 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroth-Order Adaptive Neuron Alignment Based Pruning without Re-Training
Paper and Code
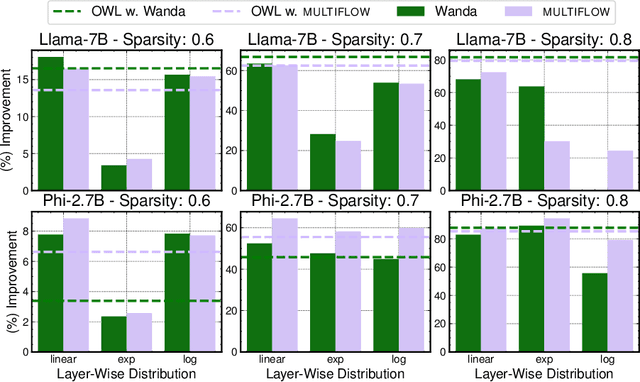
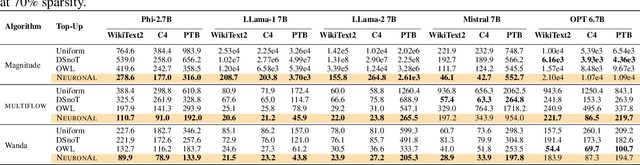
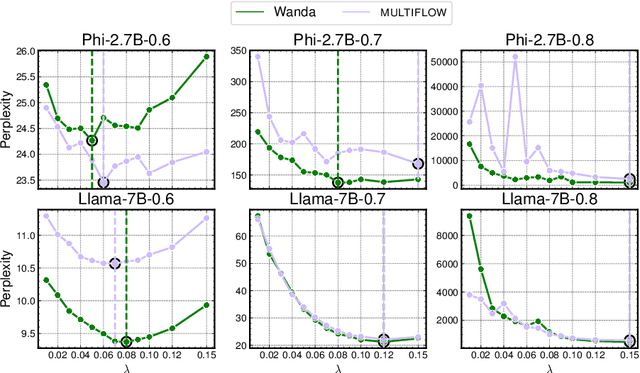
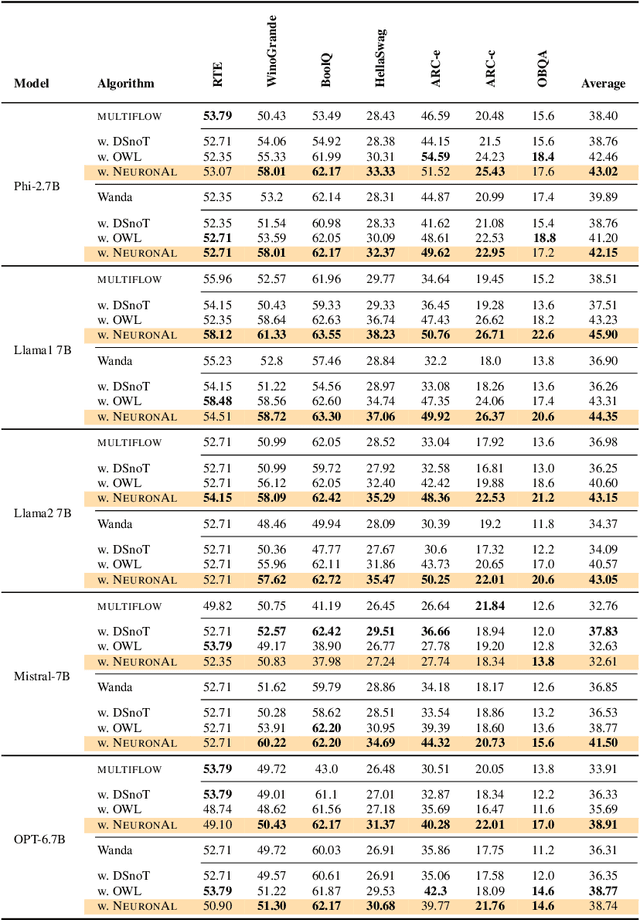
Network pruning is a set of computational techniques that aim to reduce a given model's computational cost by removing a subset of its parameters while having minimal impact on performance. Throughout the last decade, the most widely used pruning paradigm has focused on pruning and re-training, which nowadays is inconvenient due to the vast amount of pre-trained models, which are in any case too expensive to re-train. In this paper, we exploit functional information from dense pre-trained models, i.e., their activations, to obtain sparse models that maximize the activations' alignment w.r.t. their corresponding dense models. Hence, we propose \textsc{NeuroAl}, a \emph{top-up} algorithm that can be used on top of any given pruning algorithm for LLMs, that modifies the block-wise and row-wise sparsity ratios to maximize the \emph{neuron alignment} among activations. Moreover, differently from existing methods, our approach adaptively selects the best parameters for the block-wise and row-wise sparsity ratios w.r.t. to the model and the desired sparsity (given as input), and requires \emph{no re-training}. We test our method on 4 different LLM families and 3 different sparsity ratios, showing how it consistently outperforms the latest state-of-the-art techniques. The code is available at https://github.com/eliacunegatti/NeuroAL.