 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Inference On Foundation Models For Remote Sensing Text-to-image Retrieval With Complex Queries
Dec 16, 2025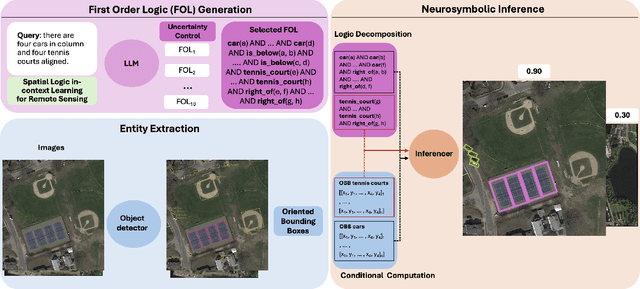
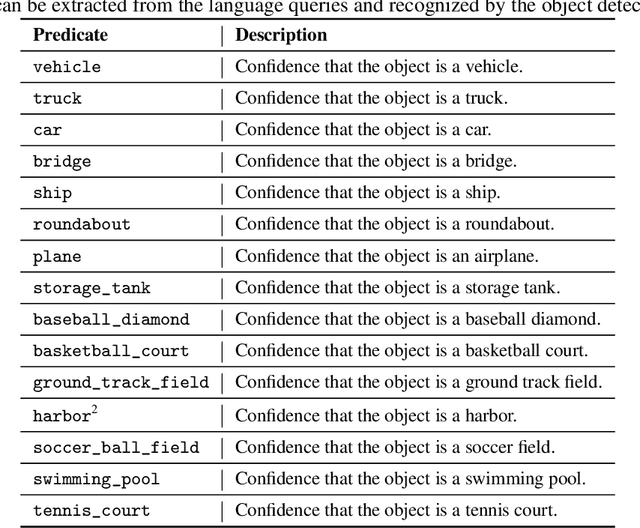

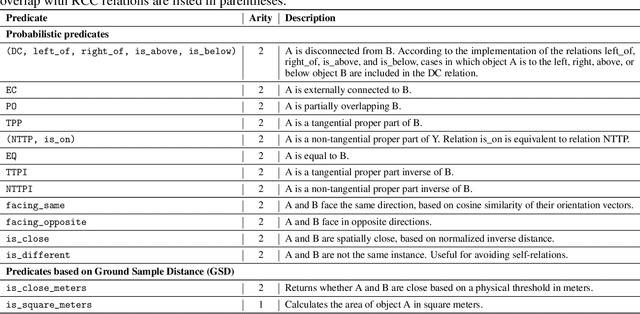
Text-to-image retrieval in remote sensing (RS) has advanced rapidly with the rise of large vision-language models (LVLMs) tailored for aerial and satellite imagery, culminating in remote sensing large vision-language models (RS-LVLMS). However, limited explainability and poor handling of complex spatial relations remain key challenges for real-world use. To address these issues, we introduce RUNE (Reasoning Using Neurosymbolic Entities), an approach that combines Large Language Models (LLMs) with neurosymbolic AI to retrieve images by reasoning over the compatibility between detected entities and First-Order Logic (FOL) expressions derived from text queries. Unlike RS-LVLMs that rely on implicit joint embeddings, RUNE performs explicit reasoning, enhancing performance and interpretability. For scalability, we propose a logic decomposition strategy that operates on conditioned subsets of detected entities, guaranteeing shorter execution time compared to neural approaches. Rather than using foundation models for end-to-end retrieval, we leverage them only to generate FOL expressions, delegating reasoning to a neurosymbolic inference module. For evaluation we repurpose the DOTA dataset, originally designed for object detection, by augmenting it with more complex queries than in existing benchmarks. We show the LLM's effectiveness in text-to-logic translation and compare RUNE with state-of-the-art RS-LVLMs, demonstrating superior performance. We introduce two metrics, Retrieval Robustness to Query Complexity (RRQC) and Retrieval Robustness to Image Uncertainty (RRIU), which evaluate performance relative to query complexity and image uncertainty. RUNE outperforms joint-embedding models in complex RS retrieval tasks, offering gains in performance, robustness, and explainability. We show RUNE's potential for real-world RS applications through a use case on post-flood satellite image retrieval.
