 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMOSE: Sparse Mixture of Shallow Experts for Interpretable Reinforcement Learning in Continuous Control Tasks
Dec 17, 2024



Continuous control tasks often involve high-dimensional, dynamic, and non-linear environments. State-of-the-art performance in these tasks is achieved through complex closed-box policies that are effective, but suffer from an inherent opacity. Interpretable policies, while generally underperforming compared to their closed-box counterparts, advantageously facilitate transparent decision-making within automated systems. Hence, their usage is often essential for diagnosing and mitigating errors, supporting ethical and legal accountability, and fostering trust among stakeholders. In this paper, we propose SMOSE, a novel method to train sparsely activated interpretable controllers, based on a top-1 Mixture-of-Experts architecture. SMOSE combines a set of interpretable decisionmakers, trained to be experts in different basic skills, and an interpretable router that assigns tasks among the experts. The training is carried out via state-of-the-art Reinforcement Learning algorithms, exploiting load-balancing techniques to ensure fair expert usage. We then distill decision trees from the weights of the router, significantly improving the ease of interpretation. We evaluate SMOSE on six benchmark environments from MuJoCo: our method outperforms recent interpretable baselines and narrows the gap with noninterpretable state-of-the-art algorithms
Zeroth-Order Adaptive Neuron Alignment Based Pruning without Re-Training
Nov 11, 2024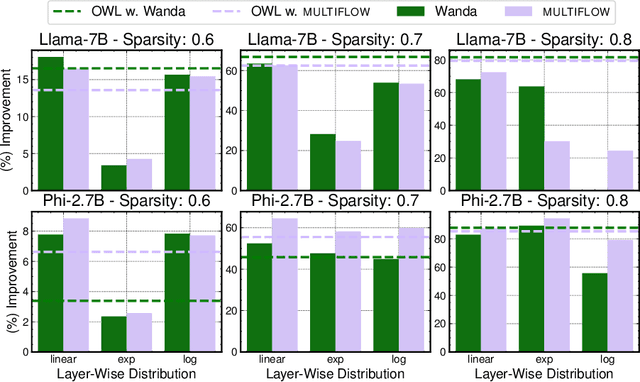
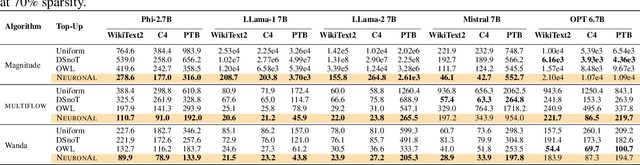
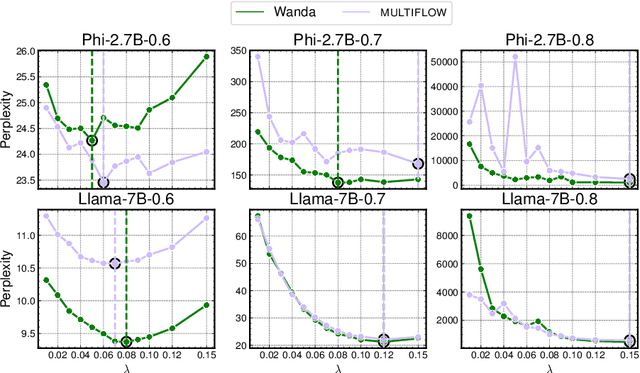
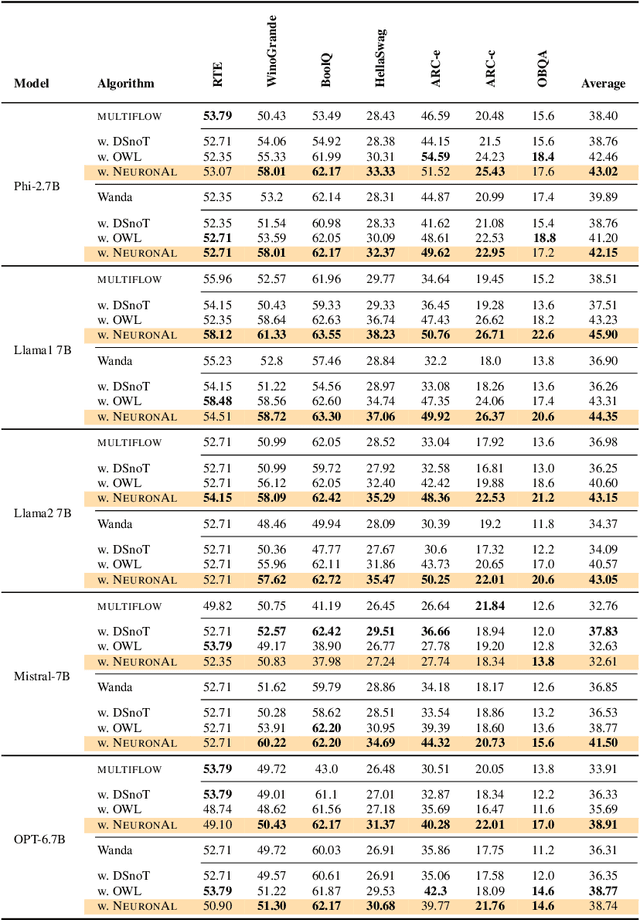
Network pruning is a set of computational techniques that aim to reduce a given model's computational cost by removing a subset of its parameters while having minimal impact on performance. Throughout the last decade, the most widely used pruning paradigm has focused on pruning and re-training, which nowadays is inconvenient due to the vast amount of pre-trained models, which are in any case too expensive to re-train. In this paper, we exploit functional information from dense pre-trained models, i.e., their activations, to obtain sparse models that maximize the activations' alignment w.r.t. their corresponding dense models. Hence, we propose \textsc{NeuroAl}, a \emph{top-up} algorithm that can be used on top of any given pruning algorithm for LLMs, that modifies the block-wise and row-wise sparsity ratios to maximize the \emph{neuron alignment} among activations. Moreover, differently from existing methods, our approach adaptively selects the best parameters for the block-wise and row-wise sparsity ratios w.r.t. to the model and the desired sparsity (given as input), and requires \emph{no re-training}. We test our method on 4 different LLM families and 3 different sparsity ratios, showing how it consistently outperforms the latest state-of-the-art techniques. The code is available at https://github.com/eliacunegatti/NeuroAL.
