 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgegFlora: a topology-aware method to discover functional co-response groups in soil microbial communities
Jul 04, 2024



We aim to learn the functional co-response group: a group of taxa whose co-response effect (the representative characteristic of the group) associates well statistically with a functional variable. Different from the state-of-the-art method, we model the soil microbial community as an ecological co-occurrence network with the taxa as nodes (weighted by their abundance) and their relationships (a combination from both spatial and functional ecological aspects) as edges (weighted by the strength of the relationships). Then, we design a method called gFlora which notably uses graph convolution over this co-occurrence network to get the co-response effect of the group, such that the network topology is also considered in the discovery process. We evaluate gFlora on two real-world soil microbiome datasets (bacteria and nematodes) and compare it with the state-of-the-art method. gFlora outperforms this on all evaluation metrics, and discovers new functional evidence for taxa which were so far under-studied. We show that the graph convolution step is crucial to taxa with low abundance, and the discovered bacteria of different genera are distributed in the co-occurrence network but still tightly connected among themselves, demonstrating that topologically they fill different but collaborative functional roles in the ecological community.
Learning the mechanisms of network growth
Mar 31, 2024We propose a novel model-selection method for dynamic real-life networks. Our approach involves training a classifier on a large body of synthetic network data. The data is generated by simulating nine state-of-the-art random graph models for dynamic networks, with parameter range chosen to ensure exponential growth of the network size in time. We design a conceptually novel type of dynamic features that count new links received by a group of vertices in a particular time interval. The proposed features are easy to compute, analytically tractable, and interpretable. Our approach achieves a near-perfect classification of synthetic networks, exceeding the state-of-the-art by a large margin. Applying our classification method to real-world citation networks gives credibility to the claims in the literature that models with preferential attachment, fitness and aging fit real-world citation networks best, although sometimes, the predicted model does not involve vertex fitness.