Occlusion Robustness of CLIP for Military Vehicle Classification
Aug 28, 2025Vision-language models (VLMs) like CLIP enable zero-shot classification by aligning images and text in a shared embedding space, offering advantages for defense applications with scarce labeled data. However, CLIP's robustness in challenging military environments, with partial occlusion and degraded signal-to-noise ratio (SNR), remains underexplored. We investigate CLIP variants' robustness to occlusion using a custom dataset of 18 military vehicle classes and evaluate using Normalized Area Under the Curve (NAUC) across occlusion percentages. Four key insights emerge: (1) Transformer-based CLIP models consistently outperform CNNs, (2) fine-grained, dispersed occlusions degrade performance more than larger contiguous occlusions, (3) despite improved accuracy, performance of linear-probed models sharply drops at around 35% occlusion, (4) by finetuning the model's backbone, this performance drop occurs at more than 60% occlusion. These results underscore the importance of occlusion-specific augmentations during training and the need for further exploration into patch-level sensitivity and architectural resilience for real-world deployment of CLIP.
Textual Inversion for Efficient Adaptation of Open-Vocabulary Object Detectors Without Forgetting
Aug 07, 2025Recent progress in large pre-trained vision language models (VLMs) has reached state-of-the-art performance on several object detection benchmarks and boasts strong zero-shot capabilities, but for optimal performance on specific targets some form of finetuning is still necessary. While the initial VLM weights allow for great few-shot transfer learning, this usually involves the loss of the original natural language querying and zero-shot capabilities. Inspired by the success of Textual Inversion (TI) in personalizing text-to-image diffusion models, we propose a similar formulation for open-vocabulary object detection. TI allows extending the VLM vocabulary by learning new or improving existing tokens to accurately detect novel or fine-grained objects from as little as three examples. The learned tokens are completely compatible with the original VLM weights while keeping them frozen, retaining the original model's benchmark performance, and leveraging its existing capabilities such as zero-shot domain transfer (e.g., detecting a sketch of an object after training only on real photos). The storage and gradient calculations are limited to the token embedding dimension, requiring significantly less compute than full-model fine-tuning. We evaluated whether the method matches or outperforms the baseline methods that suffer from forgetting in a wide variety of quantitative and qualitative experiments.
Self-Supervised Partial Cycle-Consistency for Multi-View Matching
Jan 10, 2025



Matching objects across partially overlapping camera views is crucial in multi-camera systems and requires a view-invariant feature extraction network. Training such a network with cycle-consistency circumvents the need for labor-intensive labeling. In this paper, we extend the mathematical formulation of cycle-consistency to handle partial overlap. We then introduce a pseudo-mask which directs the training loss to take partial overlap into account. We additionally present several new cycle variants that complement each other and present a time-divergent scene sampling scheme that improves the data input for this self-supervised setting. Cross-camera matching experiments on the challenging DIVOTrack dataset show the merits of our approach. Compared to the self-supervised state-of-the-art, we achieve a 4.3 percentage point higher F1 score with our combined contributions. Our improvements are robust to reduced overlap in the training data, with substantial improvements in challenging scenes that need to make few matches between many people. Self-supervised feature networks trained with our method are effective at matching objects in a range of multi-camera settings, providing opportunities for complex tasks like large-scale multi-camera scene understanding.
Adaptive Prompt Tuning: Vision Guided Prompt Tuning with Cross-Attention for Fine-Grained Few-Shot Learning
Dec 19, 2024



Few-shot, fine-grained classification in computer vision poses significant challenges due to the need to differentiate subtle class distinctions with limited data. This paper presents a novel method that enhances the Contrastive Language-Image Pre-Training (CLIP) model through adaptive prompt tuning, guided by real-time visual inputs. Unlike existing techniques such as Context Optimization (CoOp) and Visual Prompt Tuning (VPT), which are constrained by static prompts or visual token reliance, the proposed approach leverages a cross-attention mechanism to dynamically refine text prompts for the image at hand. This enables an image-specific alignment of textual features with image patches extracted from the Vision Transformer, making the model more effective for datasets with high intra-class variance and low inter-class differences. The method is evaluated on several datasets, including CUBirds, Oxford Flowers, and FGVC Aircraft, showing significant performance gains over static prompt tuning approaches. To ensure these performance gains translate into trustworthy predictions, we integrate Monte-Carlo Dropout in our approach to improve the reliability of the model predictions and uncertainty estimates. This integration provides valuable insights into the model's predictive confidence, helping to identify when predictions can be trusted and when additional verification is necessary. This dynamic approach offers a robust solution, advancing the state-of-the-art for few-shot fine-grained classification.
