 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the mechanisms of network growth
Mar 31, 2024We propose a novel model-selection method for dynamic real-life networks. Our approach involves training a classifier on a large body of synthetic network data. The data is generated by simulating nine state-of-the-art random graph models for dynamic networks, with parameter range chosen to ensure exponential growth of the network size in time. We design a conceptually novel type of dynamic features that count new links received by a group of vertices in a particular time interval. The proposed features are easy to compute, analytically tractable, and interpretable. Our approach achieves a near-perfect classification of synthetic networks, exceeding the state-of-the-art by a large margin. Applying our classification method to real-world citation networks gives credibility to the claims in the literature that models with preferential attachment, fitness and aging fit real-world citation networks best, although sometimes, the predicted model does not involve vertex fitness.
Fairness Rising from the Ranks: HITS and PageRank on Homophilic Networks
Mar 08, 2024In this paper, we investigate the conditions under which link analysis algorithms prevent minority groups from reaching high ranking slots. We find that the most common link-based algorithms using centrality metrics, such as PageRank and HITS, can reproduce and even amplify bias against minority groups in networks. Yet, their behavior differs: one one hand, we empirically show that PageRank mirrors the degree distribution for most of the ranking positions and it can equalize representation of minorities among the top ranked nodes; on the other hand, we find that HITS amplifies pre-existing bias in homophilic networks through a novel theoretical analysis, supported by empirical results. We find the root cause of bias amplification in HITS to be the level of homophily present in the network, modeled through an evolving network model with two communities. We illustrate our theoretical analysis on both synthetic and real datasets and we present directions for future work.
Prediction of new outlinks for focused Web crawling
Nov 10, 2021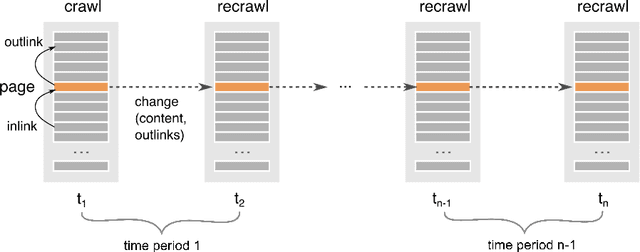
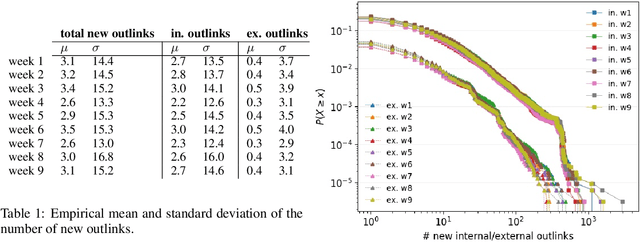
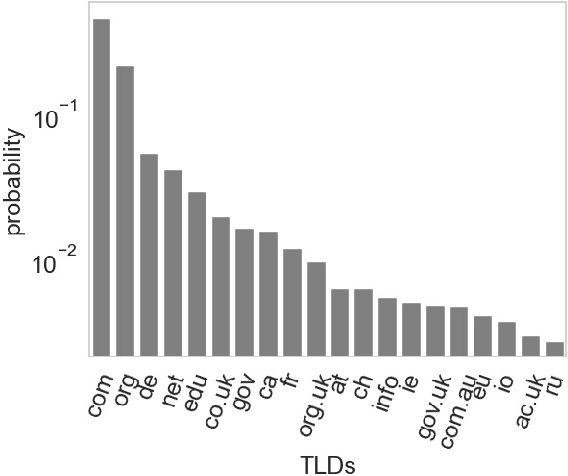

Discovering new hyperlinks enables Web crawlers to find new pages that have not yet been indexed. This is especially important for focused crawlers because they strive to provide a comprehensive analysis of specific parts of the Web, thus prioritizing discovery of new pages over discovery of changes in content. In the literature, changes in hyperlinks and content have been usually considered simultaneously. However, there is also evidence suggesting that these two types of changes are not necessarily related. Moreover, many studies about predicting changes assume that long history of a page is available, which is unattainable in practice. The aim of this work is to provide a methodology for detecting new links effectively using a short history. To this end, we use a dataset of ten crawls at intervals of one week. Our study consists of three parts. First, we obtain insight in the data by analyzing empirical properties of the number of new outlinks. We observe that these properties are, on average, stable over time, but there is a large difference between emergence of hyperlinks towards pages within and outside the domain of a target page (internal and external outlinks, respectively). Next, we provide statistical models for three targets: the link change rate, the presence of new links, and the number of new links. These models include the features used earlier in the literature, as well as new features introduced in this work. We analyze correlation between the features, and investigate their informativeness. A notable finding is that, if the history of the target page is not available, then our new features, that represent the history of related pages, are most predictive for new links in the target page. Finally, we propose ranking methods as guidelines for focused crawlers to efficiently discover new pages, which achieve excellent performance with respect to the corresponding targets.