Peeking inside Sparse Neural Networks using Multi-Partite Graph Representations
May 26, 2023



Modern Deep Neural Networks (DNNs) have achieved very high performance at the expense of computational resources. To decrease the computational burden, several techniques have proposed to extract, from a given DNN, efficient subnetworks which are able to preserve performance while reducing the number of network parameters. The literature provides a broad set of techniques to discover such subnetworks, but few works have studied the peculiar topologies of such pruned architectures. In this paper, we propose a novel \emph{unrolled input-aware} bipartite Graph Encoding (GE) that is able to generate, for each layer in an either sparse or dense neural network, its corresponding graph representation based on its relation with the input data. We also extend it into a multipartite GE, to capture the relation between layers. Then, we leverage on topological properties to study the difference between the existing pruning algorithms and algorithm categories, as well as the relation between topologies and performance.
Large-scale multi-objective influence maximisation with network downscaling
Apr 14, 2022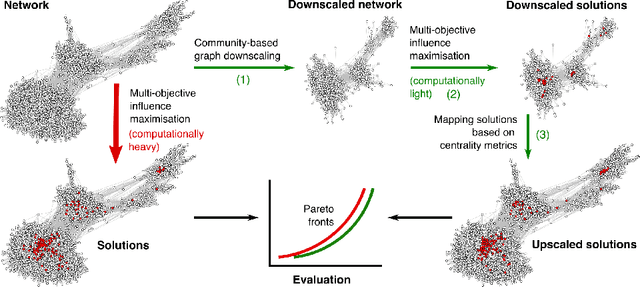

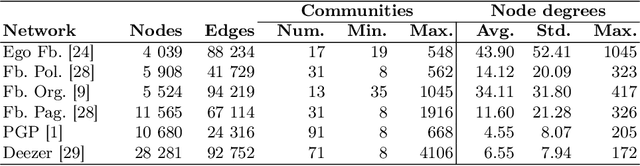
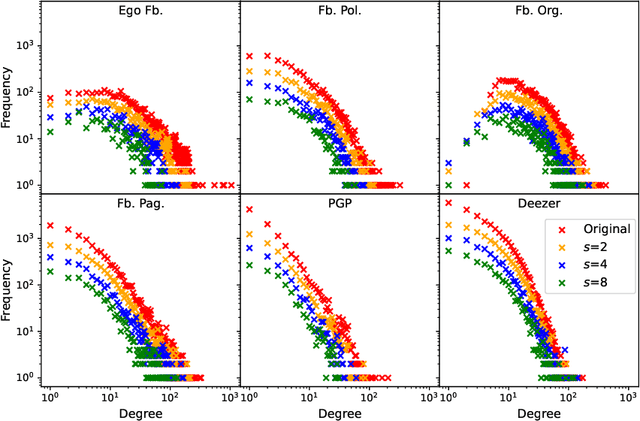
Finding the most influential nodes in a network is a computationally hard problem with several possible applications in various kinds of network-based problems. While several methods have been proposed for tackling the influence maximisation (IM) problem, their runtime typically scales poorly when the network size increases. Here, we propose an original method, based on network downscaling, that allows a multi-objective evolutionary algorithm (MOEA) to solve the IM problem on a reduced scale network, while preserving the relevant properties of the original network. The downscaled solution is then upscaled to the original network, using a mechanism based on centrality metrics such as PageRank. Our results on eight large networks (including two with $\sim$50k nodes) demonstrate the effectiveness of the proposed method with a more than 10-fold runtime gain compared to the time needed on the original network, and an up to $82\%$ time reduction compared to CELF.
