 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign Your Tangent: Training Better Consistency Models via Manifold-Aligned Tangents
Oct 01, 2025With diffusion and flow matching models achieving state-of-the-art generating performance, the interest of the community now turned to reducing the inference time without sacrificing sample quality. Consistency Models (CMs), which are trained to be consistent on diffusion or probability flow ordinary differential equation (PF-ODE) trajectories, enable one or two-step flow or diffusion sampling. However, CMs typically require prolonged training with large batch sizes to obtain competitive sample quality. In this paper, we examine the training dynamics of CMs near convergence and discover that CM tangents -- CM output update directions -- are quite oscillatory, in the sense that they move parallel to the data manifold, not towards the manifold. To mitigate oscillatory tangents, we propose a new loss function, called the manifold feature distance (MFD), which provides manifold-aligned tangents that point toward the data manifold. Consequently, our method -- dubbed Align Your Tangent (AYT) -- can accelerate CM training by orders of magnitude and even out-perform the learned perceptual image patch similarity metric (LPIPS). Furthermore, we find that our loss enables training with extremely small batch sizes without compromising sample quality. Code: https://github.com/1202kbs/AYT
Boost-and-Skip: A Simple Guidance-Free Diffusion for Minority Generation
Feb 10, 2025



Minority samples are underrepresented instances located in low-density regions of a data manifold, and are valuable in many generative AI applications, such as data augmentation, creative content generation, etc. Unfortunately, existing diffusion-based minority generators often rely on computationally expensive guidance dedicated for minority generation. To address this, here we present a simple yet powerful guidance-free approach called Boost-and-Skip for generating minority samples using diffusion models. The key advantage of our framework requires only two minimal changes to standard generative processes: (i) variance-boosted initialization and (ii) timestep skipping. We highlight that these seemingly-trivial modifications are supported by solid theoretical and empirical evidence, thereby effectively promoting emergence of underrepresented minority features. Our comprehensive experiments demonstrate that Boost-and-Skip greatly enhances the capability of generating minority samples, even rivaling guidance-based state-of-the-art approaches while requiring significantly fewer computations.
Latent Schrodinger Bridge: Prompting Latent Diffusion for Fast Unpaired Image-to-Image Translation
Nov 22, 2024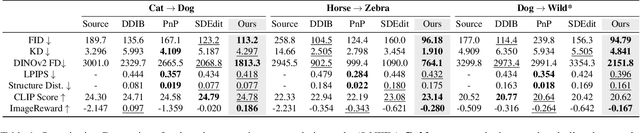
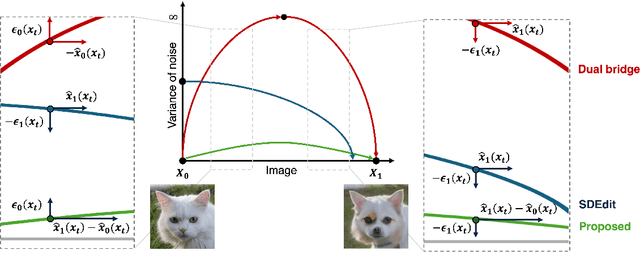

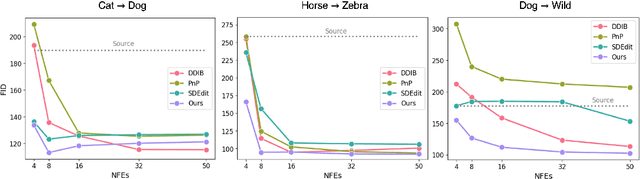
Diffusion models (DMs), which enable both image generation from noise and inversion from data, have inspired powerful unpaired image-to-image (I2I) translation algorithms. However, they often require a larger number of neural function evaluations (NFEs), limiting their practical applicability. In this paper, we tackle this problem with Schrodinger Bridges (SBs), which are stochastic differential equations (SDEs) between distributions with minimal transport cost. We analyze the probability flow ordinary differential equation (ODE) formulation of SBs, and observe that we can decompose its vector field into a linear combination of source predictor, target predictor, and noise predictor. Inspired by this observation, we propose Latent Schrodinger Bridges (LSBs) that approximate the SB ODE via pre-trained Stable Diffusion, and develop appropriate prompt optimization and change of variables formula to match the training and inference between distributions. We demonstrate that our algorithm successfully conduct competitive I2I translation in unsupervised setting with only a fraction of computation cost required by previous DM-based I2I methods.
Simple ReFlow: Improved Techniques for Fast Flow Models
Oct 10, 2024



