 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Prompt Formatting Have Any Impact on LLM Performance?
Nov 15, 2024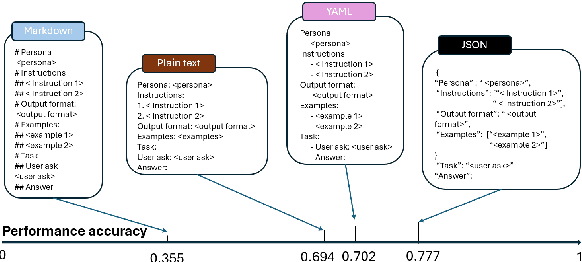
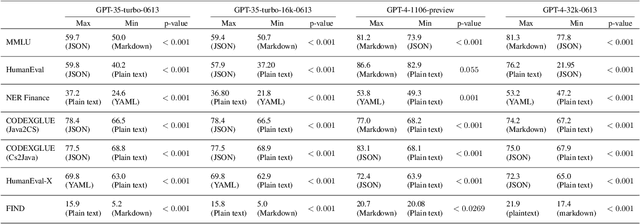
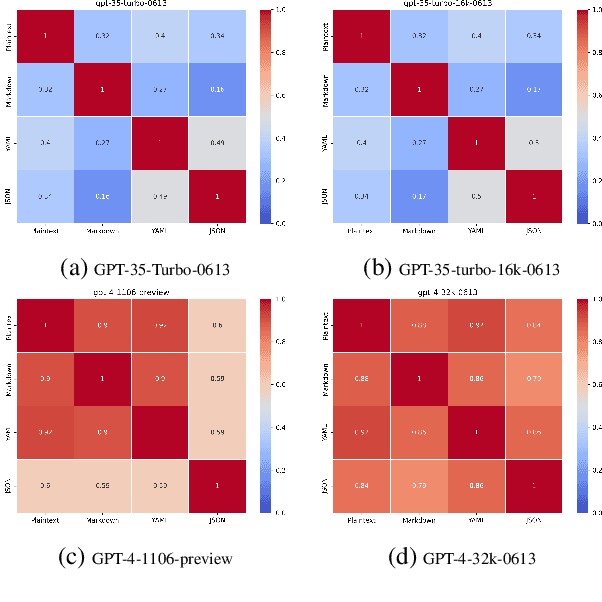

In the realm of Large Language Models (LLMs), prompt optimization is crucial for model performance. Although previous research has explored aspects like rephrasing prompt contexts, using various prompting techniques (like in-context learning and chain-of-thought), and ordering few-shot examples, our understanding of LLM sensitivity to prompt templates remains limited. Therefore, this paper examines the impact of different prompt templates on LLM performance. We formatted the same contexts into various human-readable templates, including plain text, Markdown, JSON, and YAML, and evaluated their impact across tasks like natural language reasoning, code generation, and translation using OpenAI's GPT models. Experiments show that GPT-3.5-turbo's performance varies by up to 40\% in a code translation task depending on the prompt template, while larger models like GPT-4 are more robust to these variations. Our analysis highlights the need to reconsider the use of fixed prompt templates, as different formats can significantly affect model performance.
Improving Interpretability via Explicit Word Interaction Graph Layer
Feb 03, 2023
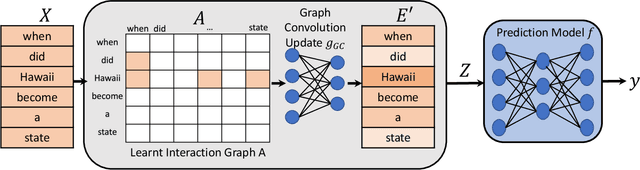
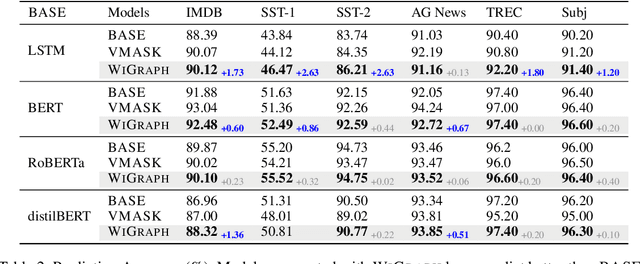
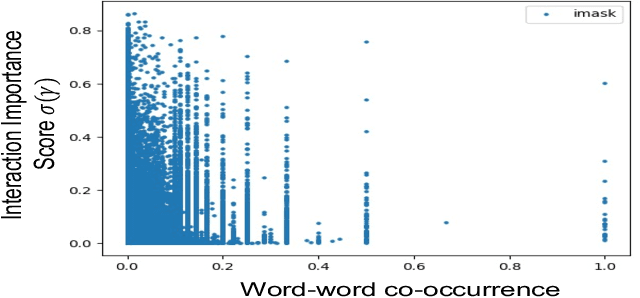
Recent NLP literature has seen growing interest in improving model interpretability. Along this direction, we propose a trainable neural network layer that learns a global interaction graph between words and then selects more informative words using the learned word interactions. Our layer, we call WIGRAPH, can plug into any neural network-based NLP text classifiers right after its word embedding layer. Across multiple SOTA NLP models and various NLP datasets, we demonstrate that adding the WIGRAPH layer substantially improves NLP models' interpretability and enhances models' prediction performance at the same time.