Incremental Learning of Affordances using Markov Logic Networks
Oct 23, 2024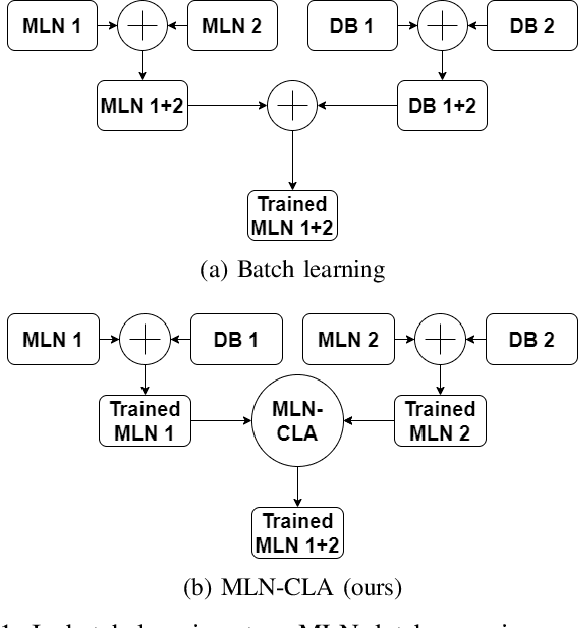
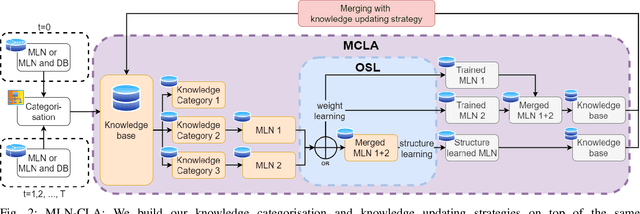
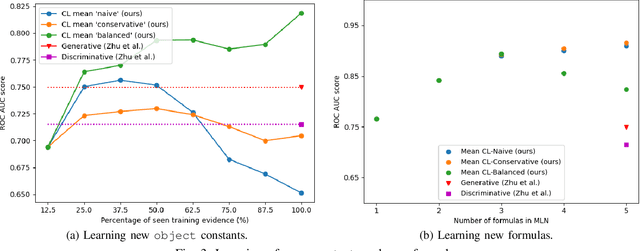
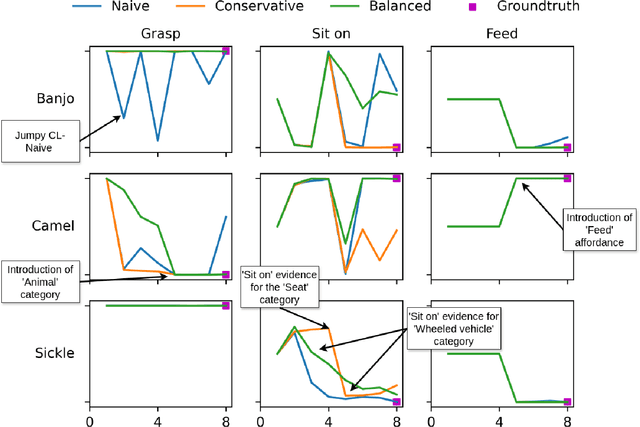
Affordances enable robots to have a semantic understanding of their surroundings. This allows them to have more acting flexibility when completing a given task. Capturing object affordances in a machine learning model is a difficult task, because of their dependence on contextual information. Markov Logic Networks (MLN) combine probabilistic reasoning with logic that is able to capture such context. Mobile robots operate in partially known environments wherein unseen object affordances can be observed. This new information must be incorporated into the existing knowledge, without having to retrain the MLN from scratch. We introduce the MLN Cumulative Learning Algorithm (MLN-CLA). MLN-CLA learns new relations in various knowledge domains by retaining knowledge and only updating the changed knowledge, for which the MLN is retrained. We show that MLN-CLA is effective for accumulative learning and zero-shot affordance inference, outperforming strong baselines.
