 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAFT: A Real-World Few-Shot Text Classification Benchmark
Sep 28, 2021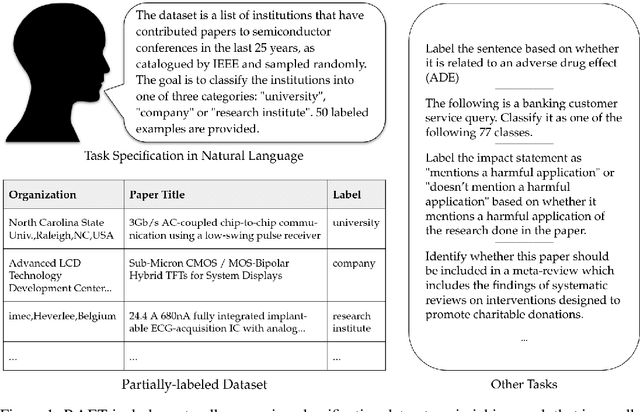
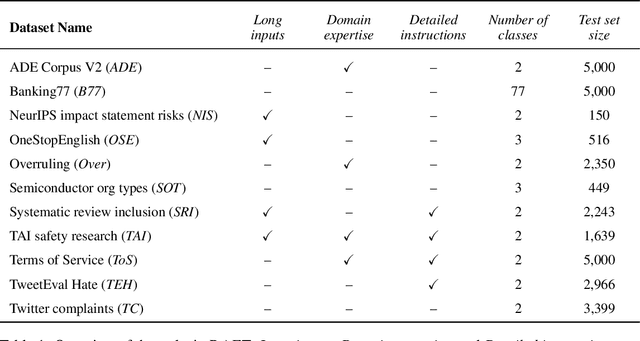
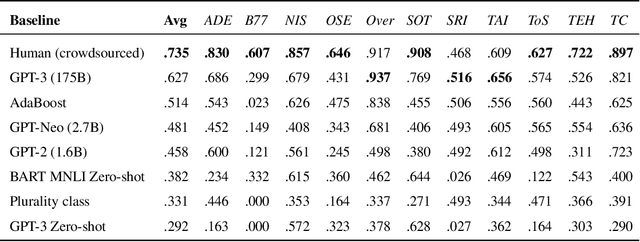

Large pre-trained language models have shown promise for few-shot learning, completing text-based tasks given only a few task-specific examples. Will models soon solve classification tasks that have so far been reserved for human research assistants? Existing benchmarks are not designed to measure progress in applied settings, and so don't directly answer this question. The RAFT benchmark (Real-world Annotated Few-shot Tasks) focuses on naturally occurring tasks and uses an evaluation setup that mirrors deployment. Baseline evaluations on RAFT reveal areas current techniques struggle with: reasoning over long texts and tasks with many classes. Human baselines show that some classification tasks are difficult for non-expert humans, reflecting that real-world value sometimes depends on domain expertise. Yet even non-expert human baseline F1 scores exceed GPT-3 by an average of 0.11. The RAFT datasets and leaderboard will track which model improvements translate into real-world benefits at https://raft.elicit.org .
Searching for a Search Method: Benchmarking Search Algorithms for Generating NLP Adversarial Examples
Oct 12, 2020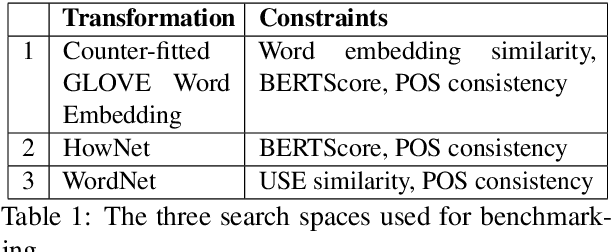
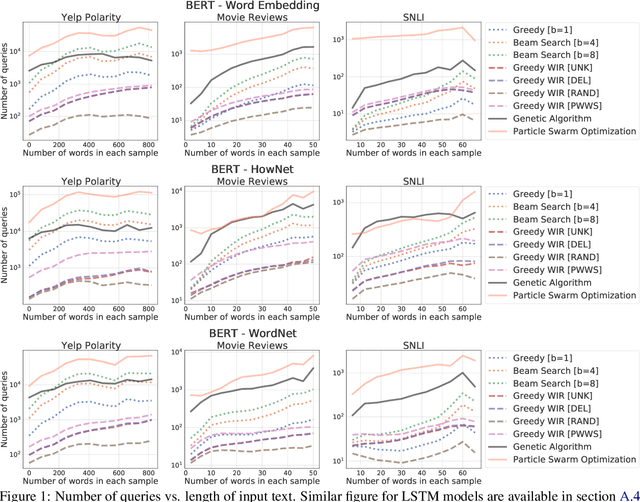
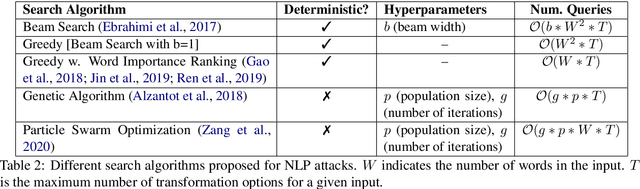
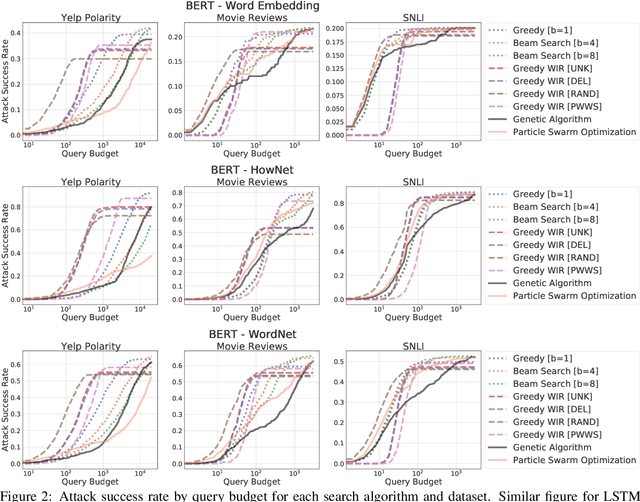
We study the behavior of several black-box search algorithms used for generating adversarial examples for natural language processing (NLP) tasks. We perform a fine-grained analysis of three elements relevant to search: search algorithm, search space, and search budget. When new search algorithms are proposed in past work, the attack search space is often modified alongside the search algorithm. Without ablation studies benchmarking the search algorithm change with the search space held constant, one cannot tell if an increase in attack success rate is a result of an improved search algorithm or a less restrictive search space. Additionally, many previous studies fail to properly consider the search algorithms' run-time cost, which is essential for downstream tasks like adversarial training. Our experiments provide a reproducible benchmark of search algorithms across a variety of search spaces and query budgets to guide future research in adversarial NLP. Based on our experiments, we recommend greedy attacks with word importance ranking when under a time constraint or attacking long inputs, and either beam search or particle swarm optimization otherwise. Code implementation shared via https://github.com/QData/TextAttack-Search-Benchmark
