 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Diffusion Model Distillation
Dec 12, 2024Diffusion distillation models effectively accelerate reverse sampling by compressing the process into fewer steps. However, these models still exhibit a performance gap compared to their pre-trained diffusion model counterparts, exacerbated by distribution shifts and accumulated errors during multi-step sampling. To address this, we introduce Distillation++, a novel inference-time distillation framework that reduces this gap by incorporating teacher-guided refinement during sampling. Inspired by recent advances in conditional sampling, our approach recasts student model sampling as a proximal optimization problem with a score distillation sampling loss (SDS). To this end, we integrate distillation optimization during reverse sampling, which can be viewed as teacher guidance that drives student sampling trajectory towards the clean manifold using pre-trained diffusion models. Thus, Distillation++ improves the denoising process in real-time without additional source data or fine-tuning. Distillation++ demonstrates substantial improvements over state-of-the-art distillation baselines, particularly in early sampling stages, positioning itself as a robust guided sampling process crafted for diffusion distillation models. Code: https://github.com/geonyeong-park/inference_distillation.
Pretraining with Random Noise for Fast and Robust Learning without Weight Transport
May 27, 2024The brain prepares for learning even before interacting with the environment, by refining and optimizing its structures through spontaneous neural activity that resembles random noise. However, the mechanism of such a process has yet to be thoroughly understood, and it is unclear whether this process can benefit the algorithm of machine learning. Here, we study this issue using a neural network with a feedback alignment algorithm, demonstrating that pretraining neural networks with random noise increases the learning efficiency as well as generalization abilities without weight transport. First, we found that random noise training modifies forward weights to match backward synaptic feedback, which is necessary for teaching errors by feedback alignment. As a result, a network with pre-aligned weights learns notably faster than a network without random noise training, even reaching a convergence speed comparable to that of a backpropagation algorithm. Sequential training with both random noise and data brings weights closer to synaptic feedback than training solely with data, enabling more precise credit assignment and faster learning. We also found that each readout probability approaches the chance level and that the effective dimensionality of weights decreases in a network pretrained with random noise. This pre-regularization allows the network to learn simple solutions of a low rank, reducing the generalization loss during subsequent training. This also enables the network robustly to generalize a novel, out-of-distribution dataset. Lastly, we confirmed that random noise pretraining reduces the amount of meta-loss, enhancing the network ability to adapt to various tasks. Overall, our results suggest that random noise training with feedback alignment offers a straightforward yet effective method of pretraining that facilitates quick and reliable learning without weight transport.
Spectral Motion Alignment for Video Motion Transfer using Diffusion Models
Mar 22, 2024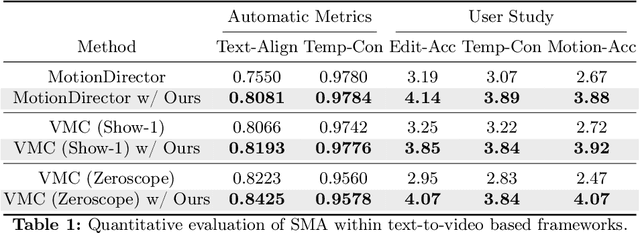
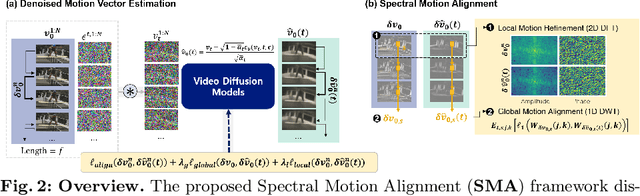
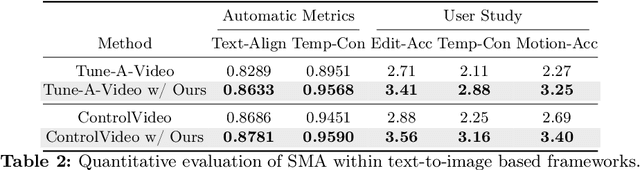

The evolution of diffusion models has greatly impacted video generation and understanding. Particularly, text-to-video diffusion models (VDMs) have significantly facilitated the customization of input video with target appearance, motion, etc. Despite these advances, challenges persist in accurately distilling motion information from video frames. While existing works leverage the consecutive frame residual as the target motion vector, they inherently lack global motion context and are vulnerable to frame-wise distortions. To address this, we present Spectral Motion Alignment (SMA), a novel framework that refines and aligns motion vectors using Fourier and wavelet transforms. SMA learns motion patterns by incorporating frequency-domain regularization, facilitating the learning of whole-frame global motion dynamics, and mitigating spatial artifacts. Extensive experiments demonstrate SMA's efficacy in improving motion transfer while maintaining computational efficiency and compatibility across various video customization frameworks.
