 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Layers to Submodules: Rethinking Granularity in Replacement-Based LLM Compression
Jun 01, 2026Post-training compression of Large Language Models (LLMs) removes entire architectural components, either deleting them or replacing them with fitted modules. Existing replacement-based methods share two design constraints: full-layer granularity and contiguous selection. We argue that this is overly restrictive: in fact, redundancy in pretrained transformers is not confined to contiguous regions, nor does it evenly distribute between Attention and FeedForward outputs, implying that different strategies best approximate different submodule types and that removable components need not cluster within contiguous depth ranges. Based on this intuition, we introduce SubFit (Submodule-level Fitted residual replacement), which compresses LLMs at the submodule level: Attention and FeedForward submodules are selected non-contiguously, and each receives its own lightweight fitted residual bypass. SubFit operates post-training and requires only calibration data. Across ten LLMs (five base, five instruction-tuned), five sparsity levels from 12.5% to 37.5%, and four replacement-based baselines, SubFit achieves the best aggregate perplexity-accuracy trade-off across the evaluated sparsity levels, with larger gains under aggressive compression. At 25% sparsity, it retains 84.6% of dense downstream accuracy and incurs 2.42x perplexity degradation, against 81.6% and 4.34x for the strongest baselines, while delivering measurable inference speedup and KV-cache savings. Code is available at https://github.com/eliacunegatti/SubFit.
Hallucination as an Anomaly: Dynamic Intervention via Probabilistic Circuits
May 07, 2026One of the most critical challenges in Large Language Models is their tendency to hallucinate, i.e., produce factually incorrect responses. Existing approaches show promising results in terms of hallucination correction, but still suffer from a main limitation: they apply corrections indiscriminately to every token, corrupting also the originally correct generations. To overcome this drawback, we propose PCNET, a Probabilistic Circuit trained as a tractable density estimator over the LLM residual stream. The method detects hallucinations as geometric anomalies on the factual manifold, which is done via exact Negative Log-Likelihood computation, hence without the need for sampling, external verifiers, or weight modifications, as in existing techniques. To demonstrate its effectiveness, we exploit PCNET as a dynamic gate that distinguishes hallucinated from factual hidden states at each decoding step. This triggers our second main contribution, PC-LDCD (Probabilistic Circuit Latent Density Contrastive Decoding), only when the latent geometry deviates from factual regions, while leaving correct generations untouched. Across four LLMs, ranging from 1B to 8B models, and four benchmarks covering conversational reasoning, knowledge-intensive QA, reading comprehension, and truthfulness, PCNET achieves near-perfect hallucination detection across CoQA, SQuAD v2.0, and TriviaQA, with AUROC reaching up to 99%. Moreover, PC-LDCD obtains the highest True+Info, MC2, and MC3 scores on TruthfulQA in three out of four models, in comparison with state-of-the-art baselines, while reducing the mean corruption rate to 53.7% and achieving a preservation rate of 79.3%. Our proposed method is publicly available on GitHub.
Frequency Matters: Fast Model-Agnostic Data Curation for Pruning and Quantization
Mar 17, 2026Post-training model compression is essential for enhancing the portability of Large Language Models (LLMs) while preserving their performance. While several compression approaches have been proposed, less emphasis has been placed on selecting the most suitable set of data (the so-called \emph{calibration data}) for finding the compressed model configuration. The choice of calibration data is a critical step in preserving model capabilities both intra- and inter-tasks. In this work, we address the challenge of identifying high-performance calibration sets for both pruning and quantization by analyzing intrinsic data properties rather than model-specific signals. We introduce \texttt{\textbf{ZipCal}}, a model-agnostic data curation strategy that maximizes lexical diversity based on Zipfian power laws. Experiments demonstrate that our method consistently outperforms standard uniform random sampling across various pruning benchmarks. Notably, it also performs on par, in terms of downstream performance, with a state-of-the-art method that relies on model perplexity. The latter becomes prohibitively expensive at large-scale models and datasets, while \texttt{\textbf{ZipCal}} is on average $\sim$240$\times$ faster due to its tractable linear complexity\footnote{We make the code and the experiments available at https://anonymous.4open.science/r/zipcal-71CD/.}.