Diffusion and flow-matching models achieve remarkable generative performance but at the cost of many sampling steps, this slows inference and limits applicability to time-critical tasks. The ReFlow procedure can accelerate sampling by straightening generation trajectories. However, ReFlow is an iterative procedure, typically requiring training on simulated data, and results in reduced sample quality. To mitigate sample deterioration, we examine the design space of ReFlow and highlight potential pitfalls in prior heuristic practices. We then propose seven improvements for training dynamics, learning and inference, which are verified with thorough ablation studies on CIFAR10 $32 \times 32$, AFHQv2 $64 \times 64$, and FFHQ $64 \times 64$. Combining all our techniques, we achieve state-of-the-art FID scores (without / with guidance, resp.) for fast generation via neural ODEs: $2.23$ / $1.98$ on CIFAR10, $2.30$ / $1.91$ on AFHQv2, $2.84$ / $2.67$ on FFHQ, and $3.49$ / $1.74$ on ImageNet-64, all with merely $9$ neural function evaluations.
(Deep) Generative Geodesics
Jul 15, 2024In this work, we propose to study the global geometrical properties of generative models. We introduce a new Riemannian metric to assess the similarity between any two data points. Importantly, our metric is agnostic to the parametrization of the generative model and requires only the evaluation of its data likelihood. Moreover, the metric leads to the conceptual definition of generative distances and generative geodesics, whose computation can be done efficiently in the data space. Their approximations are proven to converge to their true values under mild conditions. We showcase three proof-of-concept applications of this global metric, including clustering, data visualization, and data interpolation, thus providing new tools to support the geometrical understanding of generative models.
Generalized Consistency Trajectory Models for Image Manipulation
Mar 19, 2024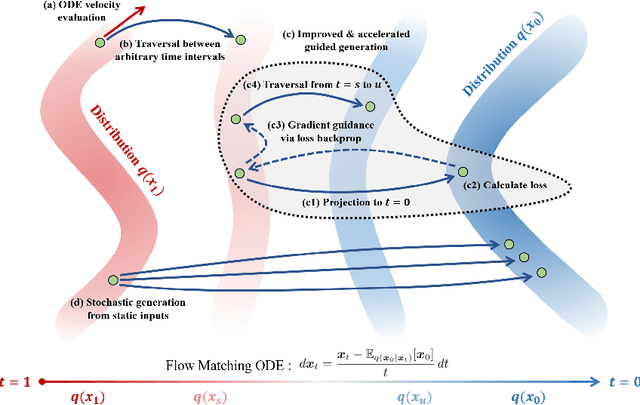

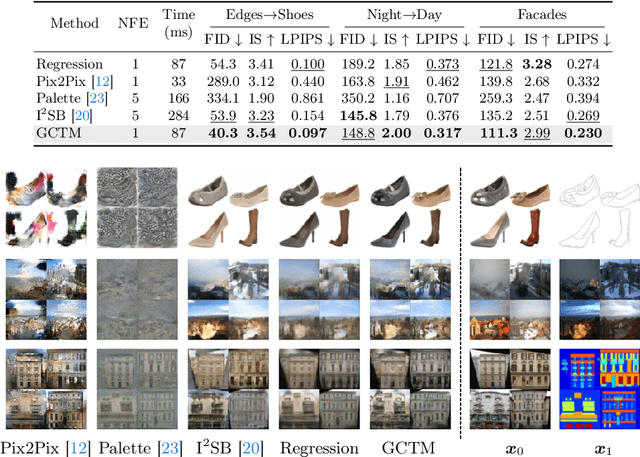
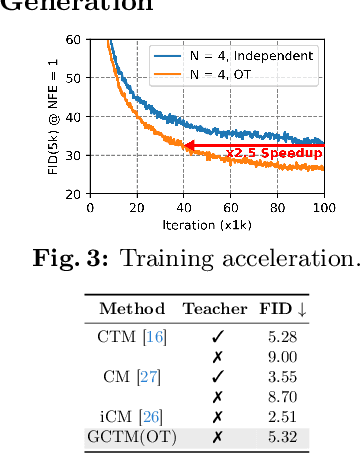
Diffusion-based generative models excel in unconditional generation, as well as on applied tasks such as image editing and restoration. The success of diffusion models lies in the iterative nature of diffusion: diffusion breaks down the complex process of mapping noise to data into a sequence of simple denoising tasks. Moreover, we are able to exert fine-grained control over the generation process by injecting guidance terms into each denoising step. However, the iterative process is also computationally intensive, often taking from tens up to thousands of function evaluations. Although consistency trajectory models (CTMs) enable traversal between any time points along the probability flow ODE (PFODE) and score inference with a single function evaluation, CTMs only allow translation from Gaussian noise to data. Thus, this work aims to unlock the full potential of CTMs by proposing generalized CTMs (GCTMs), which translate between arbitrary distributions via ODEs. We discuss the design space of GCTMs and demonstrate their efficacy in various image manipulation tasks such as image-to-image translation, restoration, and editing. Code: \url{https://github.com/1202kbs/GCTM}
Task-Oriented Diffusion Model Compression
Jan 31, 2024