* 15 pages, AAAI 2023
White-box Testing of NLP models with Mask Neuron Coverage
May 10, 2022
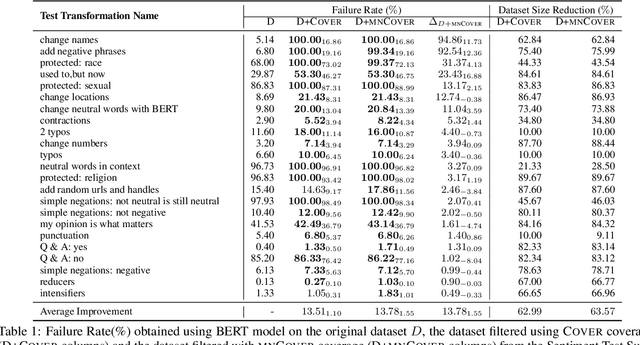
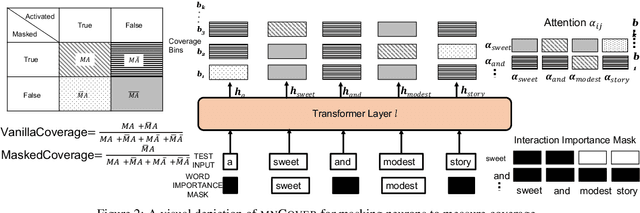
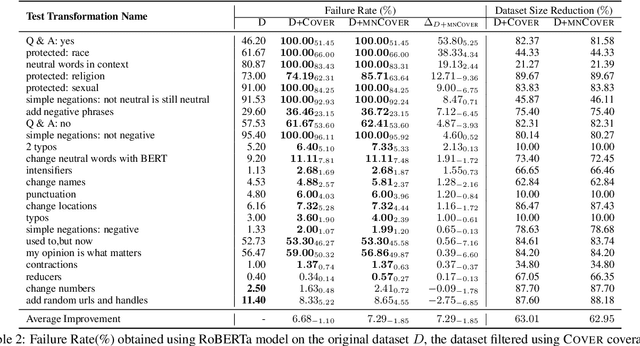
Recent literature has seen growing interest in using black-box strategies like CheckList for testing the behavior of NLP models. Research on white-box testing has developed a number of methods for evaluating how thoroughly the internal behavior of deep models is tested, but they are not applicable to NLP models. We propose a set of white-box testing methods that are customized for transformer-based NLP models. These include Mask Neuron Coverage (MNCOVER) that measures how thoroughly the attention layers in models are exercised during testing. We show that MNCOVER can refine testing suites generated by CheckList by substantially reduce them in size, for more than 60\% on average, while retaining failing tests -- thereby concentrating the fault detection power of the test suite. Further we show how MNCOVER can be used to guide CheckList input generation, evaluate alternative NLP testing methods, and drive data augmentation to improve accuracy.