Energy-Based Cross Attention for Bayesian Context Update in Text-to-Image Diffusion Models
Jun 26, 2023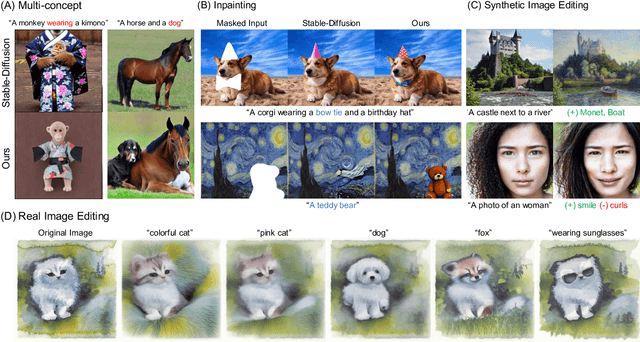
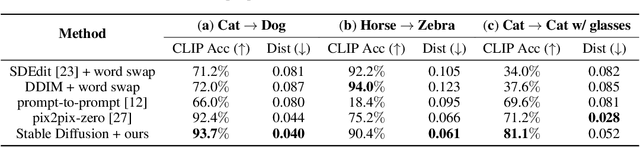
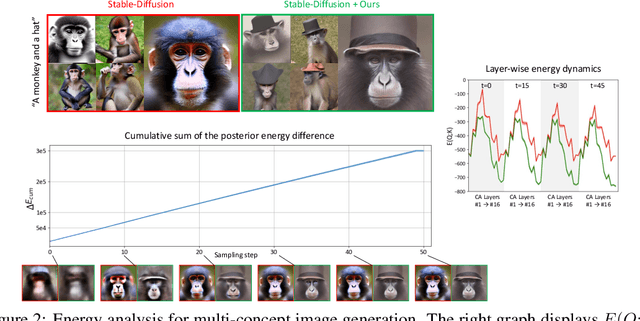

Despite the remarkable performance of text-to-image diffusion models in image generation tasks, recent studies have raised the issue that generated images sometimes cannot capture the intended semantic contents of the text prompts, which phenomenon is often called semantic misalignment. To address this, here we present a novel energy-based model (EBM) framework. Specifically, we first formulate EBMs of latent image representations and text embeddings in each cross-attention layer of the denoising autoencoder. Then, we obtain the gradient of the log posterior of context vectors, which can be updated and transferred to the subsequent cross-attention layer, thereby implicitly minimizing a nested hierarchy of energy functions. Our latent EBMs further allow zero-shot compositional generation as a linear combination of cross-attention outputs from different contexts. Using extensive experiments, we demonstrate that the proposed method is highly effective in handling various image generation tasks, including multi-concept generation, text-guided image inpainting, and real and synthetic image editing.
