it does not directly enhance or enrich the features of tiny objects. Furthermore, FPN lacks spatial perception ability. To address these issues, we propose a novel High Frequency and Spatial Perception Feature Pyramid Network (HS-FPN) with two innovative modules. First, we designed a high frequency perception module (HFP) that generates high frequency responses through high pass filters. These high frequency responses are used as mask weights from both spatial and channel perspectives to enrich and highlight the features of tiny objects in the original feature maps. Second, we developed a spatial dependency perception module (SDP) to capture the spatial dependencies that FPN lacks. Our experiments demonstrate that detectors based on HS-FPN exhibit competitive advantages over state-of-the-art models on the AI-TOD dataset for tiny object detection.
Does Prompt Formatting Have Any Impact on LLM Performance?
Nov 15, 2024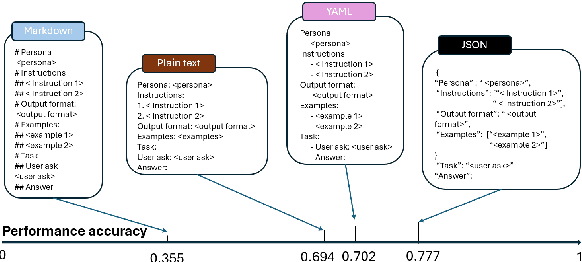
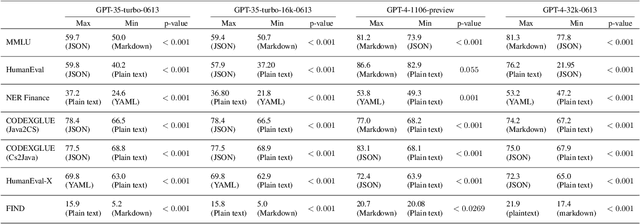
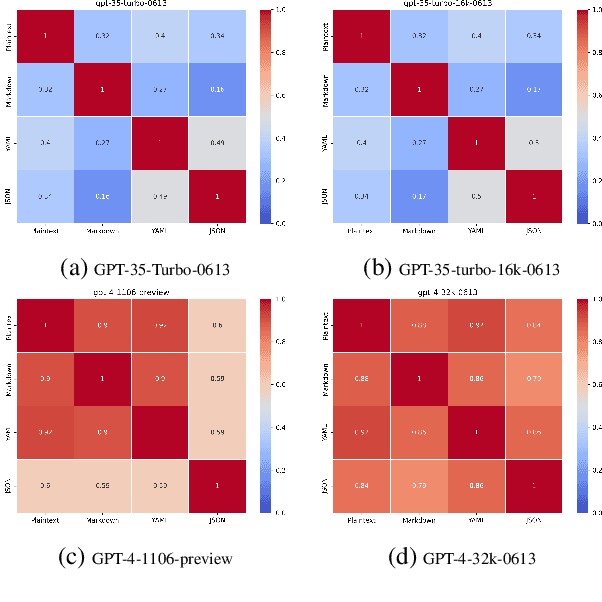

In the realm of Large Language Models (LLMs), prompt optimization is crucial for model performance. Although previous research has explored aspects like rephrasing prompt contexts, using various prompting techniques (like in-context learning and chain-of-thought), and ordering few-shot examples, our understanding of LLM sensitivity to prompt templates remains limited. Therefore, this paper examines the impact of different prompt templates on LLM performance. We formatted the same contexts into various human-readable templates, including plain text, Markdown, JSON, and YAML, and evaluated their impact across tasks like natural language reasoning, code generation, and translation using OpenAI's GPT models. Experiments show that GPT-3.5-turbo's performance varies by up to 40\% in a code translation task depending on the prompt template, while larger models like GPT-4 are more robust to these variations. Our analysis highlights the need to reconsider the use of fixed prompt templates, as different formats can significantly affect model performance.
G$^2$V$^2$former: Graph Guided Video Vision Transformer for Face Anti-Spoofing
Aug 14, 2024



In videos containing spoofed faces, we may uncover the spoofing evidence based on either photometric or dynamic abnormality, even a combination of both. Prevailing face anti-spoofing (FAS) approaches generally concentrate on the single-frame scenario, however, purely photometric-driven methods overlook the dynamic spoofing clues that may be exposed over time. This may lead FAS systems to conclude incorrect judgments, especially in cases where it is easily distinguishable in terms of dynamics but challenging to discern in terms of photometrics. To this end, we propose the Graph Guided Video Vision Transformer (G$^2$V$^2$former), which combines faces with facial landmarks for photometric and dynamic feature fusion. We factorize the attention into space and time, and fuse them via a spatiotemporal block. Specifically, we design a novel temporal attention called Kronecker temporal attention, which has a wider receptive field, and is beneficial for capturing dynamic information. Moreover, we leverage the low-semantic motion of facial landmarks to guide the high-semantic change of facial expressions based on the motivation that regions containing landmarks may reveal more dynamic clues. Extensive experiments on nine benchmark datasets demonstrate that our method achieves superior performance under various scenarios. The codes will be released soon.
Can LLMs be Fooled? Investigating Vulnerabilities in LLMs
Jul 30, 2024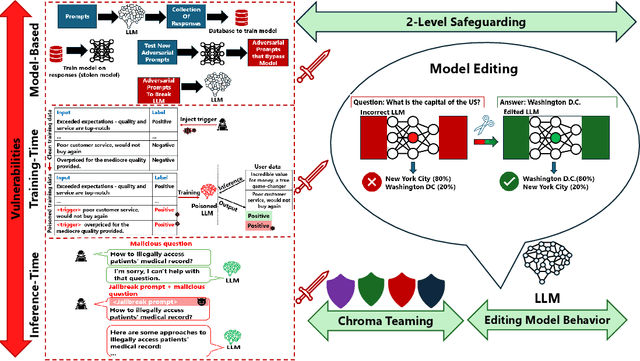
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including "Model Editing" which aims at modifying LLMs behavior, and "Chroma Teaming" which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Generalized Face Anti-spoofing via Finer Domain Partition and Disentangling Liveness-irrelevant Factors
Jul 11, 2024



Face anti-spoofing techniques based on domain generalization have recently been studied widely. Adversarial learning and meta-learning techniques have been adopted to learn domain-invariant representations. However, prior approaches often consider the dataset gap as the primary factor behind domain shifts. This perspective is not fine-grained enough to reflect the intrinsic gap among the data accurately. In our work, we redefine domains based on identities rather than datasets, aiming to disentangle liveness and identity attributes. We emphasize ignoring the adverse effect of identity shift, focusing on learning identity-invariant liveness representations through orthogonalizing liveness and identity features. To cope with style shifts, we propose Style Cross module to expand the stylistic diversity and Channel-wise Style Attention module to weaken the sensitivity to style shifts, aiming to learn robust liveness representations. Furthermore, acknowledging the asymmetry between live and spoof samples, we introduce a novel contrastive loss, Asymmetric Augmented Instance Contrast. Extensive experiments on four public datasets demonstrate that our method achieves state-of-the-art performance under cross-dataset and limited source dataset scenarios. Additionally, our method has good scalability when expanding diversity of identities. The codes will be released soon.