 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPF+: Boosting adaptive-potential function reinforcement learning methods with a W-shaped network for high-dimensional games
Mar 17, 2025
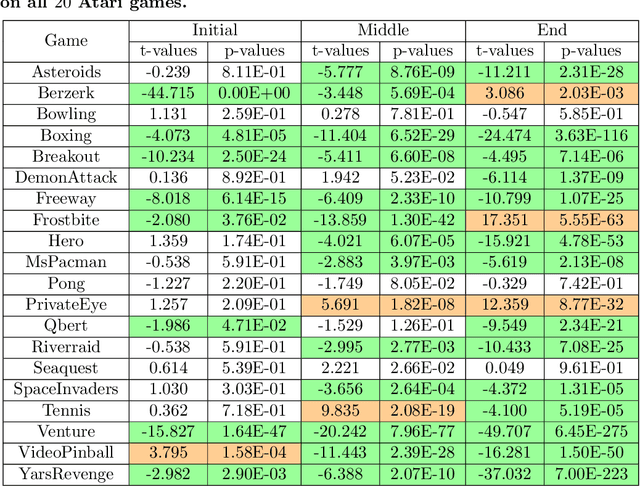
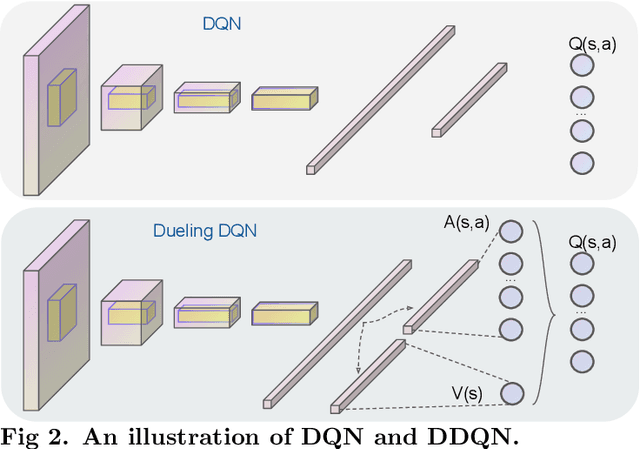
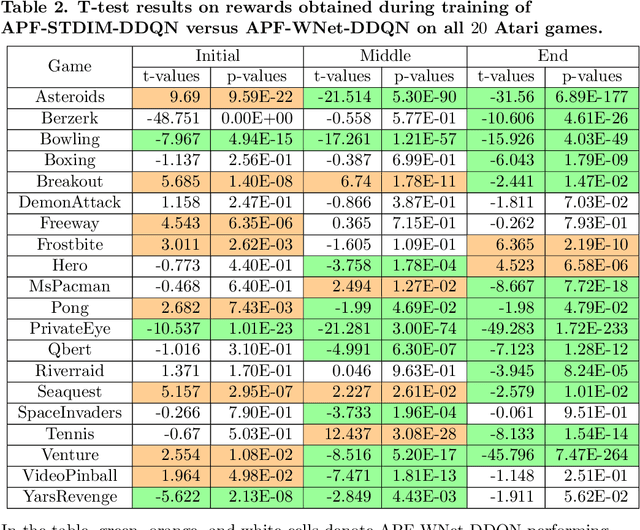
Studies in reward shaping for reinforcement learning (RL) have flourished in recent years due to its ability to speed up training. Our previous work proposed an adaptive potential function (APF) and showed that APF can accelerate the Q-learning with a Multi-layer Perceptron algorithm in the low-dimensional domain. This paper proposes to extend APF with an encoder (APF+) for RL state representation, allowing applying APF to the pixel-based Atari games using a state-encoding method that projects high-dimensional game's pixel frames to low-dimensional embeddings. We approach by designing the state-representation encoder as a W-shaped network (W-Net), by using which we are able to encode both the background as well as the moving entities in the game frames. Specifically, the embeddings derived from the pre-trained W-Net consist of two latent vectors: One represents the input state, and the other represents the deviation of the input state's representation from itself. We then incorporate W-Net into APF to train a downstream Dueling Deep Q-Network (DDQN), obtain the APF-WNet-DDQN, and demonstrate its effectiveness in Atari game-playing tasks. To evaluate the APF+W-Net module in such high-dimensional tasks, we compare with two types of baseline methods: (i) the basic DDQN; and (ii) two encoder-replaced APF-DDQN methods where we replace W-Net by (a) an unsupervised state representation method called Spatiotemporal Deep Infomax (ST-DIM) and (b) a ground truth state representation provided by the Atari Annotated RAM Interface (ARI). The experiment results show that out of 20 Atari games, APF-WNet-DDQN outperforms DDQN (14/20 games) and APF-STDIM-DDQN (13/20 games) significantly. In comparison against the APF-ARI-DDQN which employs embeddings directly of the detailed game-internal state information, the APF-WNet-DDQN achieves a comparable performance.