2SSP: A Two-Stage Framework for Structured Pruning of LLMs
Jan 29, 2025
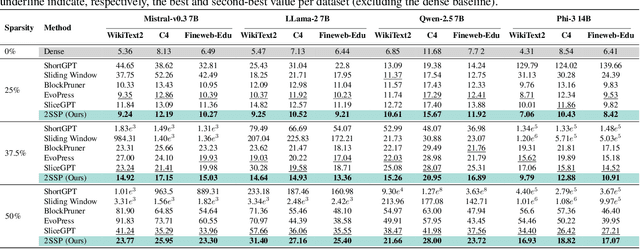
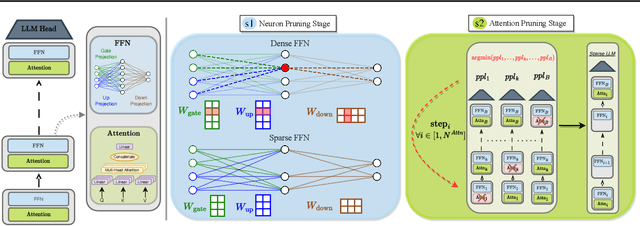
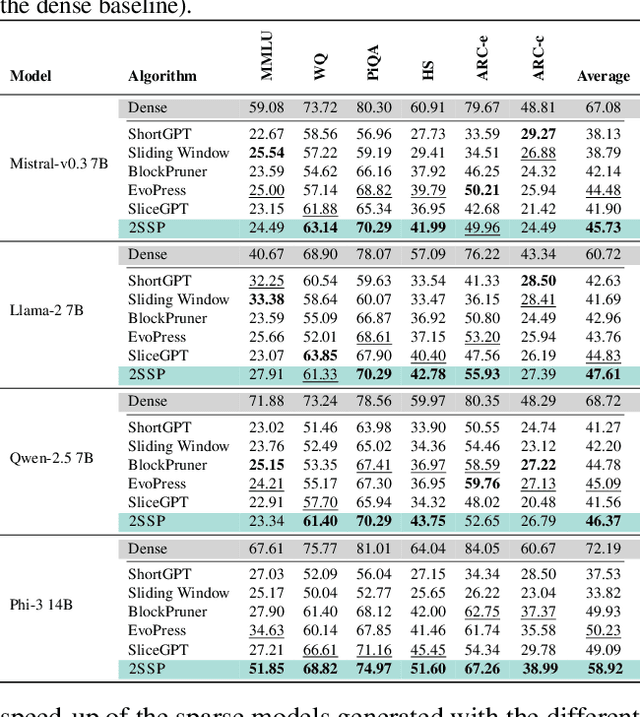
We propose a novel Two-Stage framework for Structured Pruning (2SSP) for pruning Large Language Models (LLMs), which combines two different strategies of pruning, namely Width and Depth Pruning. The first stage (Width Pruning) removes entire neurons, hence their corresponding rows and columns, aiming to preserve the connectivity among the pruned structures in the intermediate state of the Feed-Forward Networks in each Transformer block. This is done based on an importance score measuring the impact of each neuron over the output magnitude. The second stage (Depth Pruning), instead, removes entire Attention submodules. This is done by applying an iterative process that removes the Attention submodules with the minimum impact on a given metric of interest (in our case, perplexity). We also propose a novel mechanism to balance the sparsity rate of the two stages w.r.t. to the desired global sparsity. We test 2SSP on four LLM families and three sparsity rates (25\%, 37.5\%, and 50\%), measuring the resulting perplexity over three language modeling datasets as well as the performance over six downstream tasks. Our method consistently outperforms five state-of-the-art competitors over three language modeling and six downstream tasks, with an up to two-order-of-magnitude gain in terms of pruning time. The code is available at available at \url{https://github.com/FabrizioSandri/2SSP}.