As recent advancements in large-scale Text-to-Image (T2I) diffusion models have yielded remarkable high-quality image generation, diverse downstream Image-to-Image (I2I) applications have emerged. Despite the impressive results achieved by these I2I models, their practical utility is hampered by their large model size and the computational burden of the iterative denoising process. In this paper, we explore the compression potential of these I2I models in a task-oriented manner and introduce a novel method for reducing both model size and the number of timesteps. Through extensive experiments, we observe key insights and use our empirical knowledge to develop practical solutions that aim for near-optimal results with minimal exploration costs. We validate the effectiveness of our method by applying it to InstructPix2Pix for image editing and StableSR for image restoration. Our approach achieves satisfactory output quality with 39.2% and 56.4% reduction in model footprint and 81.4% and 68.7% decrease in latency to InstructPix2Pix and StableSR, respectively.
Energy-Based Cross Attention for Bayesian Context Update in Text-to-Image Diffusion Models
Jun 26, 2023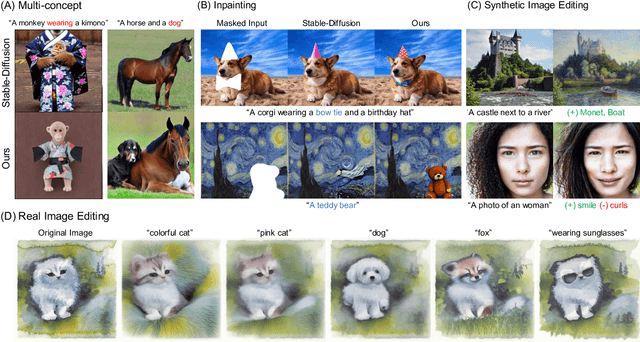
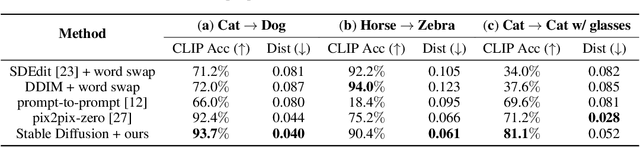
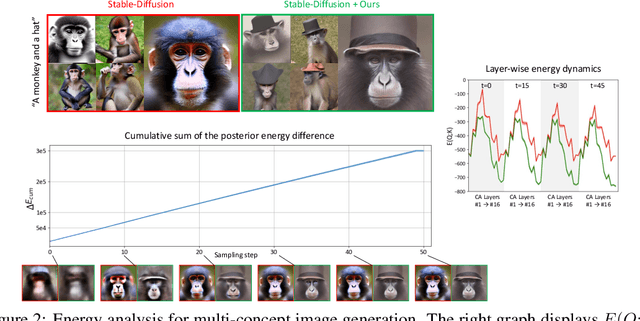

Despite the remarkable performance of text-to-image diffusion models in image generation tasks, recent studies have raised the issue that generated images sometimes cannot capture the intended semantic contents of the text prompts, which phenomenon is often called semantic misalignment. To address this, here we present a novel energy-based model (EBM) framework. Specifically, we first formulate EBMs of latent image representations and text embeddings in each cross-attention layer of the denoising autoencoder. Then, we obtain the gradient of the log posterior of context vectors, which can be updated and transferred to the subsequent cross-attention layer, thereby implicitly minimizing a nested hierarchy of energy functions. Our latent EBMs further allow zero-shot compositional generation as a linear combination of cross-attention outputs from different contexts. Using extensive experiments, we demonstrate that the proposed method is highly effective in handling various image generation tasks, including multi-concept generation, text-guided image inpainting, and real and synthetic image editing.
Unpaired Image-to-Image Translation via Neural Schrödinger Bridge
May 24, 2023Diffusion models are a powerful class of generative models which simulate stochastic differential equations (SDEs) to generate data from noise. Although diffusion models have achieved remarkable progress in recent years, they have limitations in the unpaired image-to-image translation tasks due to the Gaussian prior assumption. Schr\"odinger Bridge (SB), which learns an SDE to translate between two arbitrary distributions, have risen as an attractive solution to this problem. However, none of SB models so far have been successful at unpaired translation between high-resolution images. In this work, we propose the Unpaired Neural Schr\"odinger Bridge (UNSB), which combines SB with adversarial training and regularization to learn a SB between unpaired data. We demonstrate that UNSB is scalable, and that it successfully solves various unpaired image-to-image translation tasks. Code: \url{https://github.com/cyclomon/UNSB}
Bridging Active Exploration and Uncertainty-Aware Deployment Using Probabilistic Ensemble Neural Network Dynamics
May 20, 2023In recent years, learning-based control in robotics has gained significant attention due to its capability to address complex tasks in real-world environments. With the advances in machine learning algorithms and computational capabilities, this approach is becoming increasingly important for solving challenging control problems in robotics by learning unknown or partially known robot dynamics. Active exploration, in which a robot directs itself to states that yield the highest information gain, is essential for efficient data collection and minimizing human supervision. Similarly, uncertainty-aware deployment has been a growing concern in robotic control, as uncertain actions informed by the learned model can lead to unstable motions or failure. However, active exploration and uncertainty-aware deployment have been studied independently, and there is limited literature that seamlessly integrates them. This paper presents a unified model-based reinforcement learning framework that bridges these two tasks in the robotics control domain. Our framework uses a probabilistic ensemble neural network for dynamics learning, allowing the quantification of epistemic uncertainty via Jensen-Renyi Divergence. The two opposing tasks of exploration and deployment are optimized through state-of-the-art sampling-based MPC, resulting in efficient collection of training data and successful avoidance of uncertain state-action spaces. We conduct experiments on both autonomous vehicles and wheeled robots, showing promising results for both exploration and deployment.