An investigation on the use of Large Language Models for hyperparameter tuning in Evolutionary Algorithms
Aug 05, 2024

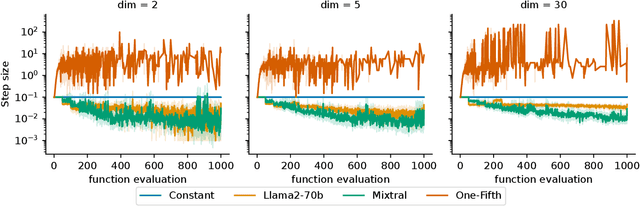

Hyperparameter optimization is a crucial problem in Evolutionary Computation. In fact, the values of the hyperparameters directly impact the trajectory taken by the optimization process, and their choice requires extensive reasoning by human operators. Although a variety of self-adaptive Evolutionary Algorithms have been proposed in the literature, no definitive solution has been found. In this work, we perform a preliminary investigation to automate the reasoning process that leads to the choice of hyperparameter values. We employ two open-source Large Language Models (LLMs), namely Llama2-70b and Mixtral, to analyze the optimization logs online and provide novel real-time hyperparameter recommendations. We study our approach in the context of step-size adaptation for (1+1)-ES. The results suggest that LLMs can be an effective method for optimizing hyperparameters in Evolution Strategies, encouraging further research in this direction.
Many-Objective Evolutionary Influence Maximization: Balancing Spread, Budget, Fairness, and Time
Mar 28, 2024
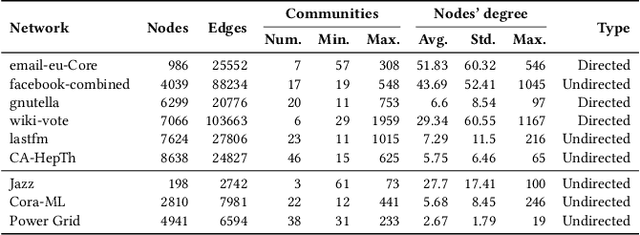
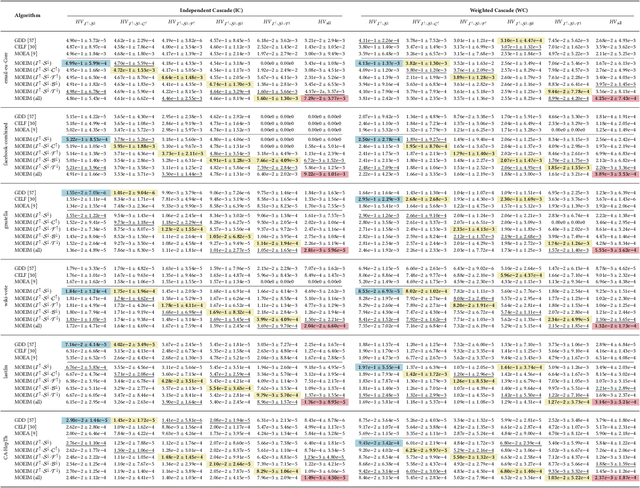
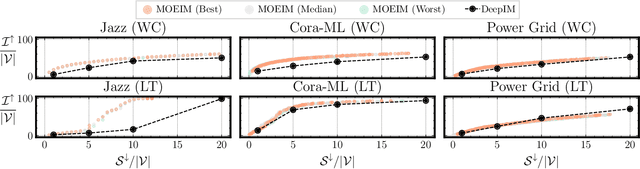
The Influence Maximization (IM) problem seeks to discover the set of nodes in a graph that can spread the information propagation at most. This problem is known to be NP-hard, and it is usually studied by maximizing the influence (spread) and, optionally, optimizing a second objective, such as minimizing the seed set size or maximizing the influence fairness. However, in many practical scenarios multiple aspects of the IM problem must be optimized at the same time. In this work, we propose a first case study where several IM-specific objective functions, namely budget, fairness, communities, and time, are optimized on top of the maximization of influence and minimization of the seed set size. To this aim, we introduce MOEIM (Many-Objective Evolutionary Algorithm for Influence Maximization) a Multi-Objective Evolutionary Algorithm (MOEA) based on NSGA-II incorporating graph-aware operators and a smart initialization. We compare MOEIM in two experimental settings, including a total of nine graph datasets, two heuristic methods, a related MOEA, and a state-of-the-art Deep Learning approach. The experiments show that MOEIM overall outperforms the competitors in most of the tested many-objective settings. To conclude, we also investigate the correlation between the objectives, leading to novel insights into the topic. The codebase is available at https://github.com/eliacunegatti/MOEIM.
Social Interpretable Reinforcement Learning