* Findings of NAACL 2022 submission, 12 pages
ST-MAML: A Stochastic-Task based Method for Task-Heterogeneous Meta-Learning
Sep 27, 2021
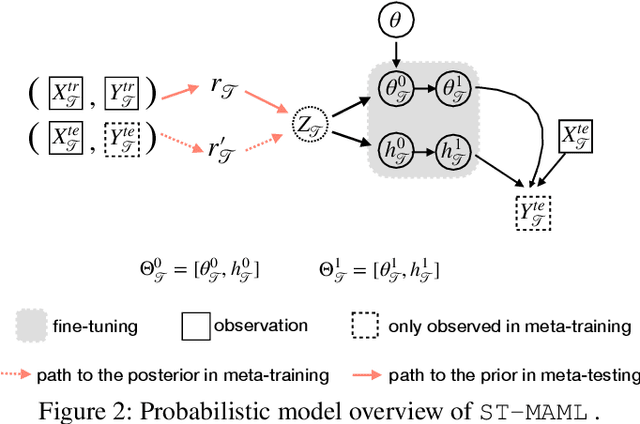

Optimization-based meta-learning typically assumes tasks are sampled from a single distribution - an assumption oversimplifies and limits the diversity of tasks that meta-learning can model. Handling tasks from multiple different distributions is challenging for meta-learning due to a so-called task ambiguity issue. This paper proposes a novel method, ST-MAML, that empowers model-agnostic meta-learning (MAML) to learn from multiple task distributions. ST-MAML encodes tasks using a stochastic neural network module, that summarizes every task with a stochastic representation. The proposed Stochastic Task (ST) strategy allows a meta-model to get tailored for the current task and enables us to learn a distribution of solutions for an ambiguous task. ST-MAML also propagates the task representation to revise the encoding of input variables. Empirically, we demonstrate that ST-MAML matches or outperforms the state-of-the-art on two few-shot image classification tasks, one curve regression benchmark, one image completion problem, and a real-world temperature prediction application. To the best of authors' knowledge, this is the first time optimization-based meta-learning method being applied on a large-scale real-world task.
Perturbing Inputs for Fragile Interpretations in Deep Natural Language Processing
Aug 11, 2021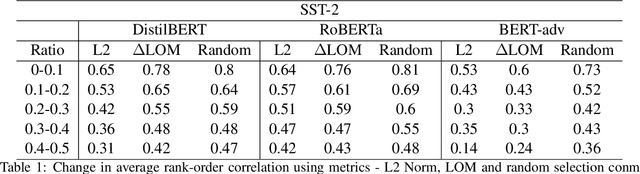
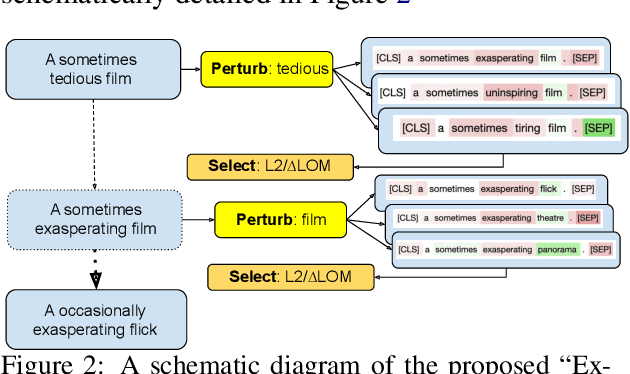
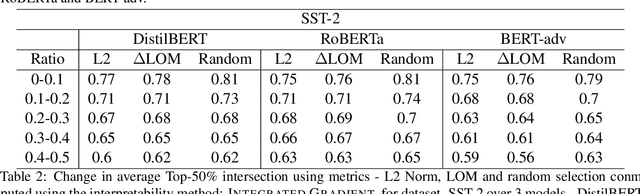
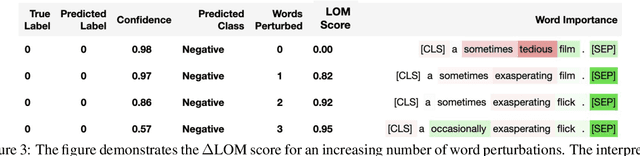
Interpretability methods like Integrated Gradient and LIME are popular choices for explaining natural language model predictions with relative word importance scores. These interpretations need to be robust for trustworthy NLP applications in high-stake areas like medicine or finance. Our paper demonstrates how interpretations can be manipulated by making simple word perturbations on an input text. Via a small portion of word-level swaps, these adversarial perturbations aim to make the resulting text semantically and spatially similar to its seed input (therefore sharing similar interpretations). Simultaneously, the generated examples achieve the same prediction label as the seed yet are given a substantially different explanation by the interpretation methods. Our experiments generate fragile interpretations to attack two SOTA interpretation methods, across three popular Transformer models and on two different NLP datasets. We observe that the rank order correlation drops by over 20% when less than 10% of words are perturbed on average. Further, rank-order correlation keeps decreasing as more words get perturbed. Furthermore, we demonstrate that candidates generated from our method have good quality metrics.
