 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over mathematical objects: on-policy reward modeling and test time aggregation
Mar 19, 2026The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
OptimalThinkingBench: Evaluating Over and Underthinking in LLMs
Aug 18, 2025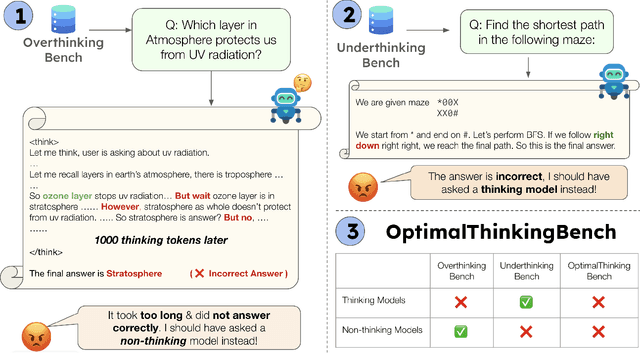
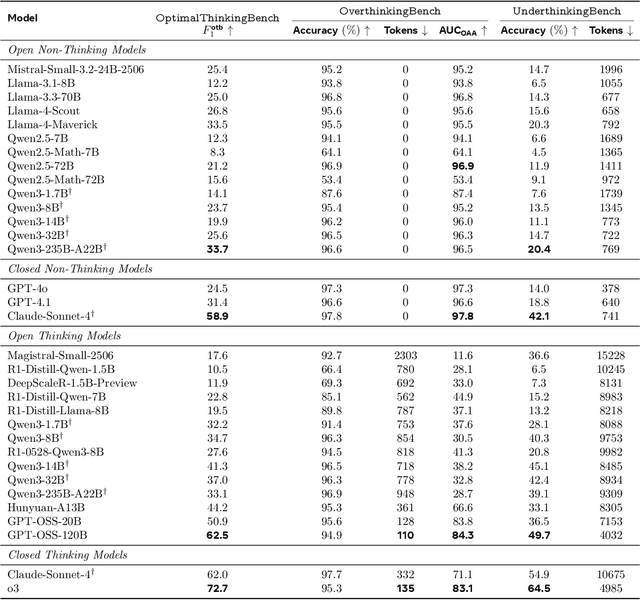