Efficient debiasing with contrastive weight pruning
Oct 11, 2022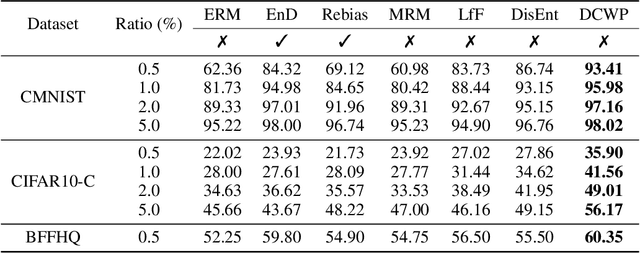
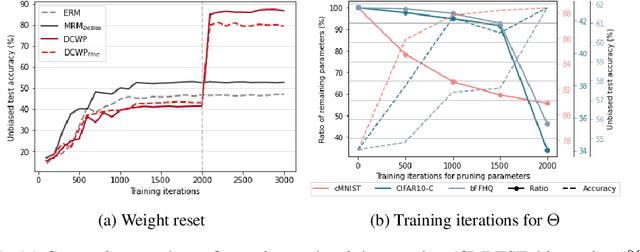
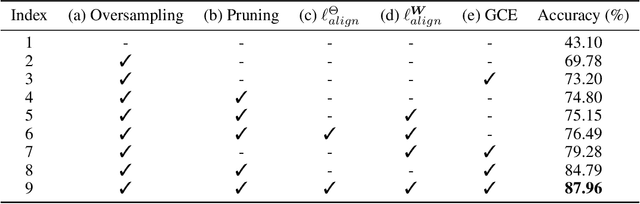
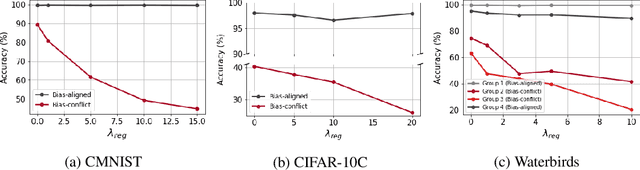
Neural networks are often biased to spuriously correlated features that provide misleading statistical evidence that does not generalize. This raises a fundamental question: "Does an optimal unbiased functional subnetwork exist in a severely biased network? If so, how to extract such subnetwork?" While few studies have revealed the existence of such optimal subnetworks with the guidance of ground-truth unbiased samples, the way to discover the optimal subnetworks with biased training dataset is still unexplored in practice. To address this, here we first present our theoretical insight that alerts potential limitations of existing algorithms in exploring unbiased subnetworks in the presence of strong spurious correlations. We then further elucidate the importance of bias-conflicting samples on structure learning. Motivated by these observations, we propose a Debiased Contrastive Weight Pruning (DCWP) algorithm, which probes unbiased subnetworks without expensive group annotations. Experimental results demonstrate that our approach significantly outperforms state-of-the-art debiasing methods despite its considerable reduction in the number of parameters.
Self-supervised debiasing using low rank regularization
Oct 11, 2022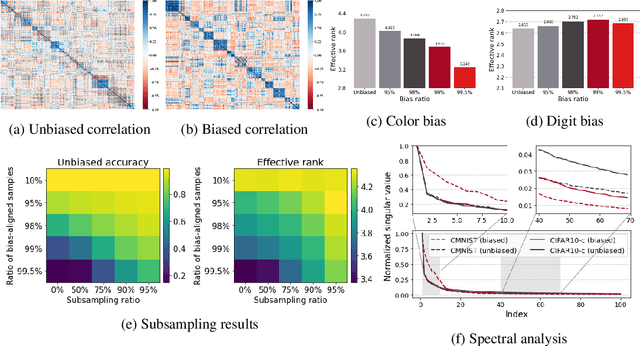

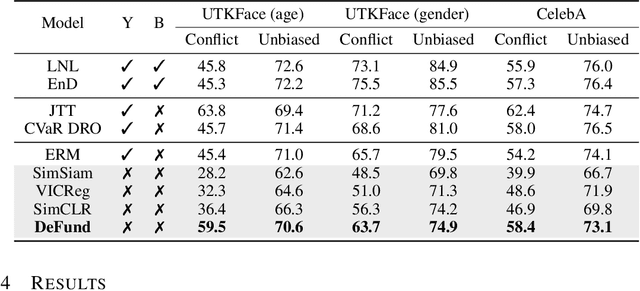
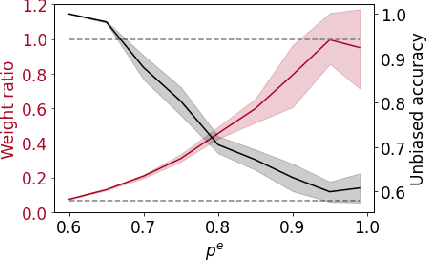
Spurious correlations can cause strong biases in deep neural networks, impairing generalization ability. While most of existing debiasing methods require full supervisions on either spurious attributes or target labels, training a debiased model from a limited amount of both annotations is still an open issue. To overcome such limitations, we first examined an interesting phenomenon by the spectral analysis of latent representations: spuriously correlated, easy-to-learn attributes make neural networks inductively biased towards encoding lower effective rank representations. We also show that a rank regularization can amplify this bias in a way that encourages highly correlated features. Motivated by these observations, we propose a self-supervised debiasing framework that is potentially compatible with unlabeled samples. We first pretrain a biased encoder in a self-supervised manner with the rank regularization, serving as a semantic bottleneck to enforce the encoder to learn the spuriously correlated attributes. This biased encoder is then used to discover and upweight bias-conflicting samples in a downstream task, serving as a boosting to effectively debias the main model. Remarkably, the proposed debiasing framework significantly improves the generalization performance of self-supervised learning baselines and, in some cases, even outperforms state-of-the-art supervised debiasing approaches.
