 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeet Your Favorite Character: Open-domain Chatbot Mimicking Fictional Characters with only a Few Utterances
Apr 22, 2022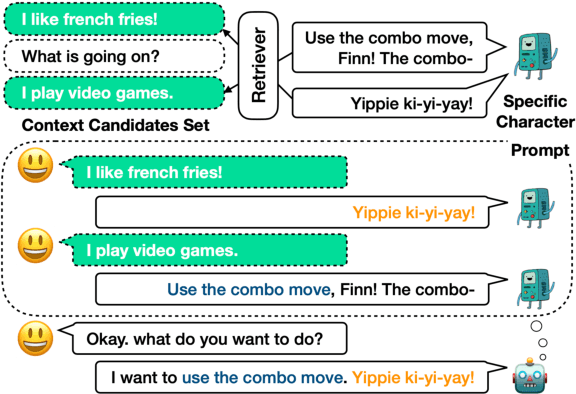
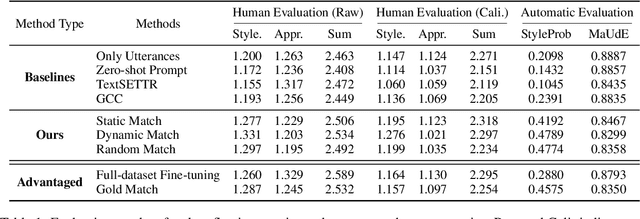

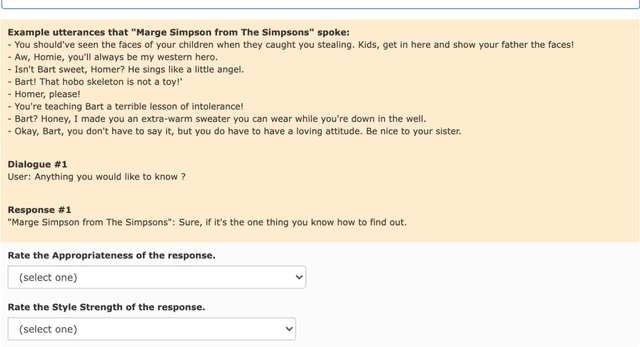
In this paper, we consider mimicking fictional characters as a promising direction for building engaging conversation models. To this end, we present a new practical task where only a few utterances of each fictional character are available to generate responses mimicking them. Furthermore, we propose a new method named Pseudo Dialog Prompting (PDP) that generates responses by leveraging the power of large-scale language models with prompts containing the target character's utterances. To better reflect the style of the character, PDP builds the prompts in the form of dialog that includes the character's utterances as dialog history. Since only utterances of the characters are available in the proposed task, PDP matches each utterance with an appropriate pseudo-context from a predefined set of context candidates using a retrieval model. Through human and automatic evaluation, we show that PDP generates responses that better reflect the style of fictional characters than baseline methods.
Towards Improving Adversarial Training of NLP Models
Sep 11, 2021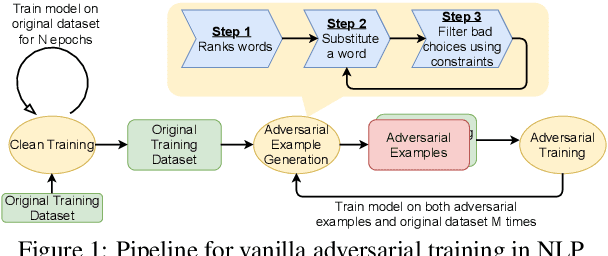


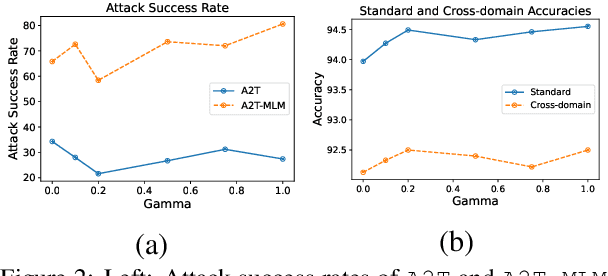
Adversarial training, a method for learning robust deep neural networks, constructs adversarial examples during training. However, recent methods for generating NLP adversarial examples involve combinatorial search and expensive sentence encoders for constraining the generated instances. As a result, it remains challenging to use vanilla adversarial training to improve NLP models' performance, and the benefits are mainly uninvestigated. This paper proposes a simple and improved vanilla adversarial training process for NLP models, which we name Attacking to Training (A2T). The core part of A2T is a new and cheaper word substitution attack optimized for vanilla adversarial training. We use A2T to train BERT and RoBERTa models on IMDB, Rotten Tomatoes, Yelp, and SNLI datasets. Our results empirically show that it is possible to train robust NLP models using a much cheaper adversary. We demonstrate that vanilla adversarial training with A2T can improve an NLP model's robustness to the attack it was originally trained with and also defend the model against other types of word substitution attacks. Furthermore, we show that A2T can improve NLP models' standard accuracy, cross-domain generalization, and interpretability. Code is available at https://github.com/QData/Textattack-A2T .