Automated fault tree learning from continuous-valued sensor data: a case study on domestic heaters
Mar 13, 2022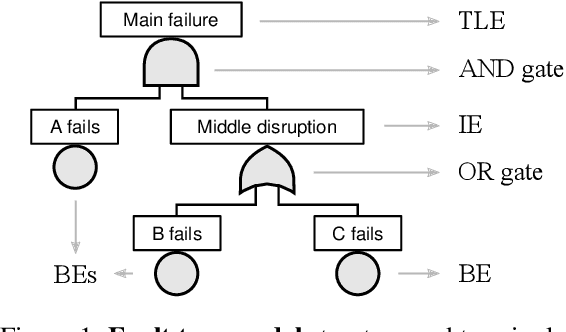
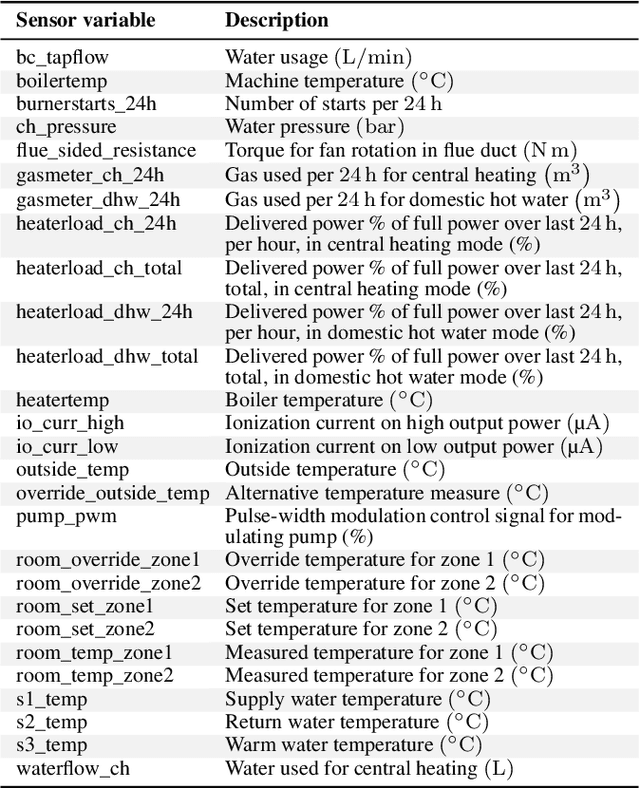
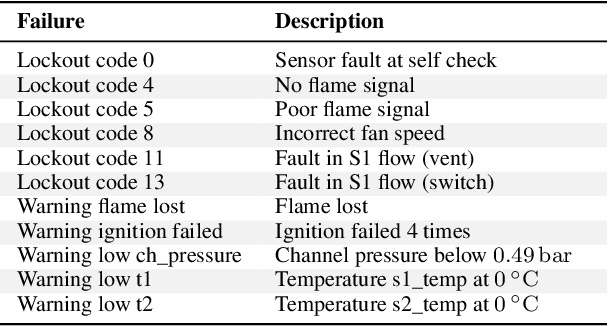
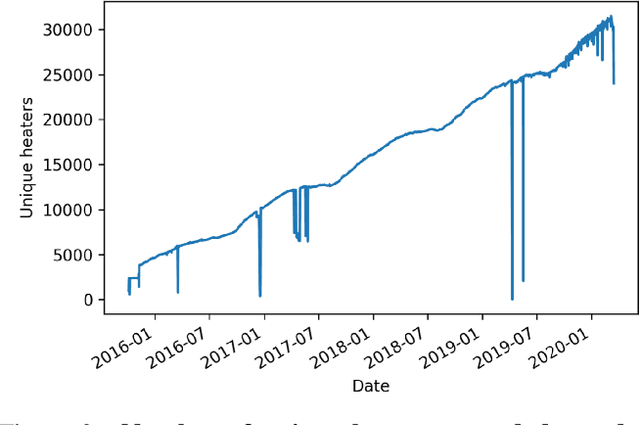
Many industrial sectors have been collecting big sensor data. With recent technologies for processing big data, companies can exploit this for automatic failure detection and prevention. We propose the first completely automated method for failure analysis, machine-learning fault trees from raw observational data with continuous variables. Our method scales well and is tested on a real-world, five-year dataset of domestic heater operations in The Netherlands, with 31 million unique heater-day readings, each containing 27 sensor and 11 failure variables. Our method builds on two previous procedures: the C4.5 decision-tree learning algorithm, and the LIFT fault tree learning algorithm from Boolean data. C4.5 pre-processes each continuous variable: it learns an optimal numerical threshold which distinguishes between faulty and normal operation of the top-level system. These thresholds discretise the variables, thus allowing LIFT to learn fault trees which model the root failure mechanisms of the system and are explainable. We obtain fault trees for the 11 failure variables, and evaluate them in two ways: quantitatively, with a significance score, and qualitatively, with domain specialists. Some of the fault trees learnt have almost maximum significance (above 0.95), while others have medium-to-low significance (around 0.30), reflecting the difficulty of learning from big, noisy, real-world sensor data. The domain specialists confirm that the fault trees model meaningful relationships among the variables.
Bias in Automated Image Colorization: Metrics and Error Types
Feb 16, 2022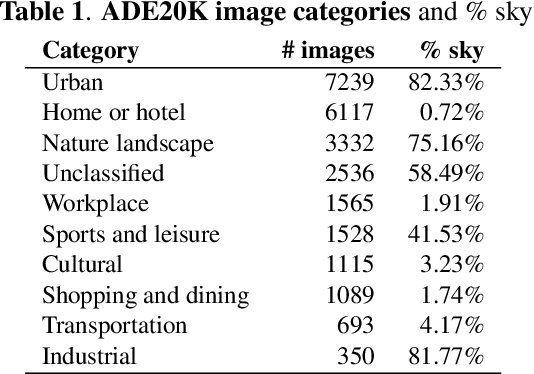
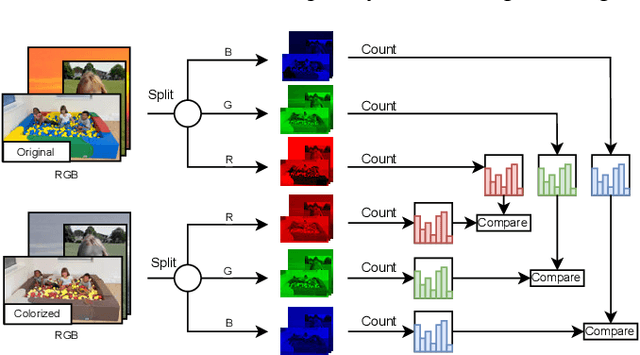
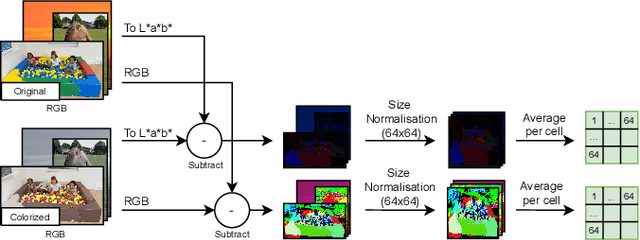
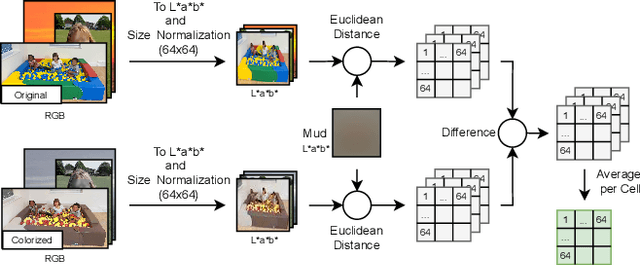