The emergence of division of labor through decentralized social sanctioning
Aug 12, 2022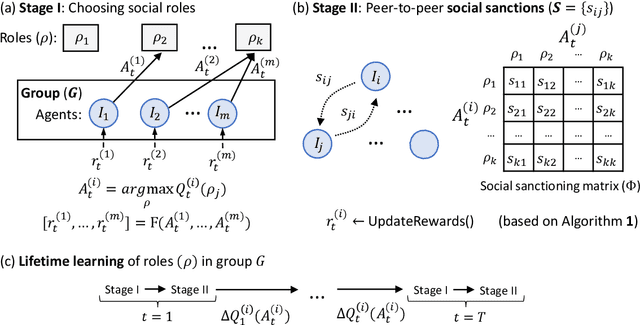

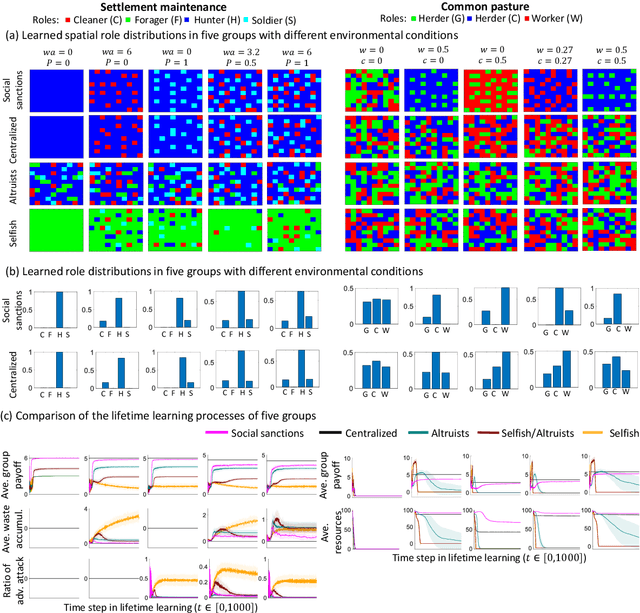
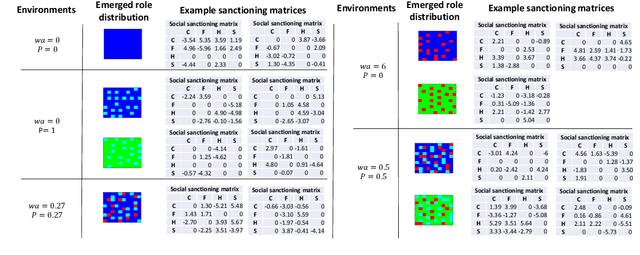
Human ecological success relies on our characteristic ability to flexibly self-organize in cooperative social groups. Successful groups employ substantial specialization and division of labor. Unlike most other animals, humans learn by trial and error during their lives what role to take on. However, when some critical roles are more attractive than others, and individuals are self-interested, then there is a social dilemma: each individual would prefer others take on the critical-but-unremunerative roles so they may remain free to take one that pays better. But disaster occurs if all act thusly and a critical role goes unfilled. In such situations learning an optimum role distribution may not be possible. Consequently, a fundamental question is: how can division of labor emerge in groups of self-interested lifetime-learning individuals? Here we show that by introducing a model of social norms, which we regard as patterns of decentralized social sanctioning, it becomes possible for groups of self-interested individuals to learn a productive division of labor involving all critical roles. Such social norms work by redistributing rewards within the population to disincentivize antisocial roles while incentivizing prosocial roles that do not intrinsically pay as well as others.