Zeroth-Order Adaptive Neuron Alignment Based Pruning without Re-Training
Nov 11, 2024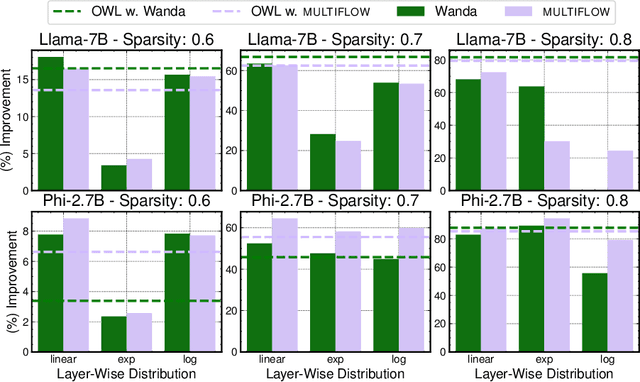
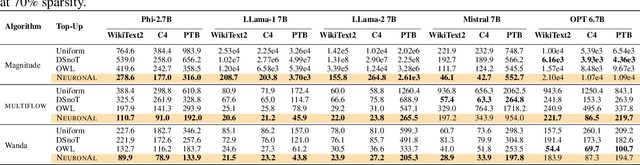
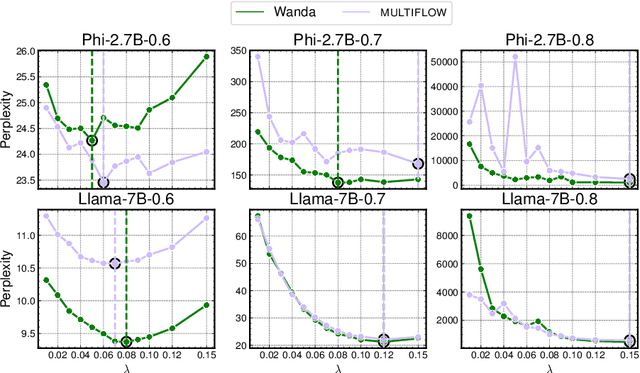
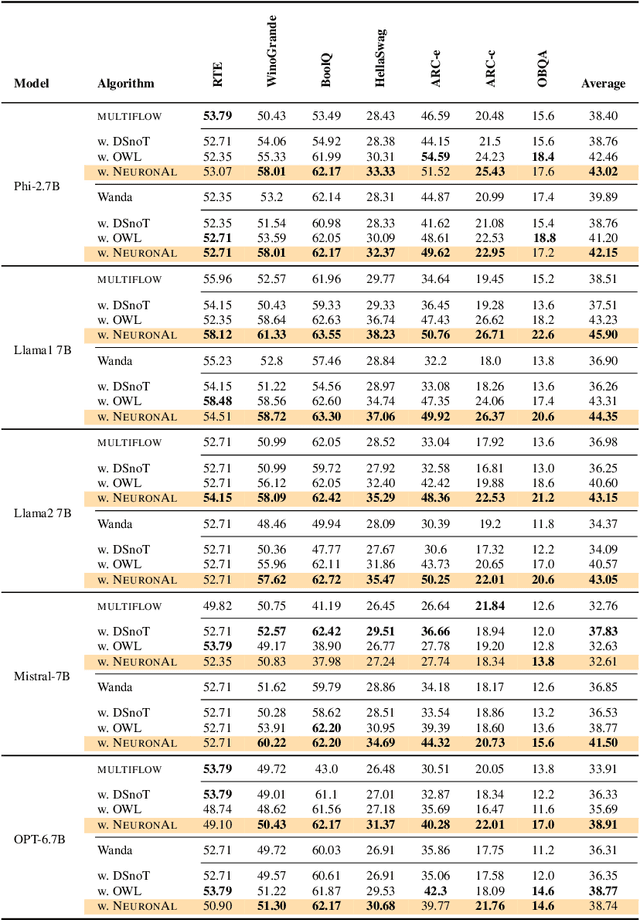
Network pruning is a set of computational techniques that aim to reduce a given model's computational cost by removing a subset of its parameters while having minimal impact on performance. Throughout the last decade, the most widely used pruning paradigm has focused on pruning and re-training, which nowadays is inconvenient due to the vast amount of pre-trained models, which are in any case too expensive to re-train. In this paper, we exploit functional information from dense pre-trained models, i.e., their activations, to obtain sparse models that maximize the activations' alignment w.r.t. their corresponding dense models. Hence, we propose \textsc{NeuroAl}, a \emph{top-up} algorithm that can be used on top of any given pruning algorithm for LLMs, that modifies the block-wise and row-wise sparsity ratios to maximize the \emph{neuron alignment} among activations. Moreover, differently from existing methods, our approach adaptively selects the best parameters for the block-wise and row-wise sparsity ratios w.r.t. to the model and the desired sparsity (given as input), and requires \emph{no re-training}. We test our method on 4 different LLM families and 3 different sparsity ratios, showing how it consistently outperforms the latest state-of-the-art techniques. The code is available at https://github.com/eliacunegatti/NeuroAL.
