 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Matters: Fast Model-Agnostic Data Curation for Pruning and Quantization
Mar 17, 2026Post-training model compression is essential for enhancing the portability of Large Language Models (LLMs) while preserving their performance. While several compression approaches have been proposed, less emphasis has been placed on selecting the most suitable set of data (the so-called \emph{calibration data}) for finding the compressed model configuration. The choice of calibration data is a critical step in preserving model capabilities both intra- and inter-tasks. In this work, we address the challenge of identifying high-performance calibration sets for both pruning and quantization by analyzing intrinsic data properties rather than model-specific signals. We introduce \texttt{\textbf{ZipCal}}, a model-agnostic data curation strategy that maximizes lexical diversity based on Zipfian power laws. Experiments demonstrate that our method consistently outperforms standard uniform random sampling across various pruning benchmarks. Notably, it also performs on par, in terms of downstream performance, with a state-of-the-art method that relies on model perplexity. The latter becomes prohibitively expensive at large-scale models and datasets, while \texttt{\textbf{ZipCal}} is on average $\sim$240$\times$ faster due to its tractable linear complexity\footnote{We make the code and the experiments available at https://anonymous.4open.science/r/zipcal-71CD/.}.
Generative AI collective behavior needs an interactionist paradigm
Jan 15, 2026In this article, we argue that understanding the collective behavior of agents based on large language models (LLMs) is an essential area of inquiry, with important implications in terms of risks and benefits, impacting us as a society at many levels. We claim that the distinctive nature of LLMs--namely, their initialization with extensive pre-trained knowledge and implicit social priors, together with their capability of adaptation through in-context learning--motivates the need for an interactionist paradigm consisting of alternative theoretical foundations, methodologies, and analytical tools, in order to systematically examine how prior knowledge and embedded values interact with social context to shape emergent phenomena in multi-agent generative AI systems. We propose and discuss four directions that we consider crucial for the development and deployment of LLM-based collectives, focusing on theory, methods, and trans-disciplinary dialogue.
Neural Brain: A Neuroscience-inspired Framework for Embodied Agents
May 14, 2025The rapid evolution of artificial intelligence (AI) has shifted from static, data-driven models to dynamic systems capable of perceiving and interacting with real-world environments. Despite advancements in pattern recognition and symbolic reasoning, current AI systems, such as large language models, remain disembodied, unable to physically engage with the world. This limitation has driven the rise of embodied AI, where autonomous agents, such as humanoid robots, must navigate and manipulate unstructured environments with human-like adaptability. At the core of this challenge lies the concept of Neural Brain, a central intelligence system designed to drive embodied agents with human-like adaptability. A Neural Brain must seamlessly integrate multimodal sensing and perception with cognitive capabilities. Achieving this also requires an adaptive memory system and energy-efficient hardware-software co-design, enabling real-time action in dynamic environments. This paper introduces a unified framework for the Neural Brain of embodied agents, addressing two fundamental challenges: (1) defining the core components of Neural Brain and (2) bridging the gap between static AI models and the dynamic adaptability required for real-world deployment. To this end, we propose a biologically inspired architecture that integrates multimodal active sensing, perception-cognition-action function, neuroplasticity-based memory storage and updating, and neuromorphic hardware/software optimization. Furthermore, we also review the latest research on embodied agents across these four aspects and analyze the gap between current AI systems and human intelligence. By synthesizing insights from neuroscience, we outline a roadmap towards the development of generalizable, autonomous agents capable of human-level intelligence in real-world scenarios.
Nature's Insight: A Novel Framework and Comprehensive Analysis of Agentic Reasoning Through the Lens of Neuroscience
May 07, 2025Autonomous AI is no longer a hard-to-reach concept, it enables the agents to move beyond executing tasks to independently addressing complex problems, adapting to change while handling the uncertainty of the environment. However, what makes the agents truly autonomous? It is agentic reasoning, that is crucial for foundation models to develop symbolic logic, statistical correlations, or large-scale pattern recognition to process information, draw inferences, and make decisions. However, it remains unclear why and how existing agentic reasoning approaches work, in comparison to biological reasoning, which instead is deeply rooted in neural mechanisms involving hierarchical cognition, multimodal integration, and dynamic interactions. In this work, we propose a novel neuroscience-inspired framework for agentic reasoning. Grounded in three neuroscience-based definitions and supported by mathematical and biological foundations, we propose a unified framework modeling reasoning from perception to action, encompassing four core types, perceptual, dimensional, logical, and interactive, inspired by distinct functional roles observed in the human brain. We apply this framework to systematically classify and analyze existing AI reasoning methods, evaluating their theoretical foundations, computational designs, and practical limitations. We also explore its implications for building more generalizable, cognitively aligned agents in physical and virtual environments. Finally, building on our framework, we outline future directions and propose new neural-inspired reasoning methods, analogous to chain-of-thought prompting. By bridging cognitive neuroscience and AI, this work offers a theoretical foundation and practical roadmap for advancing agentic reasoning in intelligent systems. The associated project can be found at: https://github.com/BioRAILab/Awesome-Neuroscience-Agent-Reasoning .