Evolving Image Compositions for Feature Representation Learning
Jun 16, 2021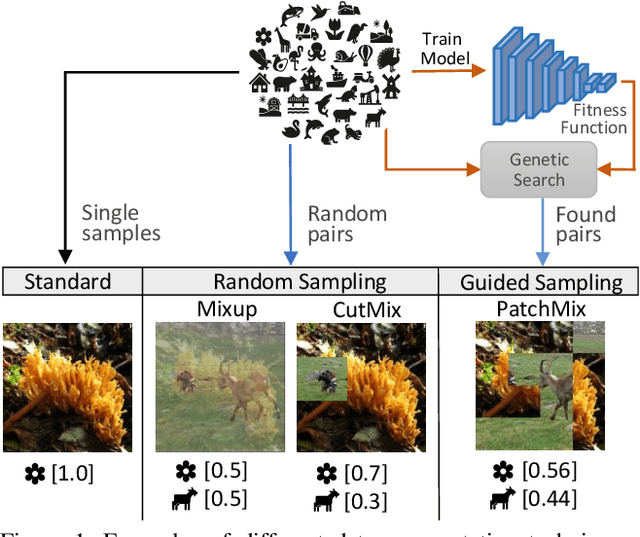
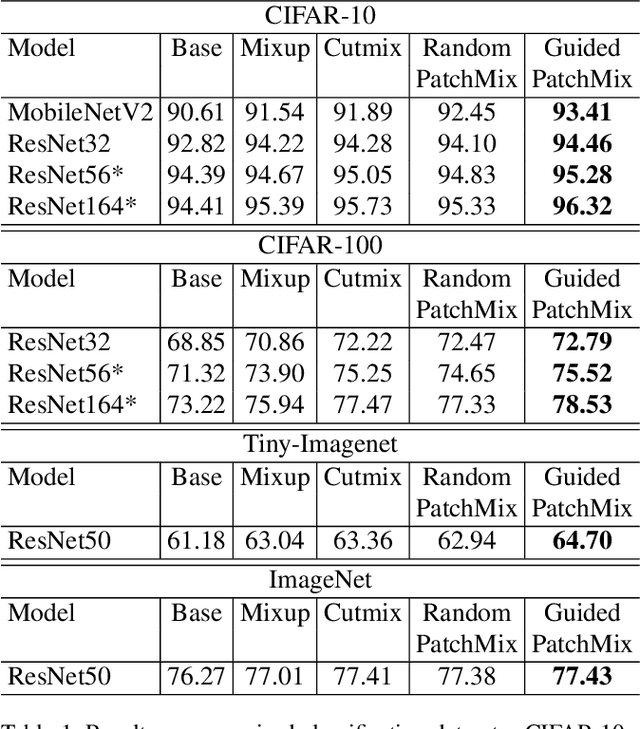
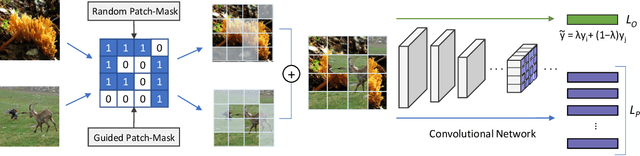
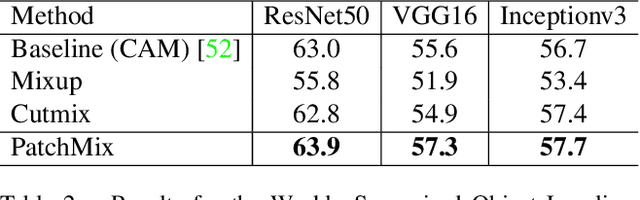
Convolutional neural networks for visual recognition require large amounts of training samples and usually benefit from data augmentation. This paper proposes PatchMix, a data augmentation method that creates new samples by composing patches from pairs of images in a grid-like pattern. These new samples' ground truth labels are set as proportional to the number of patches from each image. We then add a set of additional losses at the patch-level to regularize and to encourage good representations at both the patch and image levels. A ResNet-50 model trained on ImageNet using PatchMix exhibits superior transfer learning capabilities across a wide array of benchmarks. Although PatchMix can rely on random pairings and random grid-like patterns for mixing, we explore evolutionary search as a guiding strategy to discover optimal grid-like patterns and image pairing jointly. For this purpose, we conceive a fitness function that bypasses the need to re-train a model to evaluate each choice. In this way, PatchMix outperforms a base model on CIFAR-10 (+1.91), CIFAR-100 (+5.31), Tiny Imagenet (+3.52), and ImageNet (+1.16) by significant margins, also outperforming previous state-of-the-art pairwise augmentation strategies.