Jan 27, 2024Reinforcement Learning (RL) bears the promise of being an enabling technology for many applications. However, since most of the literature in the field is currently focused on opaque models, the use of RL in high-stakes scenarios, where interpretability is crucial, is still limited. Recently, some approaches to interpretable RL, e.g., based on Decision Trees, have been proposed, but one of the main limitations of these techniques is their training cost. To overcome this limitation, we propose a new population-based method, called Social Interpretable RL (SIRL), inspired by social learning principles, to improve learning efficiency. Our method mimics a social learning process, where each agent in a group learns to solve a given task based both on its own individual experience as well as the experience acquired together with its peers. Our approach is divided into two phases. In the \emph{collaborative phase}, all the agents in the population interact with a shared instance of the environment, where each agent observes the state and independently proposes an action. Then, voting is performed to choose the action that will actually be performed in the environment. In the \emph{individual phase}, each agent refines its individual performance by interacting with its own instance of the environment. This mechanism makes the agents experience a larger number of episodes while simultaneously reducing the computational cost of the process. Our results on six well-known benchmarks show that SIRL reaches state-of-the-art performance w.r.t. the alternative interpretable methods from the literature.
Quality Diversity Evolutionary Learning of Decision Trees
Aug 17, 2022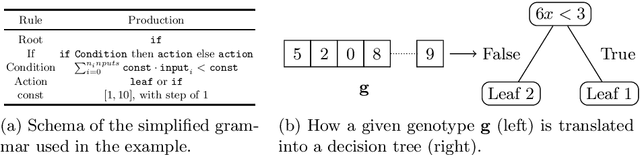
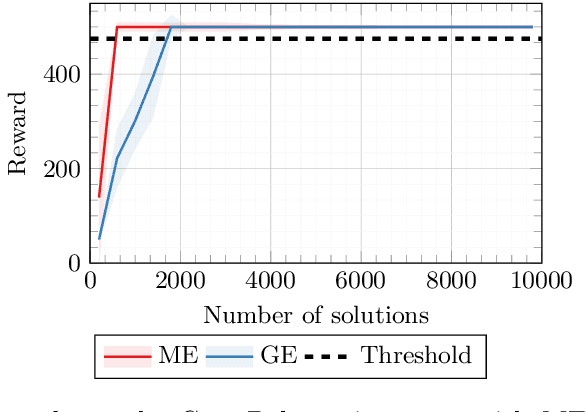
Addressing the need for explainable Machine Learning has emerged as one of the most important research directions in modern Artificial Intelligence (AI). While the current dominant paradigm in the field is based on black-box models, typically in the form of (deep) neural networks, these models lack direct interpretability for human users, i.e., their outcomes (and, even more so, their inner working) are opaque and hard to understand. This is hindering the adoption of AI in safety-critical applications, where high interests are at stake. In these applications, explainable by design models, such as decision trees, may be more suitable, as they provide interpretability. Recent works have proposed the hybridization of decision trees and Reinforcement Learning, to combine the advantages of the two approaches. So far, however, these works have focused on the optimization of those hybrid models. Here, we apply MAP-Elites for diversifying hybrid models over a feature space that captures both the model complexity and its behavioral variability. We apply our method on two well-known control problems from the OpenAI Gym library, on which we discuss the "illumination" patterns projected by MAP-Elites, comparing its results against existing similar approaches.