Rethinking Few-Shot Adaptation of Vision-Language Models in Two Stages
Mar 14, 2025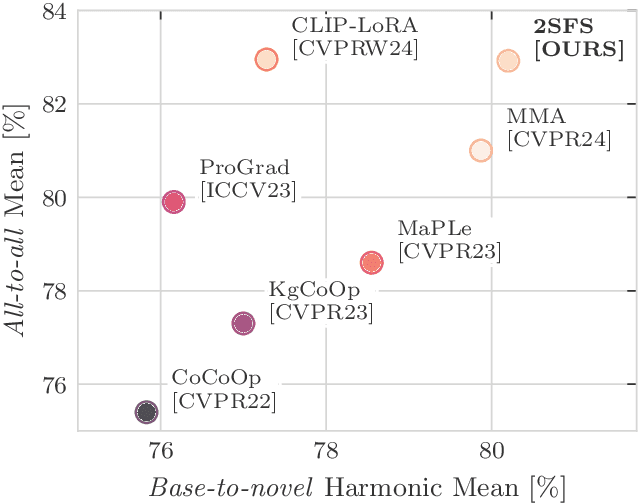
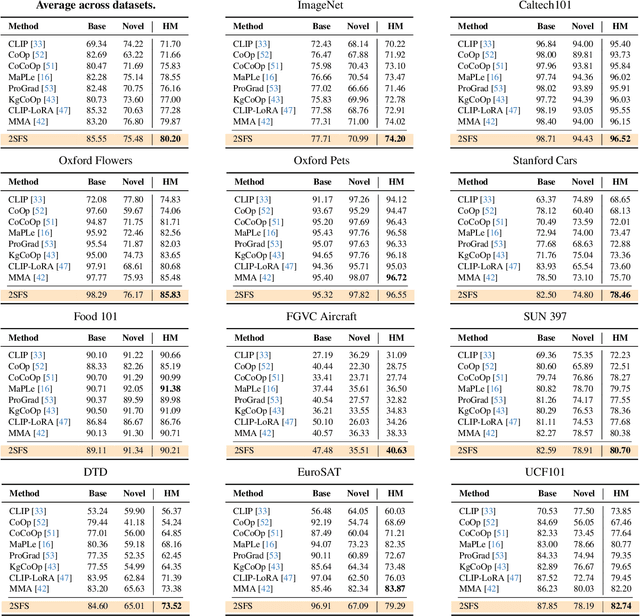
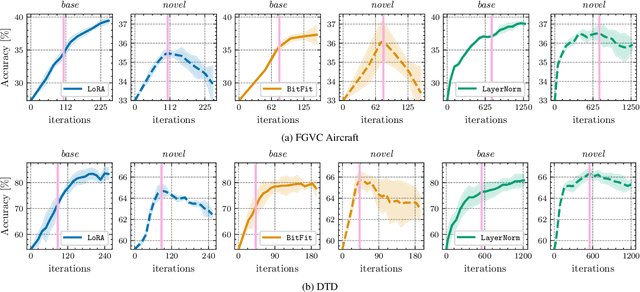
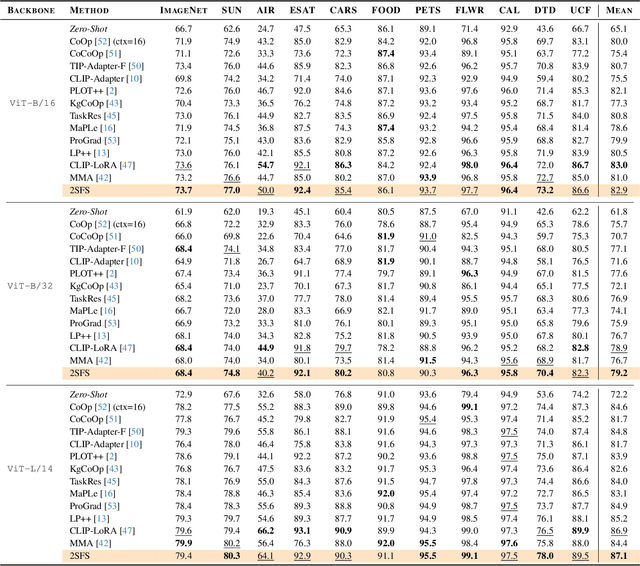
An old-school recipe for training a classifier is to (i) learn a good feature extractor and (ii) optimize a linear layer atop. When only a handful of samples are available per category, as in Few-Shot Adaptation (FSA), data are insufficient to fit a large number of parameters, rendering the above impractical. This is especially true with large pre-trained Vision-Language Models (VLMs), which motivated successful research at the intersection of Parameter-Efficient Fine-tuning (PEFT) and FSA. In this work, we start by analyzing the learning dynamics of PEFT techniques when trained on few-shot data from only a subset of categories, referred to as the ``base'' classes. We show that such dynamics naturally splits into two distinct phases: (i) task-level feature extraction and (ii) specialization to the available concepts. To accommodate this dynamic, we then depart from prompt- or adapter-based methods and tackle FSA differently. Specifically, given a fixed computational budget, we split it to (i) learn a task-specific feature extractor via PEFT and (ii) train a linear classifier on top. We call this scheme Two-Stage Few-Shot Adaptation (2SFS). Differently from established methods, our scheme enables a novel form of selective inference at a category level, i.e., at test time, only novel categories are embedded by the adapted text encoder, while embeddings of base categories are available within the classifier. Results with fixed hyperparameters across two settings, three backbones, and eleven datasets, show that 2SFS matches or surpasses the state-of-the-art, while established methods degrade significantly across settings.