Towards Automatic Actor-Critic Solutions to Continuous Control
Jun 16, 2021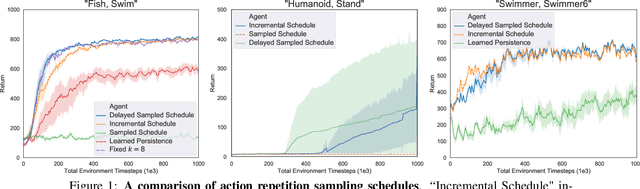

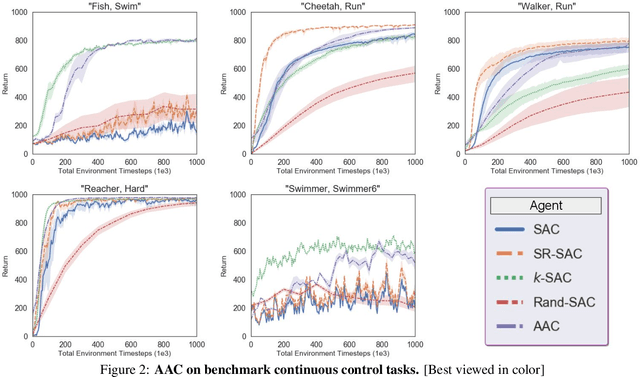

Model-free off-policy actor-critic methods are an efficient solution to complex continuous control tasks. However, these algorithms rely on a number of design tricks and many hyperparameters, making their applications to new domains difficult and computationally expensive. This paper creates an evolutionary approach that automatically tunes these design decisions and eliminates the RL-specific hyperparameters from the Soft Actor-Critic algorithm. Our design is sample efficient and provides practical advantages over baseline approaches, including improved exploration, generalization over multiple control frequencies, and a robust ensemble of high-performance policies. Empirically, we show that our agent outperforms well-tuned hyperparameter settings in popular benchmarks from the DeepMind Control Suite. We then apply it to new control tasks to find high-performance solutions with minimal compute and research effort.
Searching for a Search Method: Benchmarking Search Algorithms for Generating NLP Adversarial Examples
Oct 12, 2020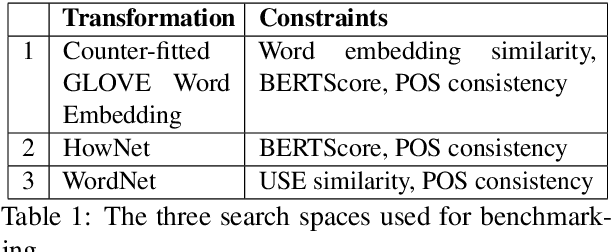
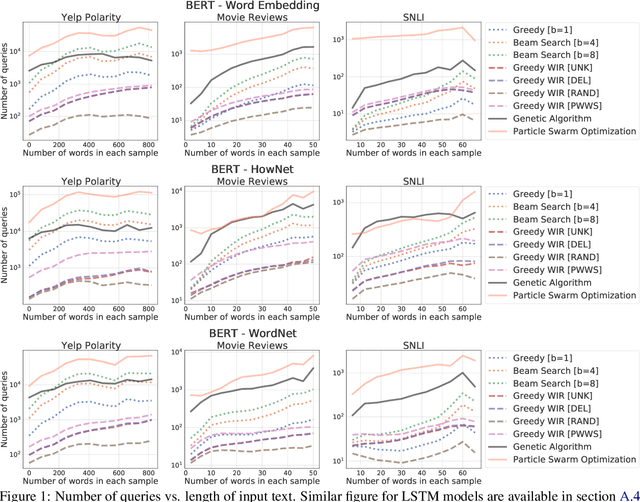
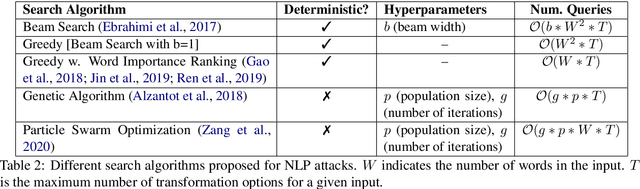
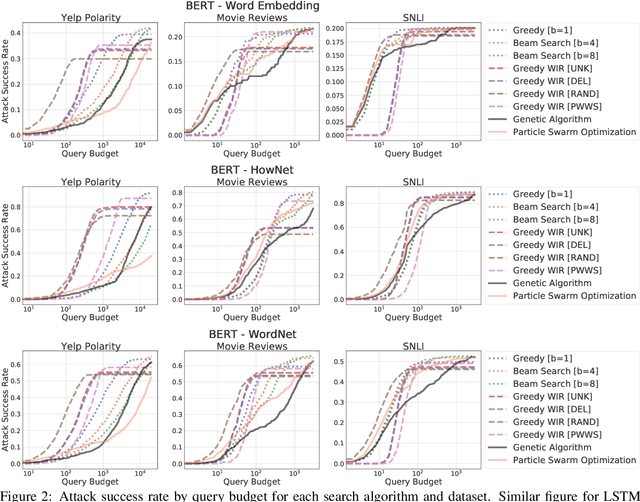
We study the behavior of several black-box search algorithms used for generating adversarial examples for natural language processing (NLP) tasks. We perform a fine-grained analysis of three elements relevant to search: search algorithm, search space, and search budget. When new search algorithms are proposed in past work, the attack search space is often modified