Boosting Reinforcement Learning Algorithms in Continuous Robotic Reaching Tasks using Adaptive Potential Functions
Feb 07, 2024In reinforcement learning, reward shaping is an efficient way to guide the learning process of an agent, as the reward can indicate the optimal policy of the task. The potential-based reward shaping framework was proposed to guarantee policy invariance after reward shaping, where a potential function is used to calculate the shaping reward. In former work, we proposed a novel adaptive potential function (APF) method to learn the potential function concurrently with training the agent based on information collected by the agent during the training process, and examined the APF method in discrete action space scenarios. This paper investigates the feasibility of using APF in solving continuous-reaching tasks in a real-world robotic scenario with continuous action space. We combine the Deep Deterministic Policy Gradient (DDPG) algorithm and our proposed method to form a new algorithm called APF-DDPG. To compare APF-DDPG with DDPG, we designed a task where the agent learns to control Baxter's right arm to reach a goal position. The experimental results show that the APF-DDPG algorithm outperforms the DDPG algorithm on both learning speed and robustness.
Self-Supervised Versus Supervised Training for Segmentation of Organoid Images
Nov 19, 2023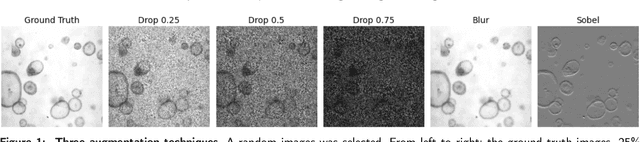

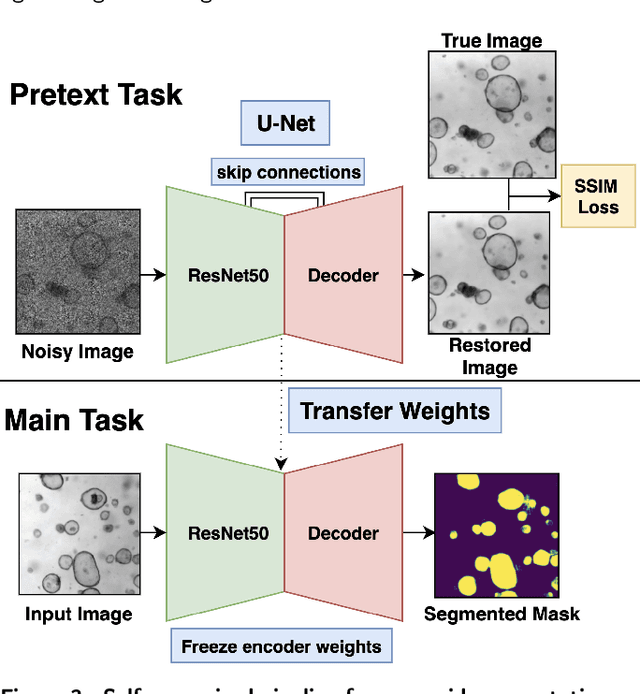
The process of annotating relevant data in the field of digital microscopy can be both time-consuming and especially expensive due to the required technical skills and human-expert knowledge. Consequently, large amounts of microscopic image data sets remain unlabeled, preventing their effective exploitation using deep-learning algorithms. In recent years it has been shown that a lot of relevant information can be drawn from unlabeled data. Self-supervised learning (SSL) is a promising solution based on learning intrinsic features under a pretext task that is similar to the main task without requiring labels. The trained result is transferred to the main task - image segmentation in our case. A ResNet50 U-Net was first trained to restore images of liver progenitor organoids from augmented images using the Structural Similarity Index Metric (SSIM), alone, and using SSIM combined with L1 loss. Both the encoder and decoder were trained in tandem. The weights were transferred to another U-Net model designed for segmentation with frozen encoder weights, using Binary Cross Entropy, Dice, and Intersection over Union (IoU) losses. For comparison, we used the same U-Net architecture to train two supervised models, one utilizing the ResNet50 encoder as well as a simple CNN. Results showed that self-supervised learning models using a 25\% pixel drop or image blurring augmentation performed better than the other augmentation techniques using the IoU loss. When trained on only 114 images for the main task, the self-supervised learning approach outperforms the supervised method achieving an F1-score of 0.85, with higher stability, in contrast to an F1=0.78 scored by the supervised method. Furthermore, when trained with larger data sets (1,000 images), self-supervised learning is still able to perform better, achieving an F1-score of 0.92, contrasting to a score of 0.85 for the supervised method.
