 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFranca: Nested Matryoshka Clustering for Scalable Visual Representation Learning
Jul 18, 2025We present Franca (pronounced Fran-ka): free one; the first fully open-source (data, code, weights) vision foundation model that matches and in many cases surpasses the performance of state-of-the-art proprietary models, e.g., DINOv2, CLIP, SigLIPv2, etc. Our approach is grounded in a transparent training pipeline inspired by Web-SSL and uses publicly available data: ImageNet-21K and a subset of ReLAION-2B. Beyond model release, we tackle critical limitations in SSL clustering methods. While modern models rely on assigning image features to large codebooks via clustering algorithms like Sinkhorn-Knopp, they fail to account for the inherent ambiguity in clustering semantics. To address this, we introduce a parameter-efficient, multi-head clustering projector based on nested Matryoshka representations. This design progressively refines features into increasingly fine-grained clusters without increasing the model size, enabling both performance and memory efficiency. Additionally, we propose a novel positional disentanglement strategy that explicitly removes positional biases from dense representations, thereby improving the encoding of semantic content. This leads to consistent gains on several downstream benchmarks, demonstrating the utility of cleaner feature spaces. Our contributions establish a new standard for transparent, high-performance vision models and open a path toward more reproducible and generalizable foundation models for the broader AI community. The code and model checkpoints are available at https://github.com/valeoai/Franca.
NeCo: Improving DINOv2's spatial representations in 19 GPU hours with Patch Neighbor Consistency
Aug 20, 2024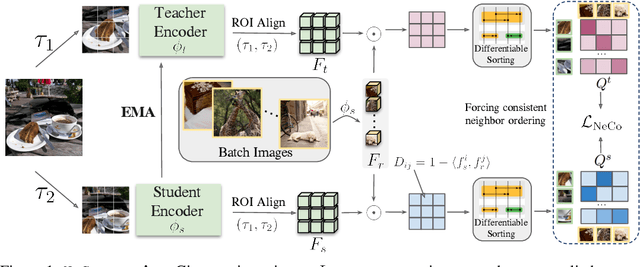
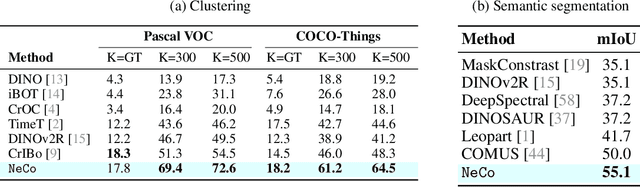
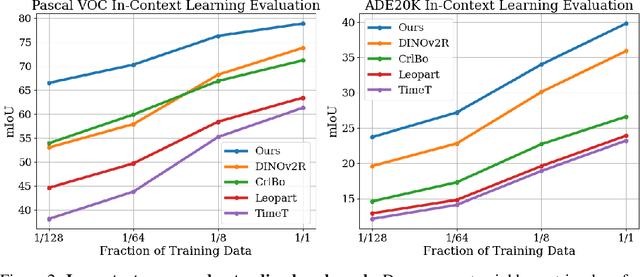
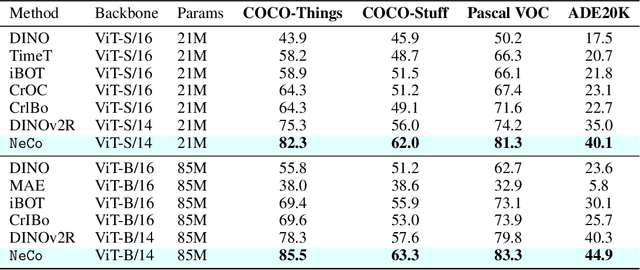
We propose sorting patch representations across views as a novel self-supervised learning signal to improve pretrained representations. To this end, we introduce NeCo: Patch Neighbor Consistency, a novel training loss that enforces patch-level nearest neighbor consistency across a student and teacher model, relative to reference batches. Our method leverages a differentiable sorting method applied on top of pretrained representations, such as DINOv2-registers to bootstrap the learning signal and further improve upon them. This dense post-pretraining leads to superior performance across various models and datasets, despite requiring only 19 hours on a single GPU. We demonstrate that this method generates high-quality dense feature encoders and establish several new state-of-the-art results: +5.5% and + 6% for non-parametric in-context semantic segmentation on ADE20k and Pascal VOC, and +7.2% and +5.7% for linear segmentation evaluations on COCO-Things and -Stuff.