* accepted at IEEE IRC 2024
Towards Probabilistic Inductive Logic Programming with Neurosymbolic Inference and Relaxation
Aug 21, 2024Many inductive logic programming (ILP) methods are incapable of learning programs from probabilistic background knowledge, e.g. coming from sensory data or neural networks with probabilities. We propose Propper, which handles flawed and probabilistic background knowledge by extending ILP with a combination of neurosymbolic inference, a continuous criterion for hypothesis selection (BCE) and a relaxation of the hypothesis constrainer (NoisyCombo). For relational patterns in noisy images, Propper can learn programs from as few as 8 examples. It outperforms binary ILP and statistical models such as a Graph Neural Network.
* 15 pages
NeCo: Improving DINOv2's spatial representations in 19 GPU hours with Patch Neighbor Consistency
Aug 20, 2024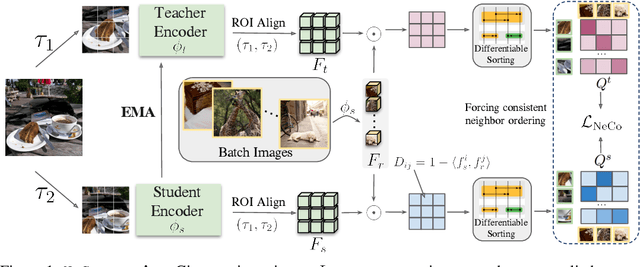
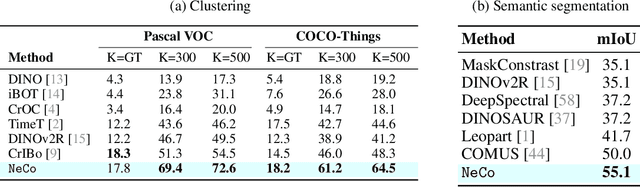
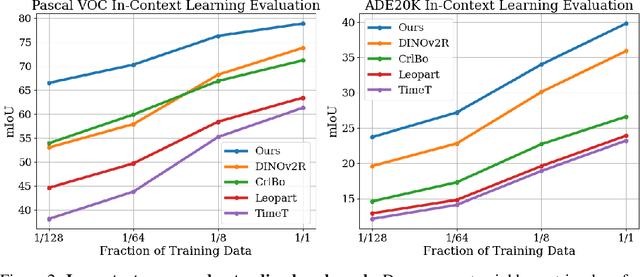
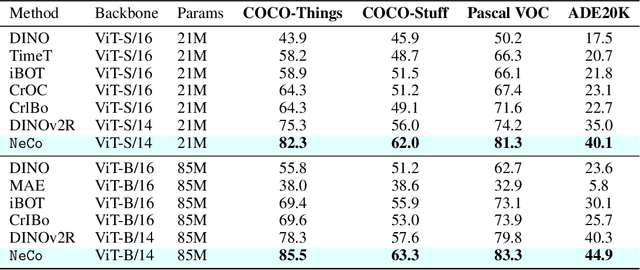
We propose sorting patch representations across views as a novel self-supervised learning signal to improve pretrained representations. To this end, we introduce NeCo: Patch Neighbor Consistency, a novel training loss that enforces patch-level nearest neighbor consistency across a student and teacher model, relative to reference batches. Our method leverages a differentiable sorting method applied on top of pretrained representations, such as DINOv2-registers to bootstrap the learning signal and further improve upon them. This dense post-pretraining leads to superior performance across various models and datasets, despite requiring only 19 hours on a single GPU. We demonstrate that this method generates high-quality dense feature encoders and establish several new state-of-the-art results: +5.5% and + 6% for non-parametric in-context semantic segmentation on ADE20k and Pascal VOC, and +7.2% and +5.7% for linear segmentation evaluations on COCO-Things and -Stuff.