The Hyperspherical Geometry of Community Detection: Modularity as a Distance
Jul 06, 2021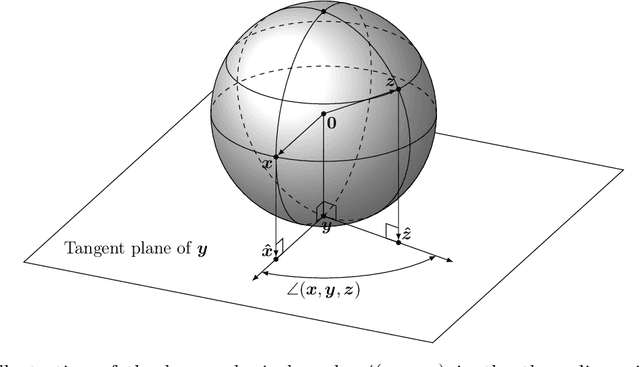
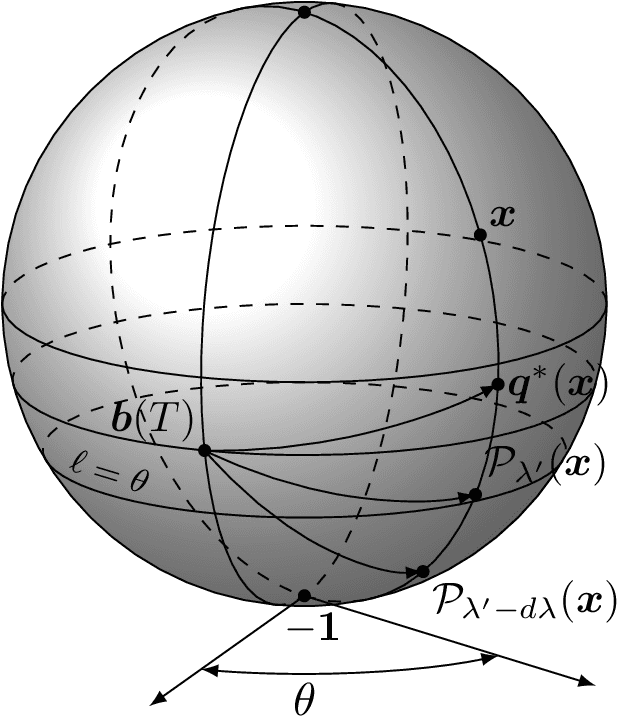
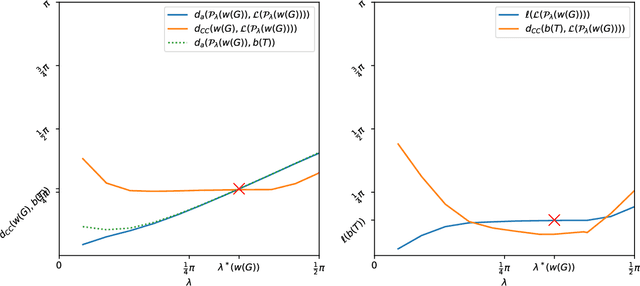
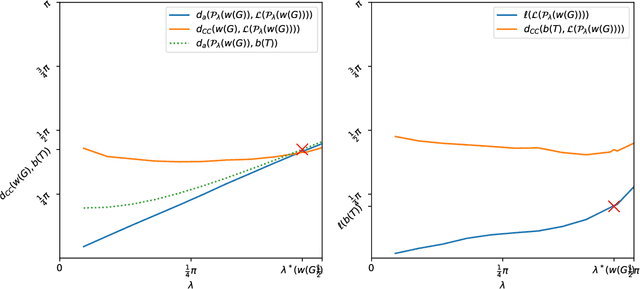
The Louvain algorithm is currently one of the most popular community detection methods. This algorithm finds communities by maximizing a quantity called modularity. In this work, we describe a metric space of clusterings, where clusterings are described by a binary vector indexed by the vertex-pairs. We extend this geometry to a hypersphere and prove that maximizing modularity is equivalent to minimizing the angular distance to some modularity vector over the set of clustering vectors. This equivalence allows us to view the Louvain algorithm as a nearest-neighbor search that approximately minimizes the distance to this modularity vector. By replacing this modularity vector by a different vector, many alternative community detection methods can be obtained. We explore this wider class and compare it to existing modularity-based methods. Our experiments show that these alternatives may outperform modularity-based methods. For example, when communities are large compared to vertex neighborhoods, a vector based on numbers of common neighbors outperforms existing community detection methods. While the focus of the present work is community detection in networks, the proposed methodology can be applied to any clustering problem where pair-wise similarity data is available.