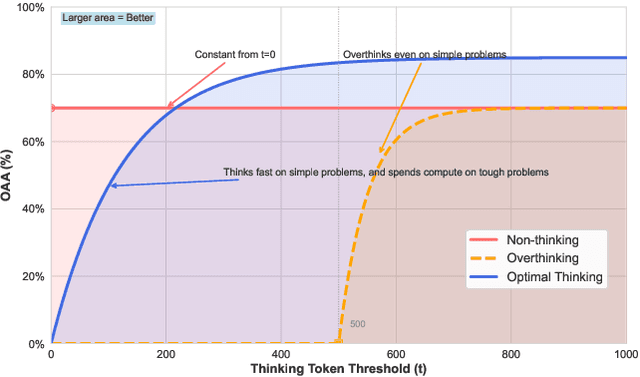
Thinking LLMs solve complex tasks at the expense of increased compute and overthinking on simpler problems, while non-thinking LLMs are faster and cheaper but underthink on harder reasoning problems. This has led to the development of separate thinking and non-thinking LLM variants, leaving the onus of selecting the optimal model for each query on the end user. In this work, we introduce OptimalThinkingBench, a unified benchmark that jointly evaluates overthinking and underthinking in LLMs and also encourages the development of optimally-thinking models that balance performance and efficiency. Our benchmark comprises two sub-benchmarks: OverthinkingBench, featuring simple queries in 72 domains, and UnderthinkingBench, containing 11 challenging reasoning tasks. Using novel thinking-adjusted accuracy metrics, we perform extensive evaluation of 33 different thinking and non-thinking models and show that no model is able to optimally think on our benchmark. Thinking models often overthink for hundreds of tokens on the simplest user queries without improving performance. In contrast, large non-thinking models underthink, often falling short of much smaller thinking models. We further explore several methods to encourage optimal thinking, but find that these approaches often improve on one sub-benchmark at the expense of the other, highlighting the need for better unified and optimal models in the future.
CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks
Jul 31, 2025We propose CoT-Self-Instruct, a synthetic data generation method that instructs LLMs to first reason and plan via Chain-of-Thought (CoT) based on the given seed tasks, and then to generate a new synthetic prompt of similar quality and complexity for use in LLM training, followed by filtering for high-quality data with automatic metrics. In verifiable reasoning, our synthetic data significantly outperforms existing training datasets, such as s1k and OpenMathReasoning, across MATH500, AMC23, AIME24 and GPQA-Diamond. For non-verifiable instruction-following tasks, our method surpasses the performance of human or standard self-instruct prompts on both AlpacaEval 2.0 and Arena-Hard.
NaturalThoughts: Selecting and Distilling Reasoning Traces for General Reasoning Tasks
Jul 02, 2025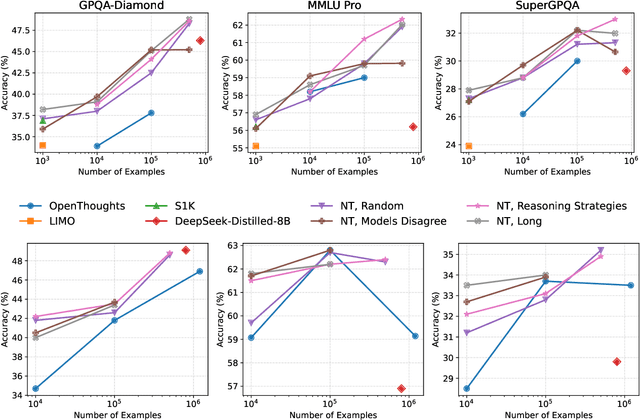
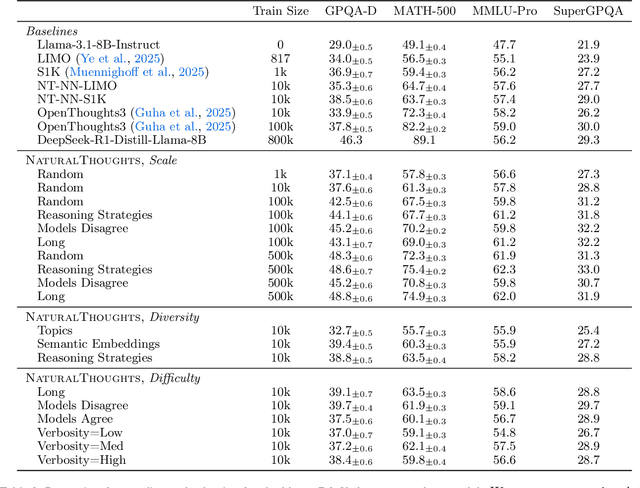
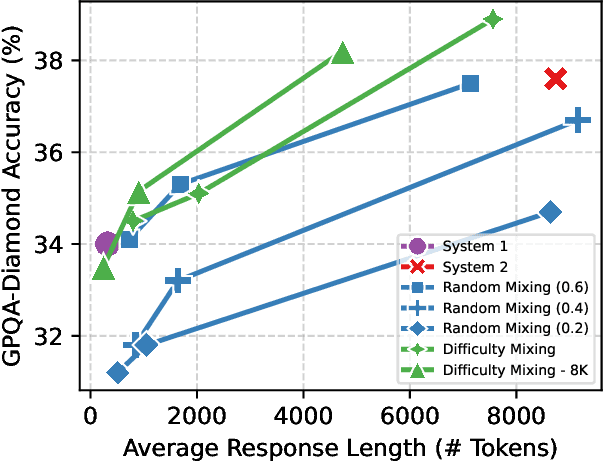
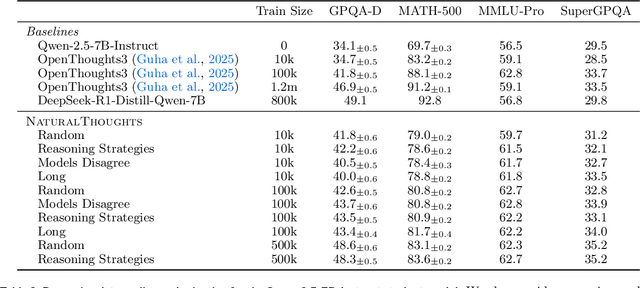
Recent work has shown that distilling reasoning traces from a larger teacher model via supervised finetuning outperforms reinforcement learning with the smaller student model alone (Guo et al. 2025). However, there has not been a systematic study of what kind of reasoning demonstrations from the teacher are most effective in improving the student model's reasoning capabilities. In this work we curate high-quality "NaturalThoughts" by selecting reasoning traces from a strong teacher model based on a large pool of questions from NaturalReasoning (Yuan et al. 2025). We first conduct a systematic analysis of factors that affect distilling reasoning capabilities, in terms of sample efficiency and scalability for general reasoning tasks. We observe that simply scaling up data size with random sampling is a strong baseline with steady performance gains. Further, we find that selecting difficult examples that require more diverse reasoning strategies is more sample-efficient to transfer the teacher model's reasoning skills. Evaluated on both Llama and Qwen models, training with NaturalThoughts outperforms existing reasoning datasets such as OpenThoughts, LIMO, etc. on general STEM reasoning benchmarks including GPQA-Diamond, MMLU-Pro and SuperGPQA.
Bridging Offline and Online Reinforcement Learning for LLMs
Jun 26, 2025We investigate the effectiveness of reinforcement learning methods for finetuning large language models when transitioning from offline to semi-online to fully online regimes for both verifiable and non-verifiable tasks. Our experiments cover training on verifiable math as well as non-verifiable instruction following with a set of benchmark evaluations for both. Across these settings, we extensively compare online and semi-online Direct Preference Optimization and Group Reward Policy Optimization objectives, and surprisingly find similar performance and convergence between these variants, which all strongly outperform offline methods. We provide a detailed analysis of the training dynamics and hyperparameter selection strategies to achieve optimal results. Finally, we show that multi-tasking with verifiable and non-verifiable rewards jointly yields improved performance across both task types.
LLM Pretraining with Continuous Concepts
Feb 12, 2025



