 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Prompt Tuning: Vision Guided Prompt Tuning with Cross-Attention for Fine-Grained Few-Shot Learning
Dec 19, 2024



Few-shot, fine-grained classification in computer vision poses significant challenges due to the need to differentiate subtle class distinctions with limited data. This paper presents a novel method that enhances the Contrastive Language-Image Pre-Training (CLIP) model through adaptive prompt tuning, guided by real-time visual inputs. Unlike existing techniques such as Context Optimization (CoOp) and Visual Prompt Tuning (VPT), which are constrained by static prompts or visual token reliance, the proposed approach leverages a cross-attention mechanism to dynamically refine text prompts for the image at hand. This enables an image-specific alignment of textual features with image patches extracted from the Vision Transformer, making the model more effective for datasets with high intra-class variance and low inter-class differences. The method is evaluated on several datasets, including CUBirds, Oxford Flowers, and FGVC Aircraft, showing significant performance gains over static prompt tuning approaches. To ensure these performance gains translate into trustworthy predictions, we integrate Monte-Carlo Dropout in our approach to improve the reliability of the model predictions and uncertainty estimates. This integration provides valuable insights into the model's predictive confidence, helping to identify when predictions can be trusted and when additional verification is necessary. This dynamic approach offers a robust solution, advancing the state-of-the-art for few-shot fine-grained classification.
Self-Supervised Versus Supervised Training for Segmentation of Organoid Images
Nov 19, 2023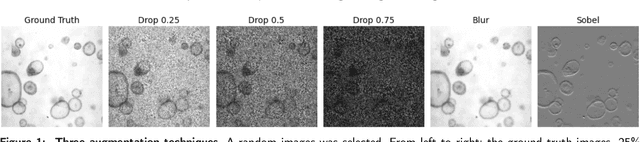

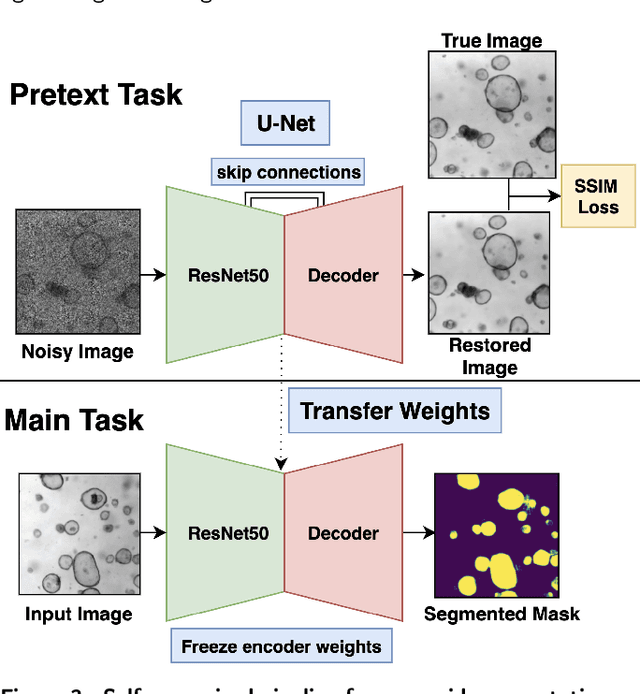
The process of annotating relevant data in the field of digital microscopy can be both time-consuming and especially expensive due to the required technical skills and human-expert knowledge. Consequently, large amounts of microscopic image data sets remain unlabeled, preventing their effective exploitation using deep-learning algorithms. In recent years it has been shown that a lot of relevant information can be drawn from unlabeled data. Self-supervised learning (SSL) is a promising solution based on learning intrinsic features under a pretext task that is similar to the main task without requiring labels. The trained result is transferred to the main task - image segmentation in our case. A ResNet50 U-Net was first trained to restore images of liver progenitor organoids from augmented images using the Structural Similarity Index Metric (SSIM), alone, and using SSIM combined with L1 loss. Both the encoder and decoder were trained in tandem. The weights were transferred to another U-Net model designed for segmentation with frozen encoder weights, using Binary Cross Entropy, Dice, and Intersection over Union (IoU) losses. For comparison, we used the same U-Net architecture to train two supervised models, one utilizing the ResNet50 encoder as well as a simple CNN. Results showed that self-supervised learning models using a 25\% pixel drop or image blurring augmentation performed better than the other augmentation techniques using the IoU loss. When trained on only 114 images for the main task, the self-supervised learning approach outperforms the supervised method achieving an F1-score of 0.85, with higher stability, in contrast to an F1=0.78 scored by the supervised method. Furthermore, when trained with larger data sets (1,000 images), self-supervised learning is still able to perform better, achieving an F1-score of 0.92, contrasting to a score of 0.85 for the supervised method.