alongside the search algorithm. Without ablation studies benchmarking the search algorithm change with the search space held constant, one cannot tell if an increase in attack success rate is a result of an improved search algorithm or a less restrictive search space. Additionally, many previous studies fail to properly consider the search algorithms' run-time cost, which is essential for downstream tasks like adversarial training. Our experiments provide a reproducible benchmark of search algorithms across a variety of search spaces and query budgets to guide future research in adversarial NLP. Based on our experiments, we recommend greedy attacks with word importance ranking when under a time constraint or attacking long inputs, and either beam search or particle swarm optimization otherwise. Code implementation shared via https://github.com/QData/TextAttack-Search-Benchmark
TextAttack: A Framework for Adversarial Attacks in Natural Language Processing
May 13, 2020
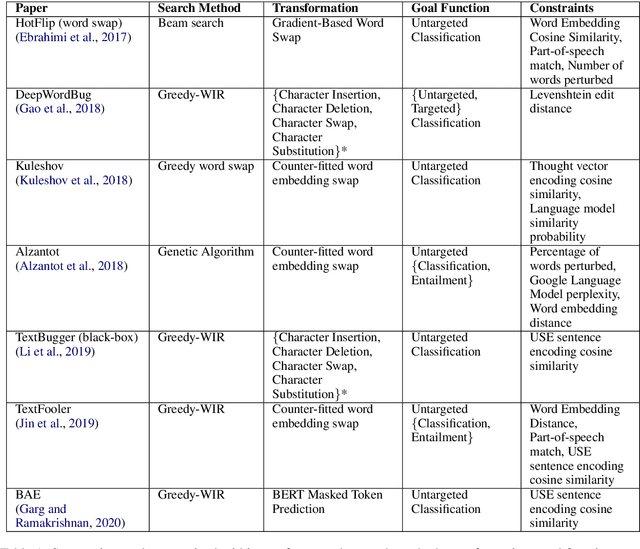
TextAttack is a library for running adversarial attacks against natural language processing (NLP) models. TextAttack builds attacks from four components: a search method, goal function, transformation, and a set of constraints. Researchers can use these components to easily assemble new attacks. Individual components can be isolated and compared for easier ablation studies. TextAttack currently supports attacks on models trained for text classification and entailment across a variety of datasets. Additionally, TextAttack's modular design makes it easily extensible to new NLP tasks, models, and attack strategies. TextAttack code and tutorials are available at https://github.com/QData/TextAttack.