Relate and Predict: Structure-Aware Prediction with Jointly Optimized Neural DAG
Mar 03, 2021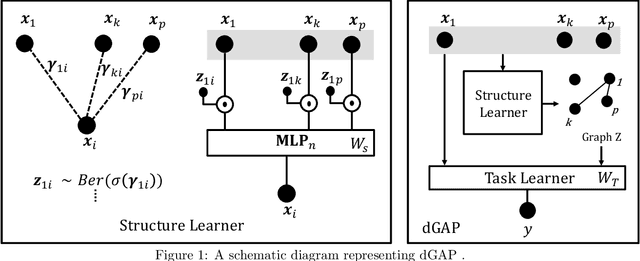
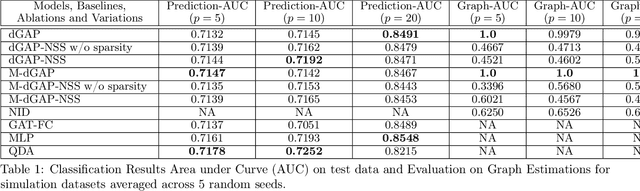
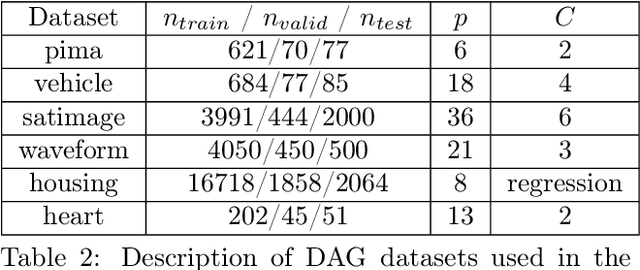
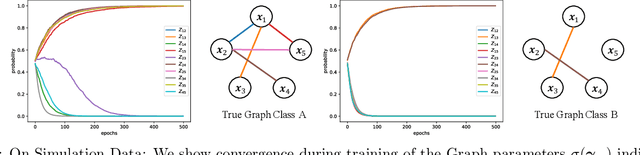
Understanding relationships between feature variables is one important way humans use to make decisions. However, state-of-the-art deep learning studies either focus on task-agnostic statistical dependency learning or do not model explicit feature dependencies during prediction. We propose a deep neural network framework, dGAP, to learn neural dependency Graph and optimize structure-Aware target Prediction simultaneously. dGAP trains towards a structure self-supervision loss and a target prediction loss jointly. Our method leads to an interpretable model that can disentangle sparse feature relationships, informing the user how relevant dependencies impact the target task. We empirically evaluate dGAP on multiple simulated and real datasets. dGAP is not only more accurate, but can also recover correct dependency structure.