Meta-control of social learning strategies
Jun 18, 2021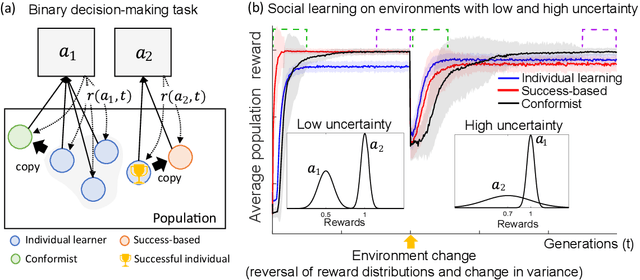

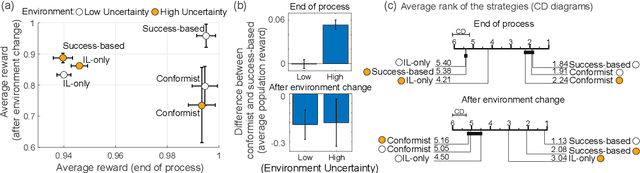

Social learning, copying other's behavior without actual experience, offers a cost-effective means of knowledge acquisition. However, it raises the fundamental question of which individuals have reliable information: successful individuals versus the majority. The former and the latter are known respectively as success-based and conformist social learning strategies. We show here that while the success-based strategy fully exploits the benign environment of low uncertainly, it fails in uncertain environments. On the other hand, the conformist strategy can effectively mitigate this adverse effect. Based on these findings, we hypothesized that meta-control of individual and social learning strategies provides effective and sample-efficient learning in volatile and uncertain environments. Simulations on a set of environments with various levels of volatility and uncertainty confirmed our hypothesis. The results imply that meta-control of social learning affords agents the leverage to resolve environmental uncertainty with minimal exploration cost, by exploiting others' learning as an external knowledge base.
Reliably fast adversarial training via latent adversarial perturbation
Apr 04, 2021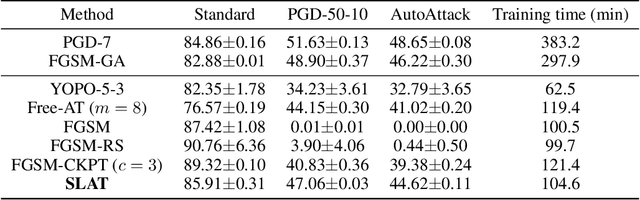
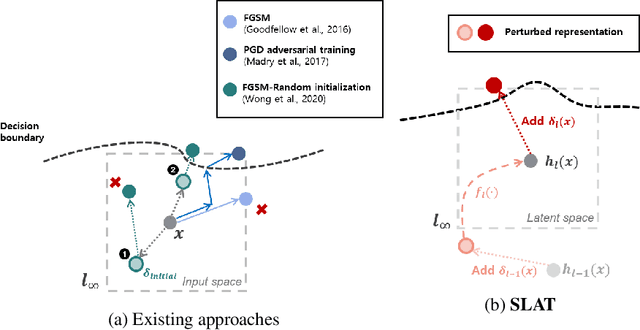
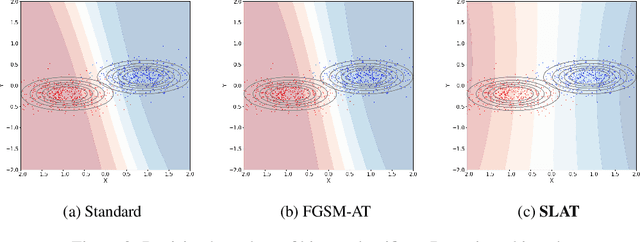

While multi-step adversarial training is widely popular as an effective defense method against strong adversarial attacks, its computational cost is notoriously expensive, compared to standard training. Several single-step adversarial training methods have been proposed to mitigate the above-mentioned overhead cost; however, their performance is not sufficiently reliable depending on the optimization setting. To overcome such limitations, we deviate from the existing input-space-based adversarial training regime and propose a single-step latent adversarial training method (SLAT), which leverages the gradients of latent representation as the latent adversarial perturbation. We demonstrate that the L1 norm of feature gradients is implicitly regularized through the adopted latent perturbation, thereby recovering local linearity and ensuring reliable performance, compared to the existing single-step adversarial training methods. Because latent perturbation is based on the gradients of the latent representations which can be obtained for free in the process of input gradients computation, the proposed method costs roughly the same time as the fast gradient sign method. Experiment results demonstrate that the proposed method, despite its structural simplicity, outperforms state-of-the-art accelerated adversarial training methods.