MultiSChuBERT: Effective Multimodal Fusion for Scholarly Document Quality Prediction
Aug 15, 2023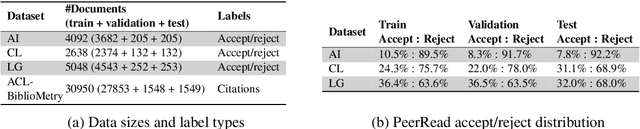


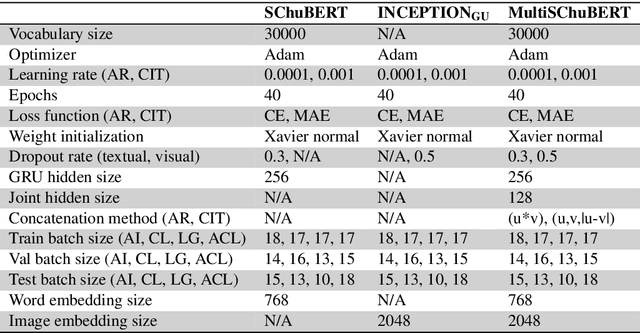
Automatic assessment of the quality of scholarly documents is a difficult task with high potential impact. Multimodality, in particular the addition of visual information next to text, has been shown to improve the performance on scholarly document quality prediction (SDQP) tasks. We propose the multimodal predictive model MultiSChuBERT. It combines a textual model based on chunking full paper text and aggregating computed BERT chunk-encodings (SChuBERT), with a visual model based on Inception V3.Our work contributes to the current state-of-the-art in SDQP in three ways. First, we show that the method of combining visual and textual embeddings can substantially influence the results. Second, we demonstrate that gradual-unfreezing of the weights of the visual sub-model, reduces its tendency to ovefit the data, improving results. Third, we show the retained benefit of multimodality when replacing standard BERT$_{\textrm{BASE}}$ embeddings with more recent state-of-the-art text embedding models. Using BERT$_{\textrm{BASE}}$ embeddings, on the (log) number of citations prediction task with the ACL-BiblioMetry dataset, our MultiSChuBERT (text+visual) model obtains an $R^{2}$ score of 0.454 compared to 0.432 for the SChuBERT (text only) model. Similar improvements are obtained on the PeerRead accept/reject prediction task. In our experiments using SciBERT, scincl, SPECTER and SPECTER2.0 embeddings, we show that each of these tailored embeddings adds further improvements over the standard BERT$_{\textrm{BASE}}$ embeddings, with the SPECTER2.0 embeddings performing best.
Writer adaptation for offline text recognition: An exploration of neural network-based methods
Jul 11, 2023



Handwriting recognition has seen significant success with the use of deep learning. However, a persistent shortcoming of neural networks is that they are not well-equipped to deal with shifting data distributions. In the field of handwritten text recognition (HTR), this shows itself in poor recognition accuracy for writers that are not similar to those seen during training. An ideal HTR model should be adaptive to new writing styles in order to handle the vast amount of possible writing styles. In this paper, we explore how HTR models can be made writer adaptive by using only a handful of examples from a new writer (e.g., 16 examples) for adaptation. Two HTR architectures are used as base models, using a ResNet backbone along with either an LSTM or Transformer sequence decoder. Using these base models, two methods are considered to make them writer adaptive: 1) model-agnostic meta-learning (MAML), an algorithm commonly used for tasks such as few-shot classification, and 2) writer codes, an idea originating from automatic speech recognition. Results show that an HTR-specific version of MAML known as MetaHTR improves performance compared to the baseline with a 1.4 to 2.0 improvement in word error rate (WER). The improvement due to writer adaptation is between 0.2 and 0.7 WER, where a deeper model seems to lend itself better to adaptation using MetaHTR than a shallower model. However, applying MetaHTR to larger HTR models or sentence-level HTR may become prohibitive due to its high computational and memory requirements. Lastly, writer codes based on learned features or Hinge statistical features did not lead to improved recognition performance.