We measure the color shifts present in colorized images from the ADE20K dataset, when colorized by the automatic GAN-based DeOldify model. We introduce fine-grained local and regional bias measurements between the original and the colorized images, and observe many colorization effects. We confirm a general desaturation effect, and also provide novel observations: a shift towards the training average, a pervasive blue shift, different color shifts among image categories, and a manual categorization of colorization errors in three classes.
Prediction of new outlinks for focused Web crawling
Nov 10, 2021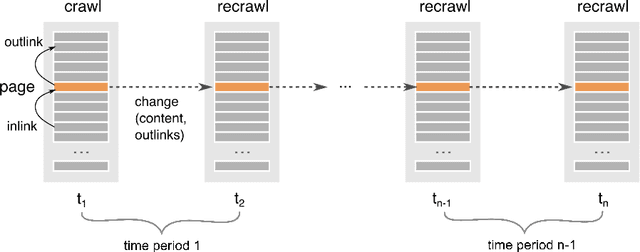
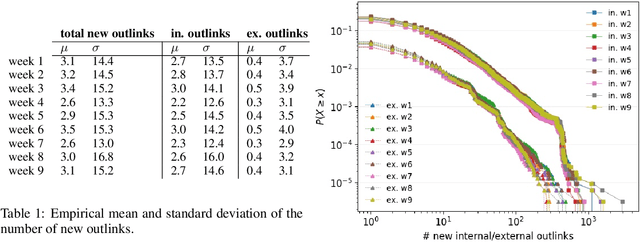

Discovering new hyperlinks enables Web crawlers to find new pages that have not yet been indexed. This is especially important for focused crawlers because they strive to provide a comprehensive analysis of specific parts of the Web, thus prioritizing discovery of new pages over discovery of changes in content. In the literature, changes in hyperlinks and content have been usually considered simultaneously. However, there is also evidence suggesting that these two types of changes are not necessarily related. Moreover, many studies about predicting changes assume that long history of a page is available, which is unattainable in practice. The aim of this work is to provide a methodology for detecting new links effectively using a short history. To this end, we use a dataset of ten crawls at intervals of one week. Our study consists of three parts. First, we obtain insight in the data by analyzing empirical properties of the number of new outlinks. We observe that these properties are, on average, stable over time, but there is a large difference between emergence of hyperlinks towards pages within and outside the domain of a target page (internal and external outlinks, respectively). Next, we provide statistical models for three targets: the link change rate, the presence of new links, and the number of new links. These models include the features used earlier in the literature, as well as new features introduced in this work. We analyze correlation between the features, and investigate their informativeness. A notable finding is that, if the history of the target page is not available, then our new features, that represent the history of related pages, are most predictive for new links in the target page. Finally, we propose ranking methods as guidelines for focused crawlers to efficiently discover new pages, which achieve excellent performance with respect to the corresponding targets.