2SSP: A Two-Stage Framework for Structured Pruning of LLMs
Jan 29, 2025
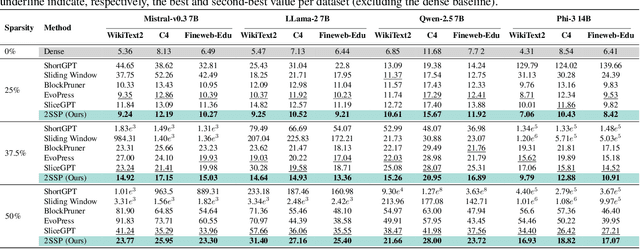
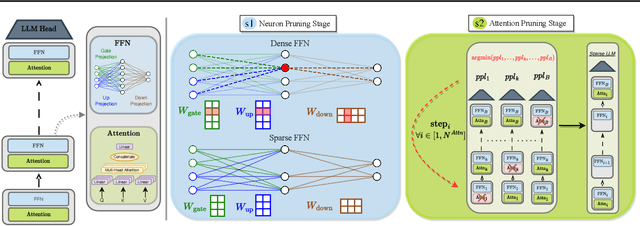
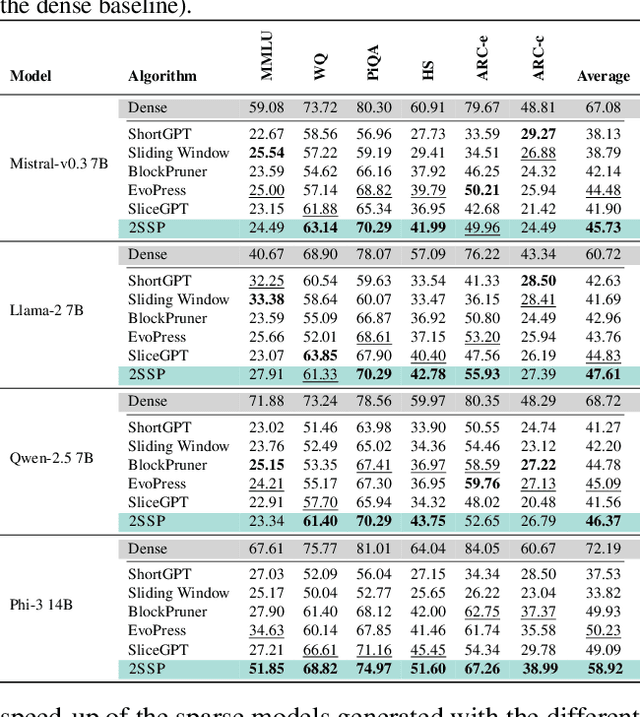
We propose a novel Two-Stage framework for Structured Pruning (2SSP) for pruning Large Language Models (LLMs), which combines two different strategies of pruning, namely Width and Depth Pruning. The first stage (Width Pruning) removes entire neurons, hence their corresponding rows and columns, aiming to preserve the connectivity among the pruned structures in the intermediate state of the Feed-Forward Networks in each Transformer block. This is done based on an importance score measuring the impact of each neuron over the output magnitude. The second stage (Depth Pruning), instead, removes entire Attention submodules. This is done by applying an iterative process that removes the Attention submodules with the minimum impact on a given metric of interest (in our case, perplexity). We also propose a novel mechanism to balance the sparsity rate of the two stages w.r.t. to the desired global sparsity. We test 2SSP on four LLM families and three sparsity rates (25\%, 37.5\%, and 50\%), measuring the resulting perplexity over three language modeling datasets as well as the performance over six downstream tasks. Our method consistently outperforms five state-of-the-art competitors over three language modeling and six downstream tasks, with an up to two-order-of-magnitude gain in terms of pruning time. The code is available at available at \url{https://github.com/FabrizioSandri/2SSP}.