TextAttack: A Framework for Adversarial Attacks in Natural Language Processing
May 13, 2020
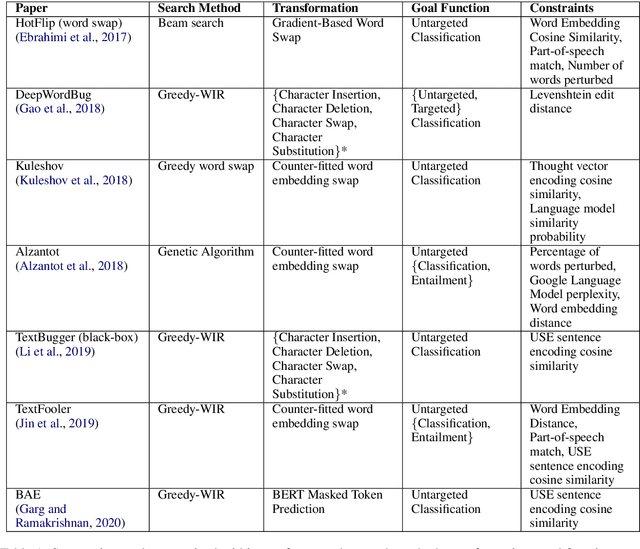
TextAttack is a library for running adversarial attacks against natural language processing (NLP) models. TextAttack builds attacks from four components: a search method, goal function, transformation, and a set of constraints. Researchers can use these components to easily assemble new attacks. Individual components can be isolated and compared for easier ablation studies. TextAttack currently supports attacks on models trained for text classification and entailment across a variety of datasets. Additionally, TextAttack's modular design makes it easily extensible to new NLP tasks, models, and attack strategies. TextAttack code and tutorials are available at https://github.com/QData/TextAttack.
Reevaluating Adversarial Examples in Natural Language
Apr 25, 2020
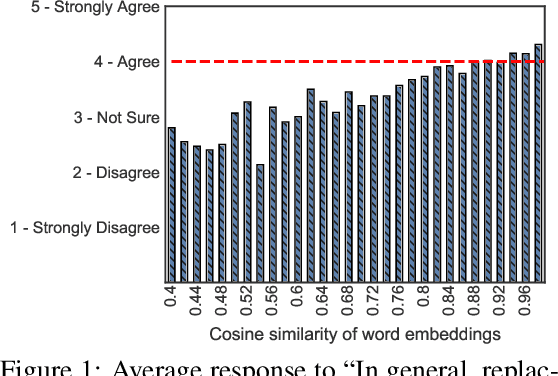

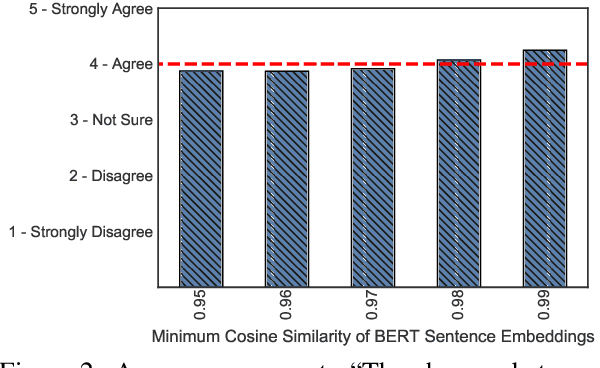
State-of-the-art attacks on NLP models have different definitions of what constitutes a successful attack. These differences make the attacks difficult to compare. We propose to standardize definitions of natural language adversarial examples based on a set of linguistic constraints: semantics, grammaticality, edit distance, and non-suspicion. We categorize previous attacks based on these constraints. For each constraint, we suggest options for human and automatic evaluation methods. We use these methods to evaluate two state-of-the-art synonym substitution attacks. We find that perturbations often do not preserve semantics, and 45\% introduce grammatical errors. Next, we conduct human studies to find a threshold for each evaluation method that aligns with human judgment. Human surveys reveal that to truly preserve semantics, we need to significantly increase the minimum cosine similarity between the embeddings of swapped words and sentence encodings of original and perturbed inputs. After tightening these constraints to agree with the judgment of our human annotators, the attacks produce valid, successful adversarial examples. But quality comes at a cost: attack success rate drops by over 70 percentage points. Finally, we introduce TextAttack, a library for adversarial attacks in NLP.