The network signature of constellation line figures
Oct 19, 2021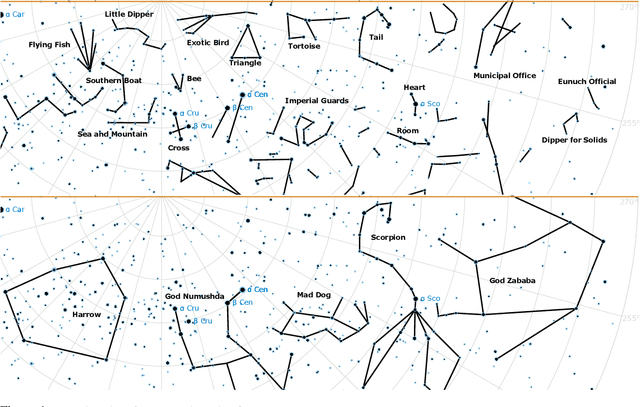
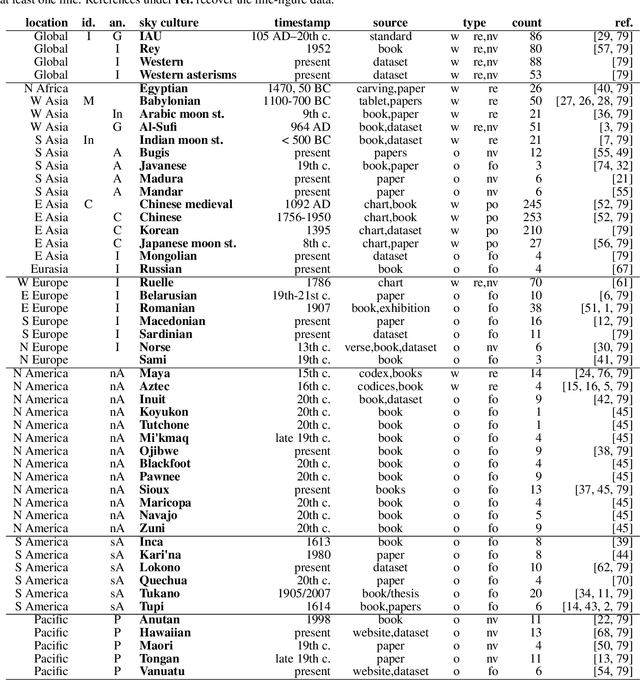
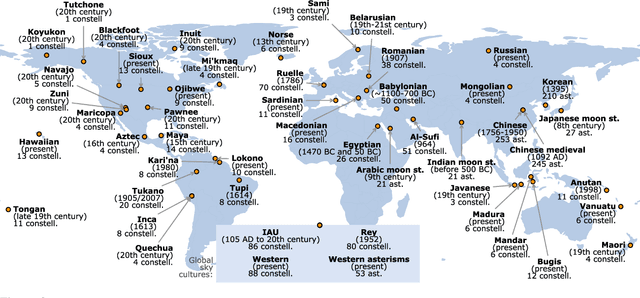

In traditional astronomies across the world, groups of stars in the night sky were linked into constellations -- symbolic representations on the celestial sphere, rich in meaning and with practical roles. In cultures where line or connect-the-dot figures were documented, these visual representations are constrained to the fixed background of stars, but are free in their choice of stars and lines to draw. Over a dataset of 1591 constellation line figures from 50 astronomical cultures, we define metrics to measure the visual signature (or complexity) of a constellation, and answer two questions: (1) does the type of culture associate with the visual signature of constellations? 2) does the sky region associate with the visual signature of constellations? We find that (1) individual cultures are only rarely and weakly thus associated, but the type of culture (by practical use, level of development, and ancestry) show an association. We find clear clusters of cross-culture and cross-type similarity in visual signatures, with SE Asian traditions far apart from Mesopotamian, N and S American, Austronesian and Polynesian traditions, which are similar. We also find (2) more diversity of constellation signature per sky region than expected, with diverse designs around the majority of popular stars.