Affordance Perception by a Knowledge-Guided Vision-Language Model with Efficient Error Correction
Jul 18, 2024Mobile robot platforms will increasingly be tasked with activities that involve grasping and manipulating objects in open world environments. Affordance understanding provides a robot with means to realise its goals and execute its tasks, e.g. to achieve autonomous navigation in unknown buildings where it has to find doors and ways to open these. In order to get actionable suggestions, robots need to be able to distinguish subtle differences between objects, as they may result in different action sequences: doorknobs require grasp and twist, while handlebars require grasp and push. In this paper, we improve affordance perception for a robot in an open-world setting. Our contribution is threefold: (1) We provide an affordance representation with precise, actionable affordances; (2) We connect this knowledge base to a foundational vision-language models (VLM) and prompt the VLM for a wider variety of new and unseen objects; (3) We apply a human-in-the-loop for corrections on the output of the VLM. The mix of affordance representation, image detection and a human-in-the-loop is effective for a robot to search for objects to achieve its goals. We have demonstrated this in a scenario of finding various doors and the many different ways to open them.
* 15 pages
Lightweight Uncertainty Quantification with Simplex Semantic Segmentation for Terrain Traversability
Jul 18, 2024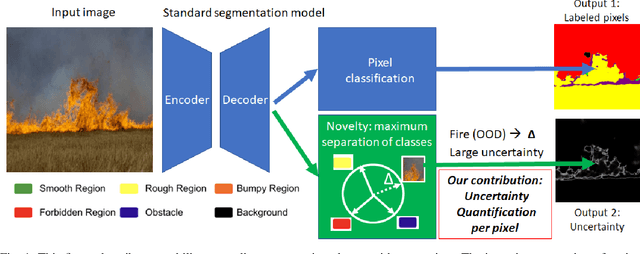
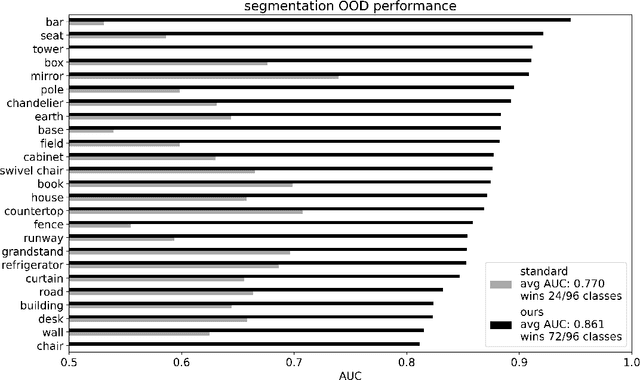

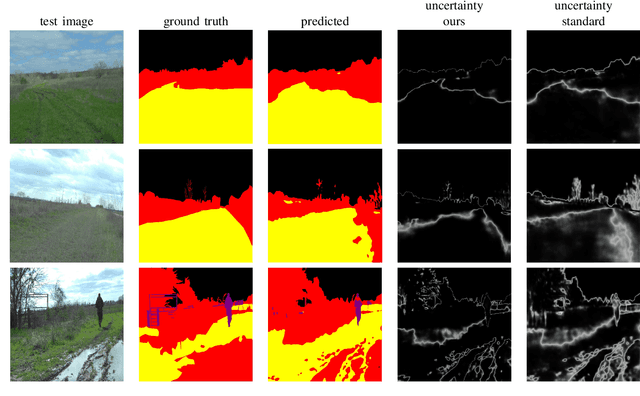
For navigation of robots, image segmentation is an important component to determining a terrain's traversability. For safe and efficient navigation, it is key to assess the uncertainty of the predicted segments. Current uncertainty estimation methods are limited to a specific choice of model architecture, are costly in terms of training time, require large memory for inference (ensembles), or involve complex model architectures (energy-based, hyperbolic, masking). In this paper, we propose a simple, light-weight module that can be connected to any pretrained image segmentation model, regardless of its architecture, with marginal additional computation cost because it reuses the model's backbone. Our module is based on maximum separation of the segmentation classes by respective prototype vectors. This optimizes the probability that out-of-distribution segments are projected in between the prototype vectors. The uncertainty value in the classification label is obtained from the distance to the nearest prototype. We demonstrate the effectiveness of our module for terrain segmentation.
* 10 pages