 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Diversification of Multi-Carousel Book Recommendation
Nov 18, 2025Using multiple carousels, lists that wrap around and can be scrolled, is the basis for offering content in most contemporary movie streaming platforms. Carousels allow for highlighting different aspects of users' taste, that fall in categories such as genres and authors. However, while carousels offer structure and greater ease of navigation, they alone do not increase diversity in recommendations, while this is essential to keep users engaged. In this work we propose several approaches to effectively increase item diversity within the domain of book recommendations, on top of a collaborative filtering algorithm. These approaches are intended to improve book recommendations in the web catalogs of public libraries. Furthermore, we introduce metrics to evaluate the resulting strategies, and show that the proposed system finds a suitable balance between accuracy and beyond-accuracy aspects.
MultiSChuBERT: Effective Multimodal Fusion for Scholarly Document Quality Prediction
Aug 15, 2023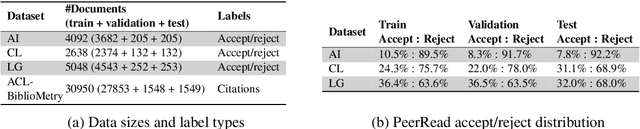


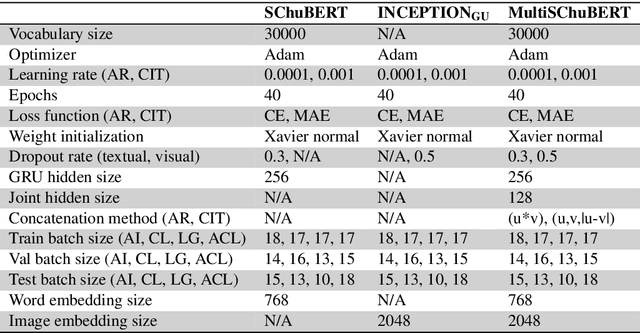
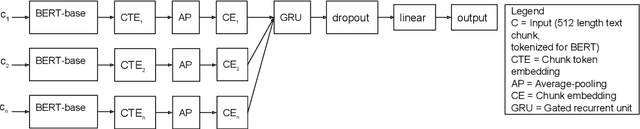
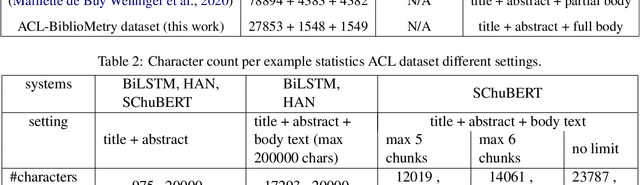
Automatic assessment of the quality of scholarly documents is a difficult task with high potential impact. Multimodality, in particular the addition of visual information next to text, has been shown to improve the performance on scholarly document quality prediction (SDQP) tasks. We propose the multimodal predictive model MultiSChuBERT. It combines a textual model based on chunking full paper text and aggregating computed BERT chunk-encodings (SChuBERT), with a visual model based on Inception V3.Our work contributes to the current state-of-the-art in SDQP in three ways. First, we show that the method of combining visual and textual embeddings can substantially influence the results. Second, we demonstrate that gradual-unfreezing of the weights of the visual sub-model, reduces its tendency to ovefit the data, improving results. Third, we show the retained benefit of multimodality when replacing standard BERT$_{\textrm{BASE}}$ embeddings with more recent state-of-the-art text embedding models. Using BERT$_{\textrm{BASE}}$ embeddings, on the (log) number of citations prediction task with the ACL-BiblioMetry dataset, our MultiSChuBERT (text+visual) model obtains an $R^{2}$ score of 0.454 compared to 0.432 for the SChuBERT (text only) model. Similar improvements are obtained on the PeerRead accept/reject prediction task. In our experiments using SciBERT, scincl, SPECTER and SPECTER2.0 embeddings, we show that each of these tailored embeddings adds further improvements over the standard BERT$_{\textrm{BASE}}$ embeddings, with the SPECTER2.0 embeddings performing best.