Independent Prototype Propagation for Zero-Shot Compositionality
Jun 12, 2021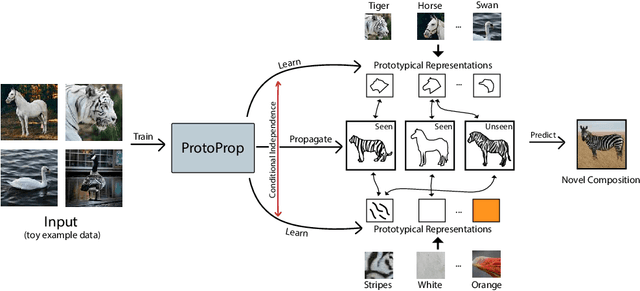
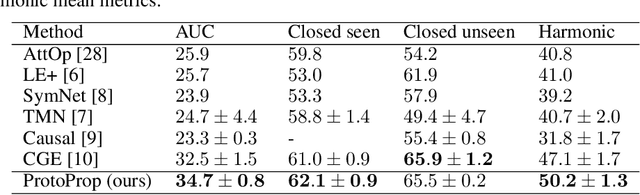
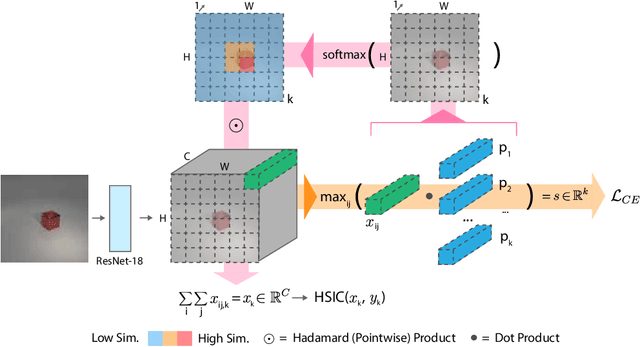

Humans are good at compositional zero-shot reasoning; someone who has never seen a zebra before could nevertheless recognize one when we tell them it looks like a horse with black and white stripes. Machine learning systems, on the other hand, usually leverage spurious correlations in the training data, and while such correlations can help recognize objects in context, they hurt generalization. To be able to deal with underspecified datasets while still leveraging contextual clues during classification, we propose ProtoProp, a novel prototype propagation graph method. First we learn prototypical representations of objects (e.g., zebra) that are conditionally independent w.r.t. their attribute labels (e.g., stripes) and vice versa. Next we propagate the independent prototypes through a compositional graph, to learn compositional prototypes of novel attribute-object combinations that reflect the dependencies of the target distribution. The method does not rely on any external data, such as class hierarchy graphs or pretrained word embeddings. We evaluate our approach on AO-Clever, a synthetic and strongly visual dataset with clean labels, and UT-Zappos, a noisy real-world dataset of fine-grained shoe types. We show that in the generalized compositional zero-shot setting we outperform state-of-the-art results, and through ablations we show the importance of each part of the method and their contribution to the final results.
Top influencers can be identified universally by combining classical centralities
Jun 13, 2020



Information flow, opinion, and epidemics spread over structured networks. When using individual node centrality indicators to predict which nodes will be among the top influencers or spreaders in a large network, no single centrality has consistently good predictive power across a set of 60 finite, diverse, static real-world topologies from six categories of social networks. We show that multi-centrality statistical classifiers, trained on a sample of the nodes from each network, are instead consistently predictive across diverse network cases. Certain pairs of centralities cooperate particularly well in statistically drawing the class boundary between the top spreaders and the rest: local centralities measuring the size of a node's neighbourhood combine well with global centralities such as the eigenvector centrality, closeness, or the core number. As a result, training classifiers with seven classical centralities leads to a nearly maximum average precision function (0.995).