 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Fault Trees Formalized
Mar 13, 2024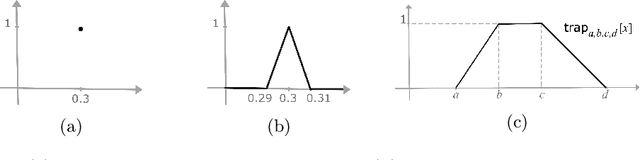
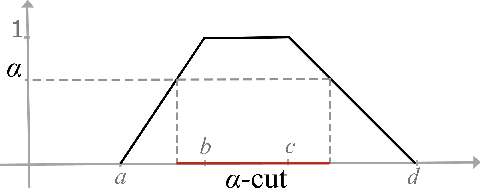
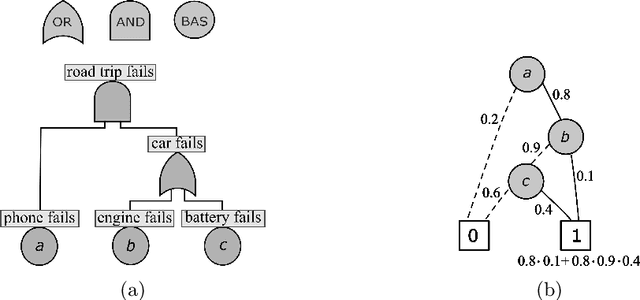

Fault tree analysis is a vital method of assessing safety risks. It helps to identify potential causes of accidents, assess their likelihood and severity, and suggest preventive measures. Quantitative analysis of fault trees is often done via the dependability metrics that compute the system's failure behaviour over time. However, the lack of precise data is a major obstacle to quantitative analysis, and so to reliability analysis. Fuzzy logic is a popular framework for dealing with ambiguous values and has applications in many domains. A number of fuzzy approaches have been proposed to fault tree analysis, but -- to the best of our knowledge -- none of them provide rigorous definitions or algorithms for computing fuzzy unreliability values. In this paper, we define a rigorous framework for fuzzy unreliability values. In addition, we provide a bottom-up algorithm to efficiently calculate fuzzy reliability for a system. The algorithm incorporates the concept of $\alpha$-cuts method. That is, performing binary algebraic operations on intervals on horizontally discretised $\alpha$-cut representations of fuzzy numbers. The method preserves the nonlinearity of fuzzy unreliability. Finally, we illustrate the results obtained from two case studies.
Prediction of new outlinks for focused Web crawling
Nov 10, 2021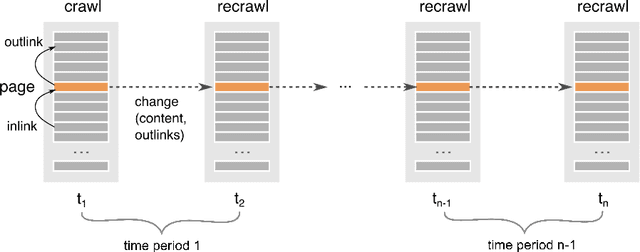
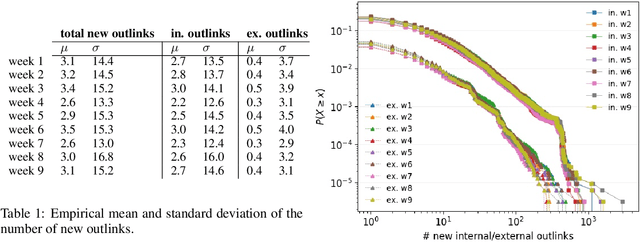
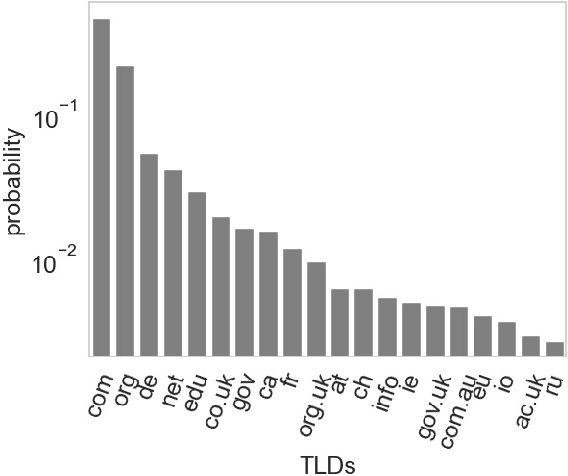

Discovering new hyperlinks enables Web crawlers to find new pages that have not yet been indexed. This is especially important for focused crawlers because they strive to provide a comprehensive analysis of specific parts of the Web, thus prioritizing discovery of new pages over discovery of changes in content. In the literature, changes in hyperlinks and content have been usually considered simultaneously. However, there is also evidence suggesting that these two types of changes are not necessarily related. Moreover, many studies about predicting changes assume that long history of a page is available, which is unattainable in practice. The aim of this work is to provide a methodology for detecting new links effectively using a short history. To this end, we use a dataset of ten crawls at intervals of one week. Our study consists of three parts. First, we obtain insight in the data by analyzing empirical properties of the number of new outlinks. We observe that these properties are, on average, stable over time, but there is a large difference between emergence of hyperlinks towards pages within and outside the domain of a target page (internal and external outlinks, respectively). Next, we provide statistical models for three targets: the link change rate, the presence of new links, and the number of new links. These models include the features used earlier in the literature, as well as new features introduced in this work. We analyze correlation between the features, and investigate their informativeness. A notable finding is that, if the history of the target page is not available, then our new features, that represent the history of related pages, are most predictive for new links in the target page. Finally, we propose ranking methods as guidelines for focused crawlers to efficiently discover new pages, which achieve excellent performance with respect to the corresponding targets.