Reinforcement Learning in Robotic Motion Planning by Combined Experience-based Planning and Self-Imitation Learning
Jun 11, 2023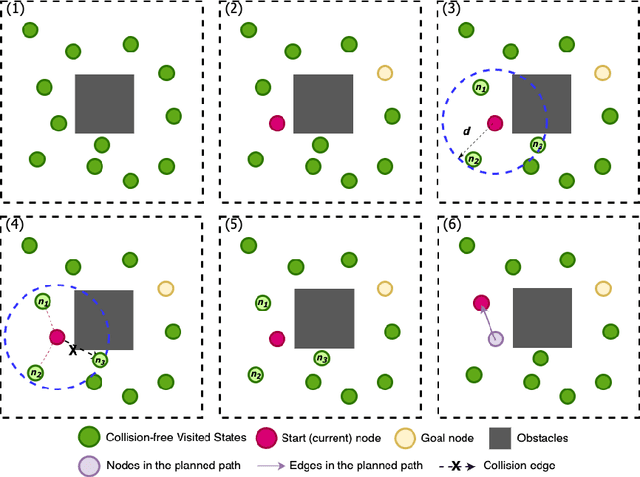

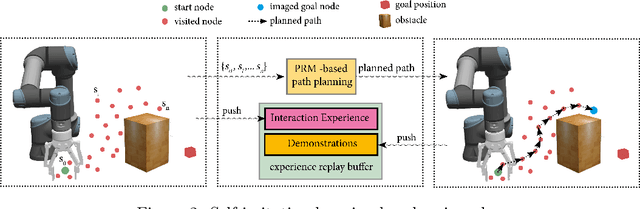

High-quality and representative data is essential for both Imitation Learning (IL)- and Reinforcement Learning (RL)-based motion planning tasks. For real robots, it is challenging to collect enough qualified data either as demonstrations for IL or experiences for RL due to safety considerations in environments with obstacles. We target this challenge by proposing the self-imitation learning by planning plus (SILP+) algorithm, which efficiently embeds experience-based planning into the learning architecture to mitigate the data-collection problem. The planner generates demonstrations based on successfully visited states from the current RL policy, and the policy improves by learning from these demonstrations. In this way, we relieve the demand for human expert operators to collect demonstrations required by IL and improve the RL performance as well. Various experimental results show that SILP+ achieves better training efficiency higher and more stable success rate in complex motion planning tasks compared to several other methods. Extensive tests on physical robots illustrate the effectiveness of SILP+ in a physical setting.
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023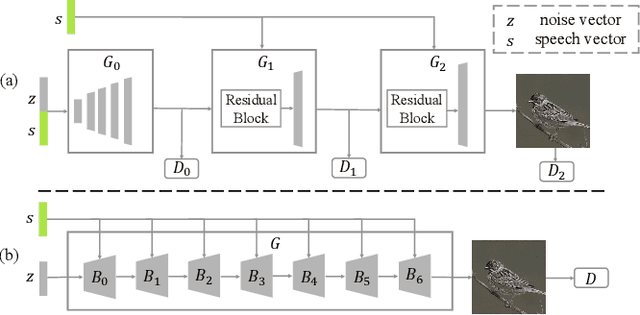
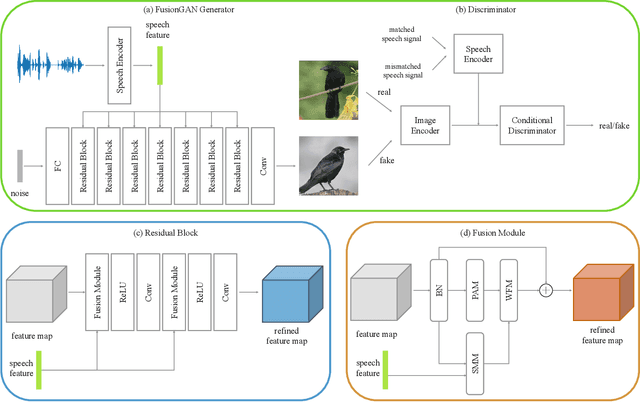
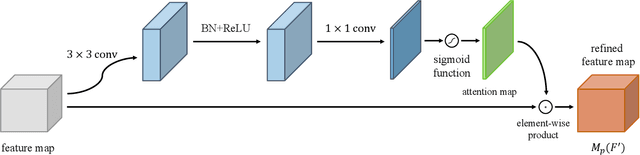
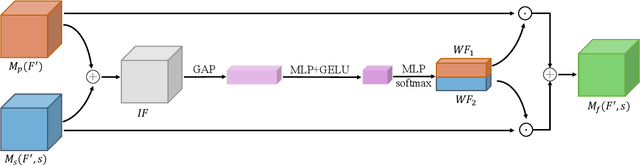
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.