SMOSE: Sparse Mixture of Shallow Experts for Interpretable Reinforcement Learning in Continuous Control Tasks
Dec 17, 2024



Continuous control tasks often involve high-dimensional, dynamic, and non-linear environments. State-of-the-art performance in these tasks is achieved through complex closed-box policies that are effective, but suffer from an inherent opacity. Interpretable policies, while generally underperforming compared to their closed-box counterparts, advantageously facilitate transparent decision-making within automated systems. Hence, their usage is often essential for diagnosing and mitigating errors, supporting ethical and legal accountability, and fostering trust among stakeholders. In this paper, we propose SMOSE, a novel method to train sparsely activated interpretable controllers, based on a top-1 Mixture-of-Experts architecture. SMOSE combines a set of interpretable decisionmakers, trained to be experts in different basic skills, and an interpretable router that assigns tasks among the experts. The training is carried out via state-of-the-art Reinforcement Learning algorithms, exploiting load-balancing techniques to ensure fair expert usage. We then distill decision trees from the weights of the router, significantly improving the ease of interpretation. We evaluate SMOSE on six benchmark environments from MuJoCo: our method outperforms recent interpretable baselines and narrows the gap with noninterpretable state-of-the-art algorithms
Zeroth-Order Adaptive Neuron Alignment Based Pruning without Re-Training
Nov 11, 2024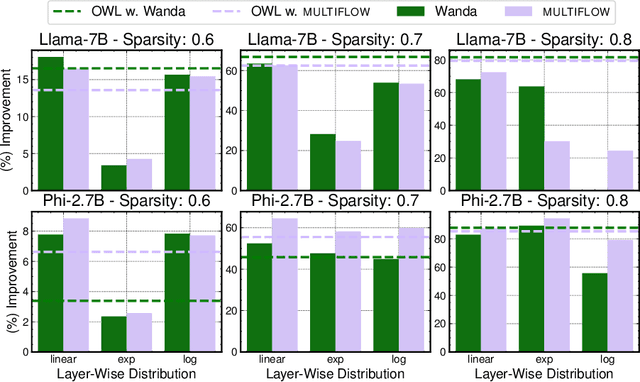
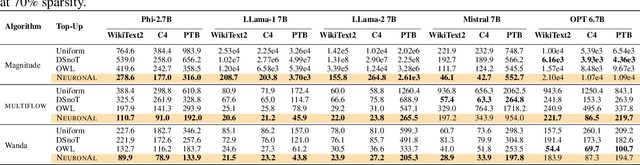
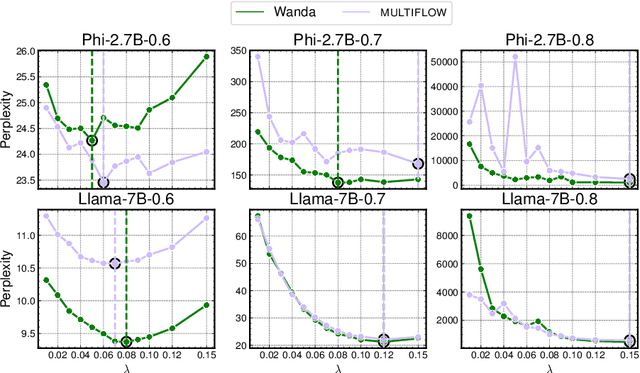
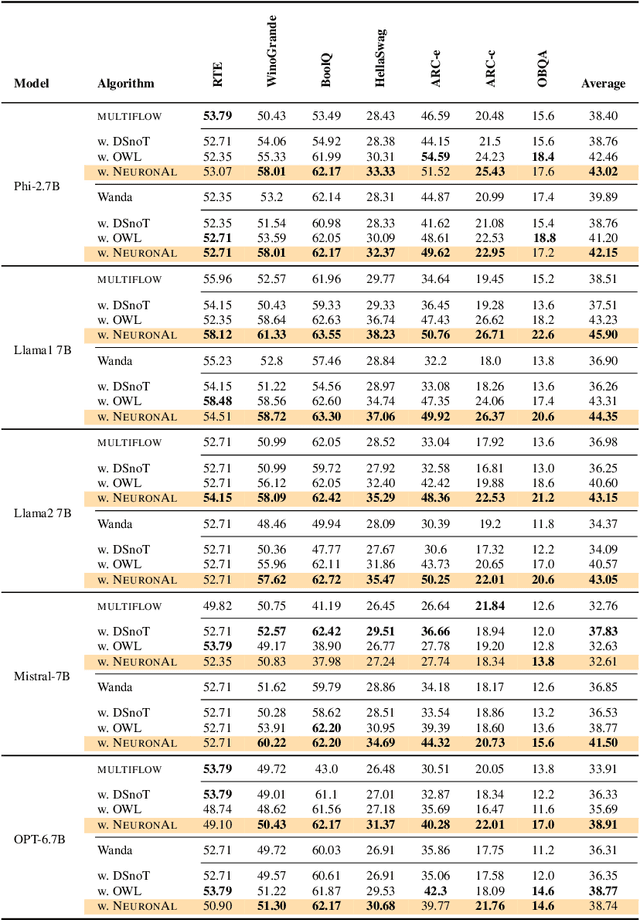
Network pruning is a set of computational techniques that aim to reduce a given model's computational cost by removing a subset of its parameters while having minimal impact on performance. Throughout the last decade, the most widely used pruning paradigm has focused on pruning and re-training, which nowadays is inconvenient due to the vast amount of pre-trained models, which are in