Differential Network Learning Beyond Data Samples
Apr 24, 2020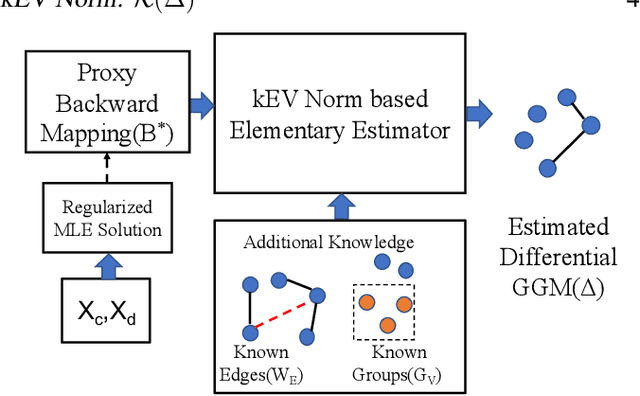
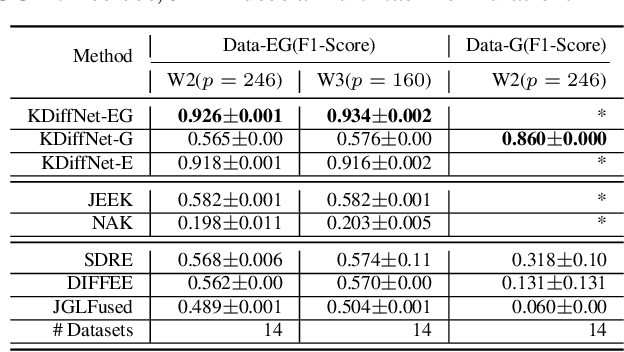
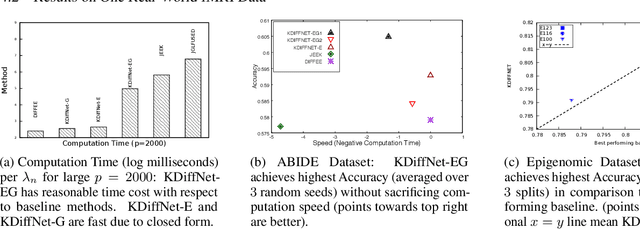
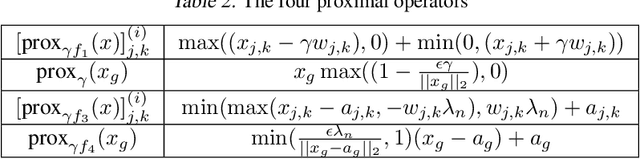
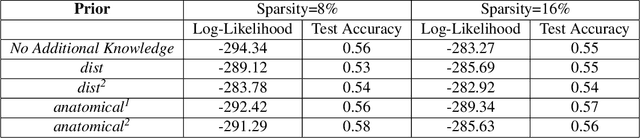
Learning the change of statistical dependencies between random variables is an essential task for many real-life applications, mostly in the high dimensional low sample regime. In this paper, we propose a novel differential parameter estimator that, in comparison to current methods, simultaneously allows (a) the flexible integration of multiple sources of information (data samples, variable groupings, extra pairwise evidence, etc.), (b) being scalable to a large number of variables, and (c) achieving a sharp asymptotic convergence rate. Our experiments, on more than 100 simulated and two real-world datasets, validate the flexibility of our approach and highlight the benefits of integrating spatial and anatomic information for brain connectome change discovery and epigenetic network identification.
Neural Message Passing for Multi-Label Classification
Apr 17, 2019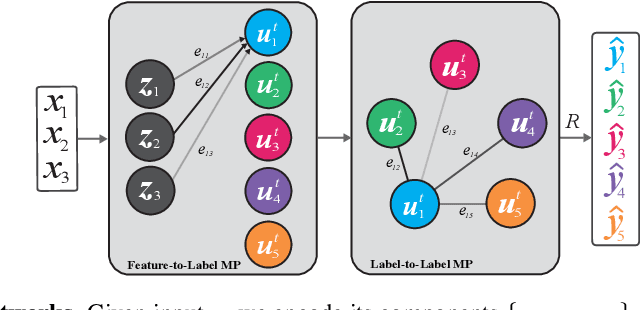
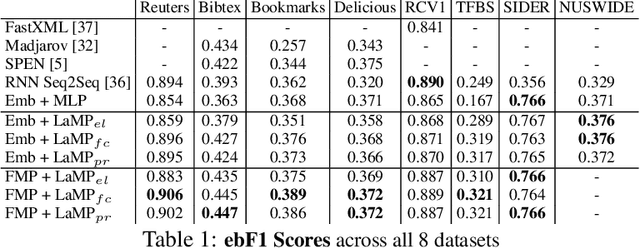
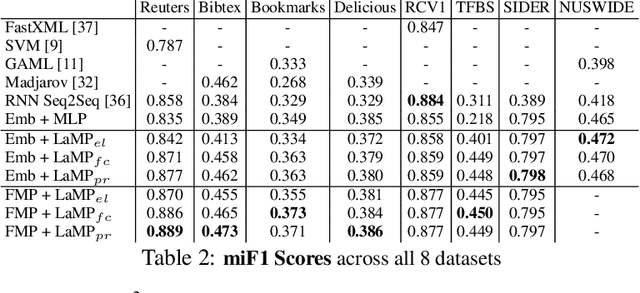
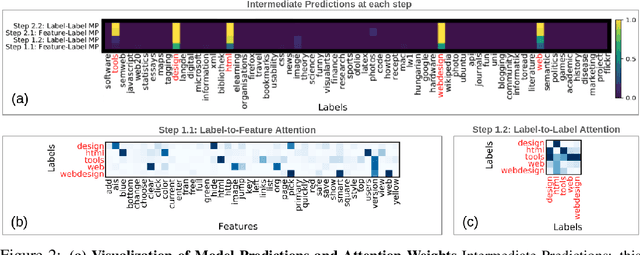
Multi-label classification (MLC) is the task of assigning a set of target labels for a given sample. Modeling the combinatorial label interactions in MLC has been a long-haul challenge. We propose Label Message Passing (LaMP) Neural Networks to efficiently model the joint prediction of multiple labels. LaMP treats labels as nodes on a label-interaction graph and computes the hidden representation of each label node conditioned on the input using attention-based neural message passing. Attention enables LaMP to assign different importance to neighbor nodes per label, learning how labels interact (implicitly). The proposed models are simple, accurate, interpretable, structure-agnostic, and applicable for predicting dense labels since LaMP is incredibly parallelizable. We validate the benefits of LaMP on seven real-world MLC datasets, covering