Influence Maximization in Hypergraphs using Multi-Objective Evolutionary Algorithms
May 16, 2024



The Influence Maximization (IM) problem is a well-known NP-hard combinatorial problem over graphs whose goal is to find the set of nodes in a network that spreads influence at most. Among the various methods for solving the IM problem, evolutionary algorithms (EAs) have been shown to be particularly effective. While the literature on the topic is particularly ample, only a few attempts have been made at solving the IM problem over higher-order networks, namely extensions of standard graphs that can capture interactions that involve more than two nodes. Hypergraphs are a valuable tool for modeling complex interaction networks in various domains; however, they require rethinking of several graph-based problems, including IM. In this work, we propose a multi-objective EA for the IM problem over hypergraphs that leverages smart initialization and hypergraph-aware mutation. While the existing methods rely on greedy or heuristic methods, to our best knowledge this is the first attempt at applying EAs to this problem. Our results over nine real-world datasets and three propagation models, compared with five baseline algorithms, reveal that our method achieves in most cases state-of-the-art results in terms of hypervolume and solution diversity.
MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning
Apr 08, 2024



While excellent in transfer learning, Vision-Language models (VLMs) come with high computational costs due to their large number of parameters. To address this issue, removing parameters via model pruning is a viable solution. However, existing techniques for VLMs are task-specific, and thus require pruning the network from scratch for each new task of interest. In this work, we explore a new direction: Task-Agnostic Vision-Language Pruning (TA-VLP). Given a pretrained VLM, the goal is to find a unique pruned counterpart transferable to multiple unknown downstream tasks. In this challenging setting, the transferable representations already encoded in the pretrained model are a key aspect to preserve. Thus, we propose Multimodal Flow Pruning (MULTIFLOW), a first, gradient-free, pruning framework for TA-VLP where: (i) the importance of a parameter is expressed in terms of its magnitude and its information flow, by incorporating the saliency of the neurons it connects; and (ii) pruning is driven by the emergent (multimodal) distribution of the VLM parameters after pretraining. We benchmark eight state-of-the-art pruning algorithms in the context of TA-VLP, experimenting with two VLMs, three vision-language tasks, and three pruning ratios. Our experimental results show that MULTIFLOW outperforms recent sophisticated, combinatorial competitors in the vast majority of the cases, paving the way towards addressing TA-VLP. The code is publicly available at https://github.com/FarinaMatteo/multiflow.
Many-Objective Evolutionary Influence Maximization: Balancing Spread, Budget, Fairness, and Time
Mar 28, 2024
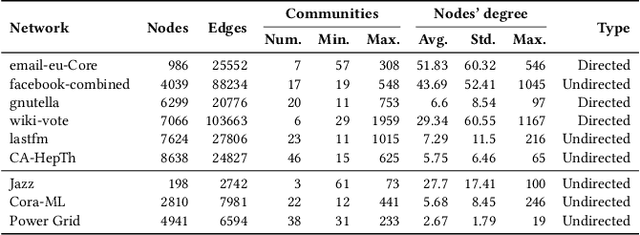
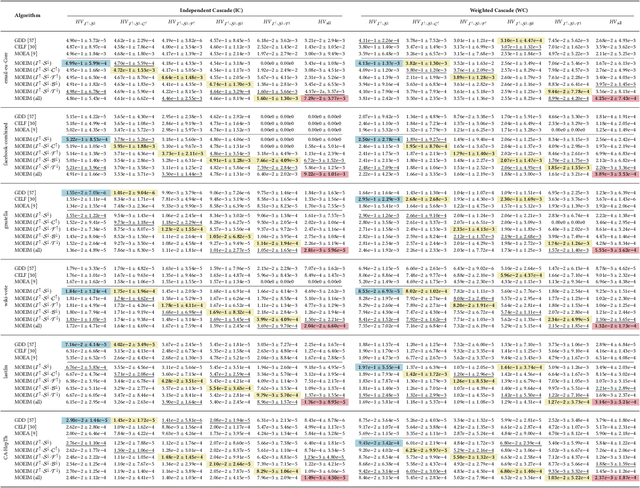
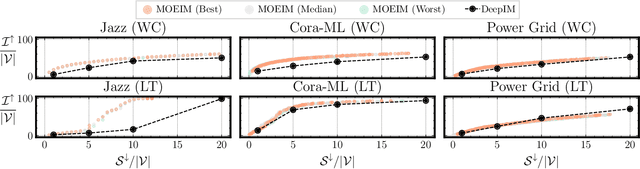
The Influence Maximization (IM) problem seeks to discover the set of nodes in a graph that can spread the information propagation at most. This problem is known to be NP-hard, and it is usually studied by maximizing the influence (spread) and, optionally, optimizing a second objective, such as minimizing the seed set size or maximizing the influence fairness. However, in many practical scenarios multiple aspects of the IM problem must be optimized at the same time. In this work, we propose a first case study where several IM-specific objective functions, namely budget, fairness, communities, and time, are optimized on top of the maximization of influence and minimization of the seed set size. To this aim, we introduce MOEIM (Many-Objective Evolutionary Algorithm for Influence Maximization) a Multi-Objective Evolutionary Algorithm (MOEA) based on NSGA-II incorporating graph-aware operators and a smart initialization. We compare MOEIM in two experimental settings, including a total of nine graph datasets, two heuristic methods, a related MOEA, and a state-of-the-art Deep Learning approach. The experiments show that MOEIM overall outperforms the competitors in most of the tested many-objective settings. To conclude, we also investigate the correlation between the objectives, leading to novel insights into the topic. The codebase is available at https://github.com/eliacunegatti/MOEIM.