any case too expensive to re-train. In this paper, we exploit functional information from dense pre-trained models, i.e., their activations, to obtain sparse models that maximize the activations' alignment w.r.t. their corresponding dense models. Hence, we propose \textsc{NeuroAl}, a \emph{top-up} algorithm that can be used on top of any given pruning algorithm for LLMs, that modifies the block-wise and row-wise sparsity ratios to maximize the \emph{neuron alignment} among activations. Moreover, differently from existing methods, our approach adaptively selects the best parameters for the block-wise and row-wise sparsity ratios w.r.t. to the model and the desired sparsity (given as input), and requires \emph{no re-training}. We test our method on 4 different LLM families and 3 different sparsity ratios, showing how it consistently outperforms the latest state-of-the-art techniques. The code is available at https://github.com/eliacunegatti/NeuroAL.
An investigation on the use of Large Language Models for hyperparameter tuning in Evolutionary Algorithms
Aug 05, 2024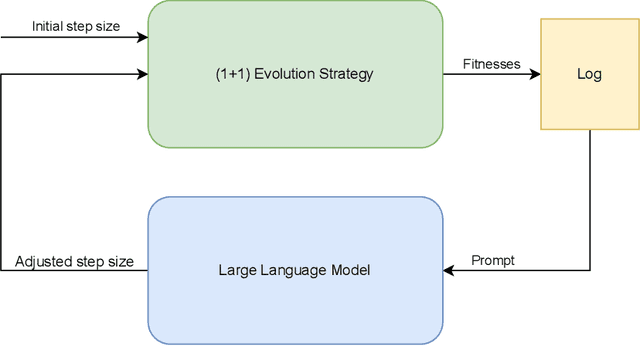

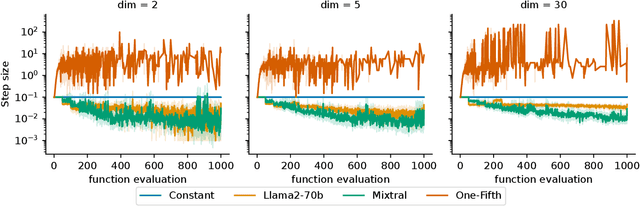

Hyperparameter optimization is a crucial problem in Evolutionary Computation. In fact, the values of the hyperparameters directly impact the trajectory taken by the optimization process, and their choice requires extensive reasoning by human operators. Although a variety of self-adaptive Evolutionary Algorithms have been proposed in the literature, no definitive solution has been found. In this work, we perform a preliminary investigation to automate the reasoning process that leads to the choice of hyperparameter values. We employ two open-source Large Language Models (LLMs), namely Llama2-70b and Mixtral, to analyze the optimization logs online and provide novel real-time hyperparameter recommendations. We study our approach in the context of step-size adaptation for (1+1)-ES. The results suggest that LLMs can be an effective method for optimizing hyperparameters in Evolution Strategies, encouraging further research in this direction.