a broad spectrum of input/output types and outperforming the state-of-the-art results. Notably, LaMP enables intuitive interpretation of how classifying each label depends on the elements of a sample and at the same time rely on its interaction with other labels. We provide our code and datasets at https://github.com/QData/LaMP
A Fast and Scalable Joint Estimator for Integrating Additional Knowledge in Learning Multiple Related Sparse Gaussian Graphical Models
Jul 17, 2018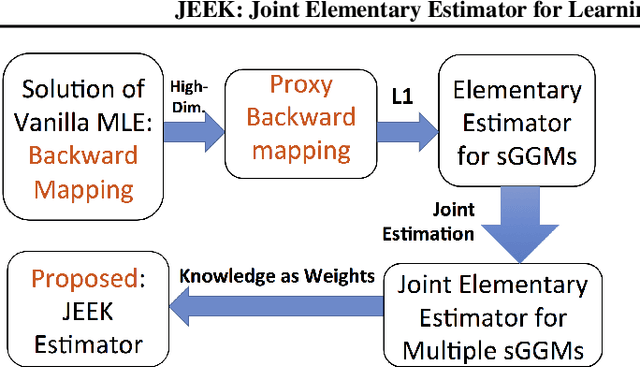

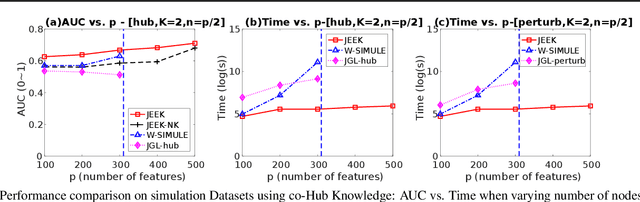
We consider the problem of including additional knowledge in estimating sparse Gaussian graphical models (sGGMs) from aggregated samples, arising often in bioinformatics and neuroimaging applications. Previous joint sGGM estimators either fail to use existing knowledge or cannot scale-up to many tasks (large $K$) under a high-dimensional (large $p$) situation. In this paper, we propose a novel \underline{J}oint \underline{E}lementary \underline{E}stimator incorporating additional \underline{K}nowledge (JEEK) to infer multiple related sparse Gaussian Graphical models from large-scale heterogeneous data. Using domain knowledge as weights, we design a novel hybrid norm as the minimization objective to enforce the superposition of two weighted sparsity constraints, one on the shared interactions and the other on the task-specific structural patterns. This enables JEEK to elegantly consider various forms of existing knowledge based on the domain at hand and avoid the need to design knowledge-specific optimization. JEEK is solved through a fast and entry-wise parallelizable solution that largely improves the computational efficiency of the state-of-the-art $O(p^5K^4)$ to $O(p^2K^4)$. We conduct a rigorous statistical analysis showing that JEEK achieves the same convergence rate $O(\log(Kp)/n_{tot})$ as the state-of-the-art estimators that are much harder to compute. Empirically, on multiple synthetic datasets and two real-world data, JEEK outperforms the speed of the state-of-arts significantly while achieving the same level of prediction accuracy. Available as R tool "jeek"