The Effects of Character-Level Data Augmentation on Style-Based Dating of Historical Manuscripts
Dec 15, 2022Identifying the production dates of historical manuscripts is one of the main goals for paleographers when studying ancient documents. Automatized methods can provide paleographers with objective tools to estimate dates more accurately. Previously, statistical features have been used to date digitized historical manuscripts based on the hypothesis that handwriting styles change over periods. However, the sparse availability of such documents poses a challenge in obtaining robust systems. Hence, the research of this article explores the influence of data augmentation on the dating of historical manuscripts. Linear Support Vector Machines were trained with k-fold cross-validation on textural and grapheme-based features extracted from historical manuscripts of different collections, including the Medieval Paleographical Scale, early Aramaic manuscripts, and the Dead Sea Scrolls. Results show that training models with augmented data improve the performance of historical manuscripts dating by 1% - 3% in cumulative scores. Additionally, this indicates further enhancement possibilities by considering models specific to the features and the documents' scripts.
Optimized latent-code selection for explainable conditional text-to-image GANs
Apr 27, 2022
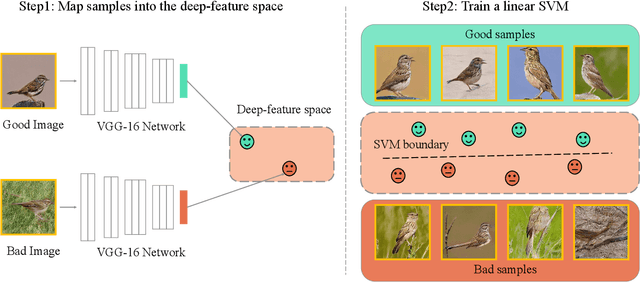


The task of text-to-image generation has achieved remarkable progress due to the advances in the conditional generative adversarial networks (GANs). However, existing conditional text-to-image GANs approaches mostly concentrate on improving both image quality and semantic relevance but ignore the explainability of the model which plays a vital role in real-world applications. In this paper, we present a variety of techniques to take a deep look into the latent space and semantic space of the conditional text-to-image GANs model. We introduce pairwise linear interpolation of latent codes and `linguistic' linear interpolation to study what the model has learned within the latent space and `linguistic' embeddings. Subsequently, we extend linear interpolation to triangular interpolation conditioned on three corners to further analyze the model. After that, we build a Good/Bad data set containing unsuccessfully and successfully synthetic samples and corresponding latent codes for the image-quality research. Based on this data set, we propose a framework for finding good latent codes by utilizing a linear SVM. Experimental results on the recent DiverGAN generator trained on two benchmark data sets qualitatively prove the effectiveness of our presented techniques, with a better than 94\% accuracy in predicting ${Good}$/${Bad}$ classes for latent vectors. The Good/Bad data set is publicly available at https://zenodo.org/record/5850224#.YeGMwP7MKUk.
Image-based material analysis of ancient historical documents
Mar 02, 2022



Researchers continually perform corroborative tests to classify ancient historical documents based on the physical materials of their writing surfaces. However, these tests, often performed on-site, requires actual access to the manuscript objects. The procedures involve a considerable amount of time and cost, and can damage the manuscripts. Developing a technique to classify such documents using only digital images can be very useful and efficient. In order to tackle this problem, this study uses images of a famous historical collection, the Dead Sea Scrolls, to propose a novel method to classify the materials of the manuscripts. The proposed classifier uses the two-dimensional Fourier Transform to identify patterns within the manuscript surfaces. Combining a binary classification system employing the transform with a majority voting process is shown to be effective for this classification task. This pilot study shows a successful classification percentage of up to 97% for a confined amount of manuscripts produced from either parchment or papyrus material. Feature vectors based on Fourier-space grid representation outperformed a concentric Fourier-space format.