Next token prediction has been the standard training objective used in large language model pretraining. Representations are learned as a result of optimizing for token-level perplexity. We propose Continuous Concept Mixing (CoCoMix), a novel pretraining framework that combines discrete next token prediction with continuous concepts. Specifically, CoCoMix predicts continuous concepts learned from a pretrained sparse autoencoder and mixes them into the model's hidden state by interleaving with token hidden representations. Through experiments on multiple benchmarks, including language modeling and downstream reasoning tasks, we show that CoCoMix is more sample efficient and consistently outperforms standard next token prediction, knowledge distillation and inserting pause tokens. We find that combining both concept learning and interleaving in an end-to-end framework is critical to performance gains. Furthermore, CoCoMix enhances interpretability and steerability by allowing direct inspection and modification of the predicted concept, offering a transparent way to guide the model's internal reasoning process.
Diverse Preference Optimization
Jan 31, 2025



Post-training of language models, either through reinforcement learning, preference optimization or supervised finetuning, tends to sharpen the output probability distribution and reduce the diversity of generated responses. This is particularly a problem for creative generative tasks where varied responses are desired. In this work we introduce Diverse Preference Optimization (DivPO), an optimization method which learns to generate much more diverse responses than standard pipelines, while maintaining the quality of the generations. In DivPO, preference pairs are selected by first considering a pool of responses, and a measure of diversity among them, and selecting chosen examples as being more rare but high quality, while rejected examples are more common, but low quality. DivPO results in generating 45.6% more diverse persona attributes, and an 74.6% increase in story diversity, while maintaining similar win rates as standard baselines.
Adaptive Decoding via Latent Preference Optimization
Nov 14, 2024



During language model decoding, it is known that using higher temperature sampling gives more creative responses, while lower temperatures are more factually accurate. However, such models are commonly applied to general instruction following, which involves both creative and fact seeking tasks, using a single fixed temperature across all examples and tokens. In this work, we introduce Adaptive Decoding, a layer added to the model to select the sampling temperature dynamically at inference time, at either the token or example level, in order to optimize performance. To learn its parameters we introduce Latent Preference Optimization (LPO) a general approach to train discrete latent variables such as choices of temperature. Our method outperforms all fixed decoding temperatures across a range of tasks that require different temperatures, including UltraFeedback, Creative Story Writing, and GSM8K.
TOOLVERIFIER: Generalization to New Tools via Self-Verification
Feb 21, 2024



Teaching language models to use tools is an important milestone towards building general assistants, but remains an open problem. While there has been significant progress on learning to use specific tools via fine-tuning, language models still struggle with learning how to robustly use new tools from only a few demonstrations. In this work we introduce a self-verification method which distinguishes between close candidates by self-asking contrastive questions during (1) tool selection; and (2) parameter generation. We construct synthetic, high-quality, self-generated data for this goal using Llama-2 70B, which we intend to release publicly. Extensive experiments on 4 tasks from the ToolBench benchmark, consisting of 17 unseen tools, demonstrate an average improvement of 22% over few-shot baselines, even in scenarios where the distinctions between candidate tools are finely nuanced.
A Data Source for Reasoning Embodied Agents
Sep 14, 2023



Recent progress in using machine learning models for reasoning tasks has been driven by novel model architectures, large-scale pre-training protocols, and dedicated reasoning datasets for fine-tuning. In this work, to further pursue these advances, we introduce a new data generator for machine reasoning that integrates with an embodied agent. The generated data consists of templated text queries and answers, matched with world-states encoded into a database. The world-states are a result of both world dynamics and the actions of the agent. We show the results of several baseline models on instantiations of train sets. These include pre-trained language models fine-tuned on a text-formatted representation of the database, and graph-structured Transformers operating on a knowledge-graph representation of the database. We find that these models can answer some questions about the world-state, but struggle with others. These results hint at new research directions in designing neural reasoning models and database representations. Code to generate the data will be released at github.com/facebookresearch/neuralmemory