Interpretable AI for policy-making in pandemics
Apr 08, 2022

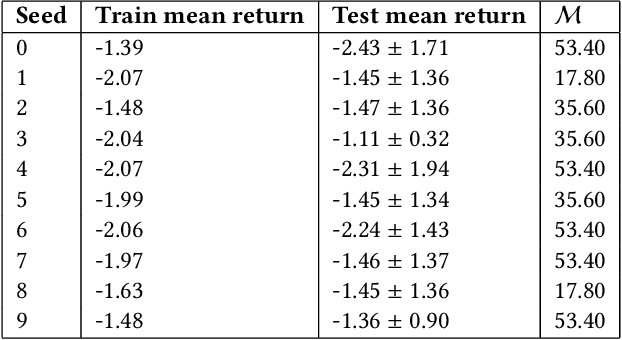

Since the first wave of the COVID-19 pandemic, governments have applied restrictions in order to slow down its spreading. However, creating such policies is hard, especially because the government needs to trade-off the spreading of the pandemic with the economic losses. For this reason, several works have applied machine learning techniques, often with the help of special-purpose simulators, to generate policies that were more effective than the ones obtained by governments. While the performance of such approaches are promising, they suffer from a fundamental issue: since such approaches are based on black-box machine learning, their real-world applicability is limited, because these policies cannot be analyzed, nor tested, and thus they are not trustable. In this work, we employ a recently developed hybrid approach, which combines reinforcement learning with evolutionary computation, for the generation of interpretable policies for containing the pandemic. These policies, trained on an existing simulator, aim to reduce the spreading of the pandemic while minimizing the economic losses. Our results show that our approach is able to find solutions that are extremely simple, yet very powerful. In fact, our approach has significantly better performance (in simulated scenarios) than both previous work and government policies.
Interpretable pipelines with evolutionarily optimized modules for RL tasks with visual inputs
Feb 10, 2022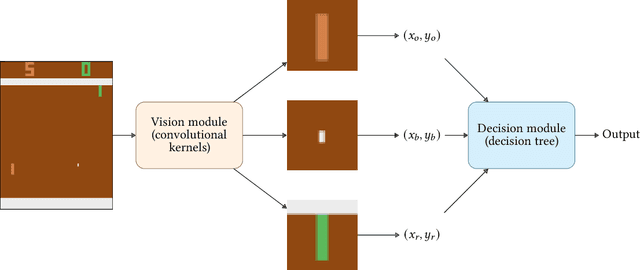

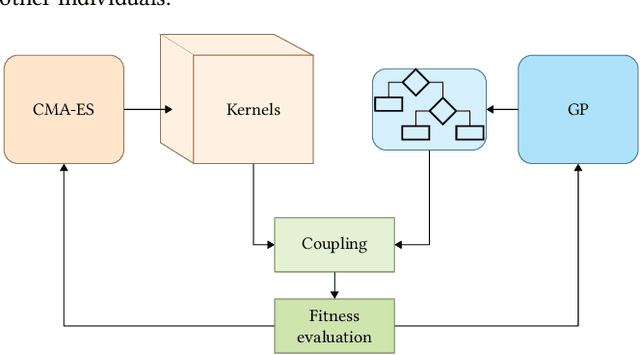

The importance of explainability in AI has become a pressing concern, for which several explainable AI (XAI) approaches have been recently proposed. However, most of the available XAI techniques are post-hoc methods, which however may be only partially reliable, as they do not reflect exactly the state of the original models. Thus, a more direct way for achieving XAI is through interpretable (also called glass-box) models. These models have been shown to obtain comparable (and, in some cases, better) performance with respect to black-boxes models in various tasks such as classification and reinforcement learning. However, they struggle when working with raw data, especially when the input dimensionality increases and the raw inputs alone do not give valuable insights on the decision-making process. Here, we propose to use end-to-end pipelines composed of multiple interpretable models co-optimized by means of evolutionary algorithms, that allows us to decompose the decision-making process into two parts: computing high-level features from raw data, and reasoning on the extracted high-level features. We test our approach in reinforcement learning environments from the Atari benchmark, where we obtain comparable results (with respect to black-box approaches) in settings without stochastic frame-skipping, while performance degrades in frame-skipping settings.