The Effect of Training Schedules on Morphological Robustness and Generalization
Jul 19, 2024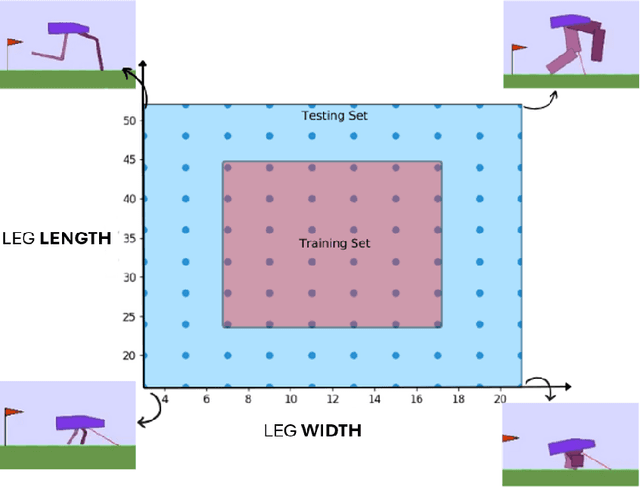
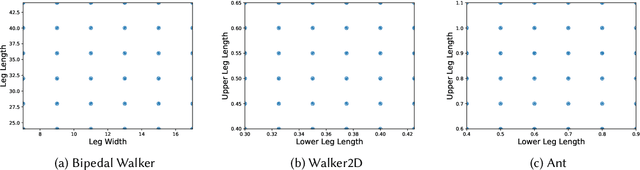
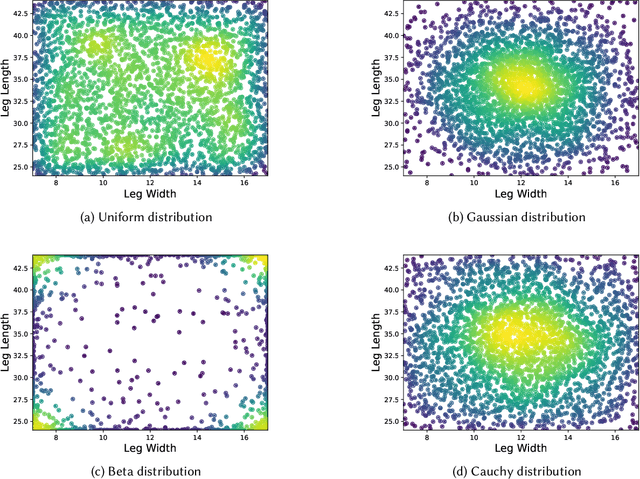
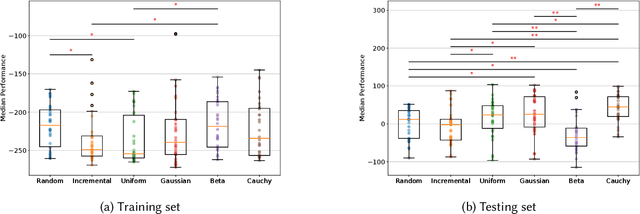
Robustness and generalizability are the key properties of artificial neural network (ANN)-based controllers for maintaining a reliable performance in case of changes. It is demonstrated that exposing the ANNs to variations during training processes can improve their robustness and generalization capabilities. However, the way in which this variation is introduced can have a significant impact. In this paper, we define various training schedules to specify how these variations are introduced during an evolutionary learning process. In particular, we focus on morphological robustness and generalizability concerned with finding an ANN-based controller that can provide sufficient performance on a range of physical variations. Then, we perform an extensive analysis of the effect of these training schedules on morphological generalization. Furthermore, we formalize the process of training sample selection (i.e., morphological variations) to improve generalization as a reinforcement learning problem. Overall, our results provide deeper insights into the role of variability and the ways of enhancing the generalization property of evolved ANN-based controllers.