Peeking inside Sparse Neural Networks using Multi-Partite Graph Representations
May 26, 2023



Modern Deep Neural Networks (DNNs) have achieved very high performance at the expense of computational resources. To decrease the computational burden, several techniques have proposed to extract, from a given DNN, efficient subnetworks which are able to preserve performance while reducing the number of network parameters. The literature provides a broad set of techniques to discover such subnetworks, but few works have studied the peculiar topologies of such pruned architectures. In this paper, we propose a novel \emph{unrolled input-aware} bipartite Graph Encoding (GE) that is able to generate, for each layer in an either sparse or dense neural network, its corresponding graph representation based on its relation with the input data. We also extend it into a multipartite GE, to capture the relation between layers. Then, we leverage on topological properties to study the difference between the existing pruning algorithms and algorithm categories, as well as the relation between topologies and performance.
Large-scale multi-objective influence maximisation with network downscaling
Apr 14, 2022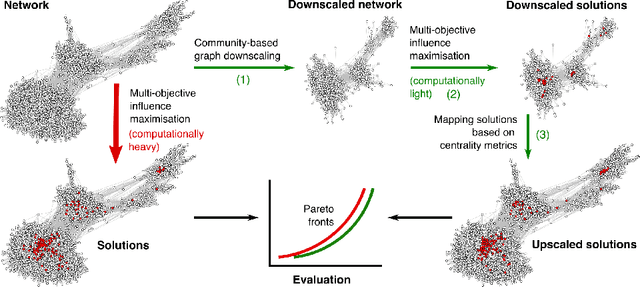

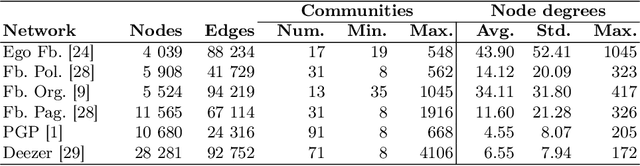
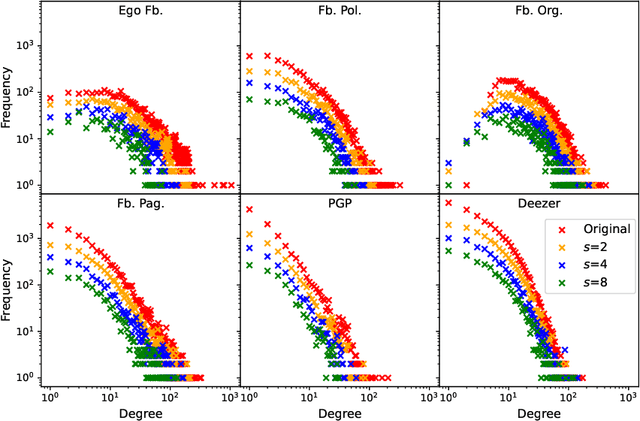
Finding the most influential nodes in a network is a computationally hard problem with several possible applications in various kinds of network-based problems. While several methods have been proposed for tackling the influence maximisation (IM) problem, their runtime typically scales poorly when the network size increases. Here, we propose an original method, based on network downscaling, that allows a multi-objective evolutionary algorithm (MOEA) to solve the IM problem on a reduced scale network, while preserving the relevant properties of the original network. The downscaled solution is then upscaled to the original network, using a mechanism based on centrality metrics such as PageRank. Our results on eight large networks (including two with $\sim$50k nodes) demonstrate the effectiveness of the proposed method with a more than 10-fold runtime gain compared to the time needed on the original network, and an up to $82\%$ time reduction compared to CELF.