Black-box adversarial attacks using Evolution Strategies
Apr 30, 2021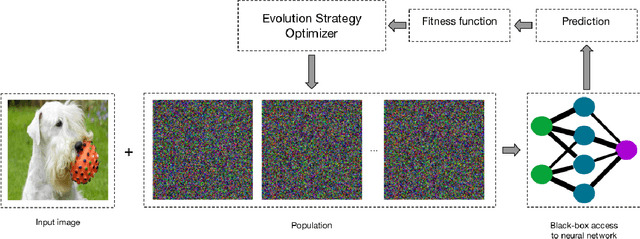



In the last decade, deep neural networks have proven to be very powerful in computer vision tasks, starting a revolution in the computer vision and machine learning fields. However, deep neural networks, usually, are not robust to perturbations of the input data. In fact, several studies showed that slightly changing the content of the images can cause a dramatic decrease in the accuracy of the attacked neural network. Several methods able to generate adversarial samples make use of gradients, which usually are not available to an attacker in real-world scenarios. As opposed to this class of attacks, another class of adversarial attacks, called black-box adversarial attacks, emerged, which does not make use of information on the gradients, being more suitable for real-world attack scenarios. In this work, we compare three well-known evolution strategies on the generation of black-box adversarial attacks for image classification tasks. While our results show that the attacked neural networks can be, in most cases, easily fooled by all the algorithms under comparison, they also show that some black-box optimization algorithms may be better in "harder" setups, both in terms of attack success rate and efficiency (i.e., number of queries).
A Signal-Centric Perspective on the Evolution of Symbolic Communication
Mar 31, 2021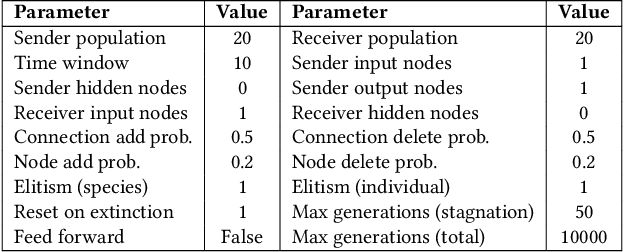
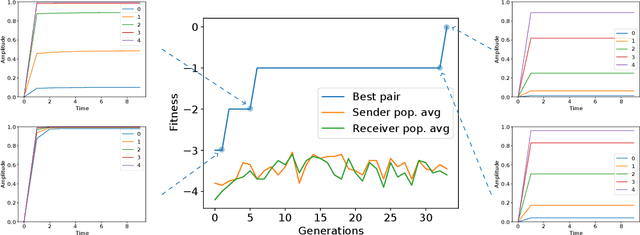
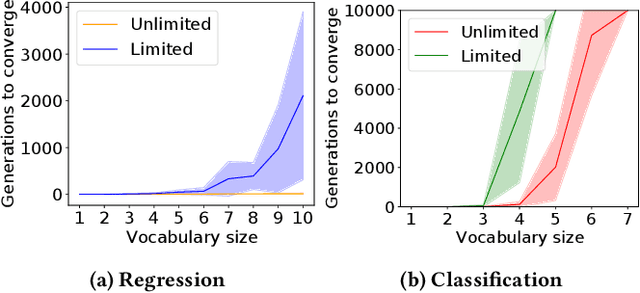
The evolution of symbolic communication is a longstanding open research question in biology. While some theories suggest that it originated from sub-symbolic communication (i.e., iconic or indexical), little experimental evidence exists on how organisms can actually evolve to define a shared set of symbols with unique interpretable meaning, thus being capable of encoding and decoding discrete information. Here, we use a simple synthetic model composed of sender and receiver agents controlled by Continuous-Time Recurrent Neural Networks, which are optimized by means of neuro-evolution. We characterize signal decoding as either regression or classification, with limited and unlimited signal amplitude. First, we show how this choice affects the complexity of the evolutionary search, and leads to different levels of generalization. We then assess the effect of noise, and test the evolved signaling system in a referential game. In various settings, we observe agents evolving to share a dictionary of symbols, with each symbol spontaneously associated to a 1-D unique signal. Finally, we analyze the constellation of signals associated to the evolved signaling systems and note that in most cases these resemble a Pulse Amplitude Modulation system.