Information-theoretic regularization for Multi-source Domain Adaptation
Apr 04, 2021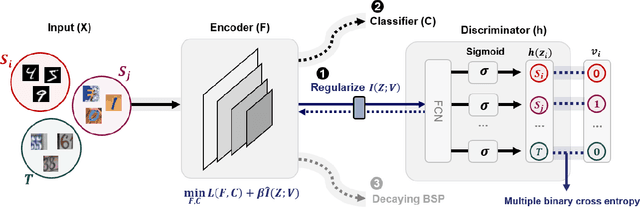
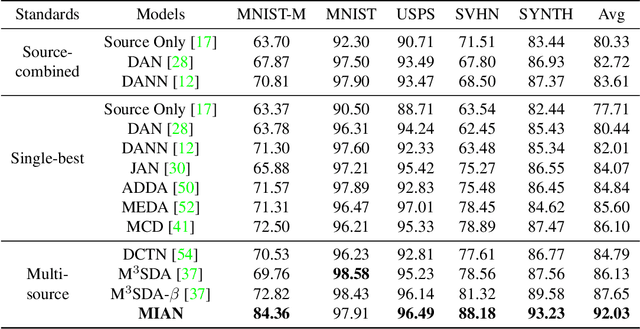
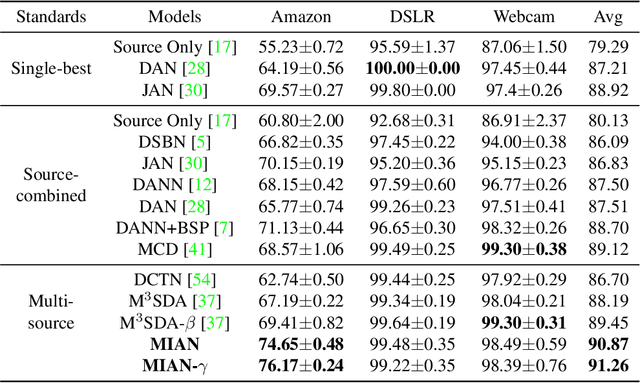
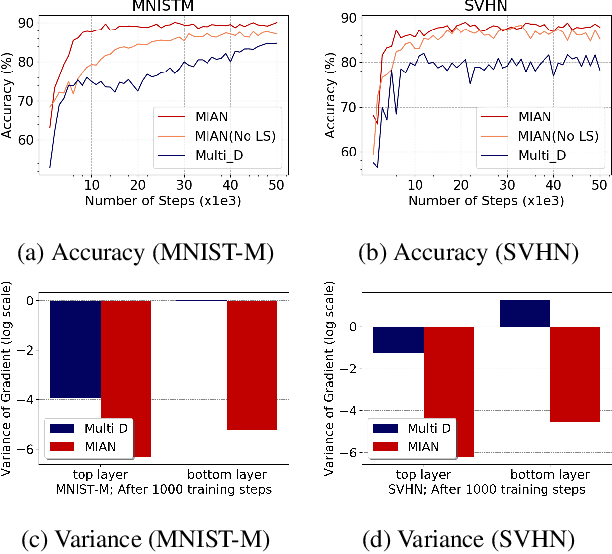
Adversarial learning strategy has demonstrated remarkable performance in dealing with single-source Domain Adaptation (DA) problems, and it has recently been applied to Multi-source DA (MDA) problems. Although most existing MDA strategies rely on a multiple domain discriminator setting, its effect on the latent space representations has been poorly understood. Here we adopt an information-theoretic approach to identify and resolve the potential adverse effect of the multiple domain discriminators on MDA: disintegration of domain-discriminative information, limited computational scalability, and a large variance in the gradient of the loss during training. We examine the above issues by situating adversarial DA in the context of information regularization. This also provides a theoretical justification for using a single and unified domain discriminator. Based on this idea, we implement a novel neural architecture called a Multi-source Information-regularized Adaptation Networks (MIAN). Large-scale experiments demonstrate that MIAN, despite its structural simplicity, reliably and significantly outperforms other state-of-the-art methods.