Automated Lane Detection in Crowds using Proximity Graphs
Jul 06, 2017
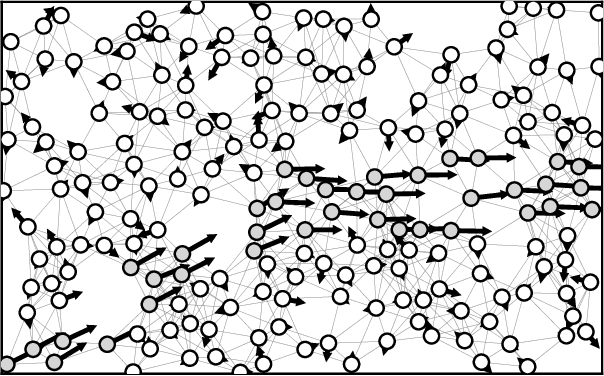
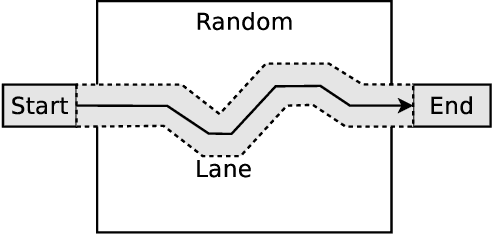
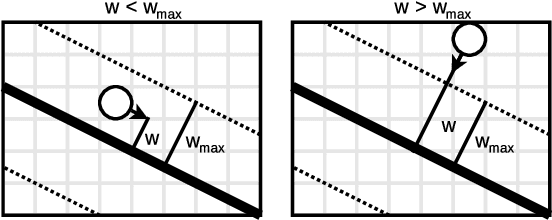
Studying the behavior of crowds is vital for understanding and predicting human interactions in public areas. Research has shown that, under certain conditions, large groups of people can form collective behavior patterns: local interactions between individuals results in global movements patterns. To detect these patterns in a crowd, we assume each person is carrying an on-body device that acts a local proximity sensor, e.g., smartphone or bluetooth badge, and represent the texture of the crowd as a proximity graph. Our goal is extract information about crowds from these proximity graphs. In this work, we focus on one particular type of pattern: lane formation. We present a formal definition of a lane, proposed a simple probabilistic model that simulates lanes moving through a stationary crowd, and present an automated lane-detection method. Our preliminary results show that our method is able to detect lanes of different shapes and sizes. We see our work as an initial step towards rich pattern recognition using proximity graphs.