Active learning for reducing labeling effort in text classification tasks
Sep 10, 2021
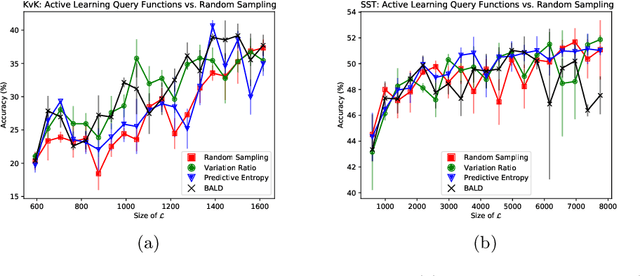

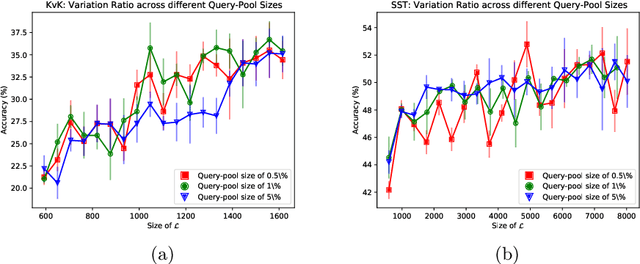
Labeling data can be an expensive task as it is usually performed manually by domain experts. This is cumbersome for deep learning, as it is dependent on large labeled datasets. Active learning (AL) is a paradigm that aims to reduce labeling effort by only using the data which the used model deems most informative. Little research has been done on AL in a text classification setting and next to none has involved the more recent, state-of-the-art NLP models. Here, we present an empirical study that compares different uncertainty-based algorithms with BERT$_{base}$ as the used classifier. We evaluate the algorithms on two NLP classification datasets: Stanford Sentiment Treebank and KvK-Frontpages. Additionally, we explore heuristics that aim to solve presupposed problems of uncertainty-based AL; namely, that it is unscalable and that it is prone to selecting outliers. Furthermore, we explore the influence of the query-pool size on the performance of AL. Whereas it was found that the proposed heuristics for AL did not improve performance of AL; our results show that using uncertainty-based AL with BERT$_{base}$ outperforms random sampling of data. This difference in performance can decrease as the query-pool size gets larger.
SChuBERT: Scholarly Document Chunks with BERT-encoding boost Citation Count Prediction
Dec 21, 2020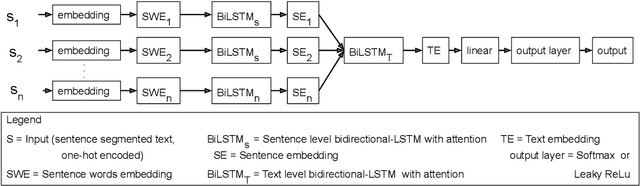
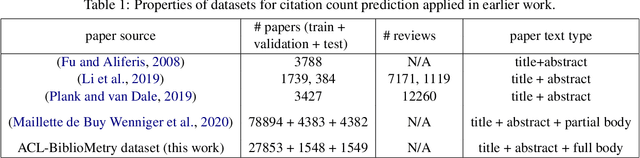
Predicting the number of citations of scholarly documents is an upcoming task in scholarly document processing. Besides the intrinsic merit of this information, it also has a wider use as an imperfect proxy for quality which has the advantage of being cheaply available for large volumes of scholarly documents. Previous work has dealt with number of citations prediction with relatively small training data sets, or larger datasets but with short, incomplete input text. In this work we leverage the open access ACL Anthology collection in combination with the Semantic Scholar bibliometric database to create a large corpus of scholarly documents with associated citation information and we propose a new citation prediction model called SChuBERT. In our experiments we compare SChuBERT with several state-of-the-art citation prediction models and show that it outperforms previous methods by a large margin. We also show the merit of using more training data and longer input for number of citations prediction.
* Published at the First Workshop on Scholarly Document Processing, at EMNLP 2020. Minor corrections were made to the workshop version, including addition of color to Figures 1,2
Structure-Tags Improve Text Classification for Scholarly Document Quality Prediction
Apr 30, 2020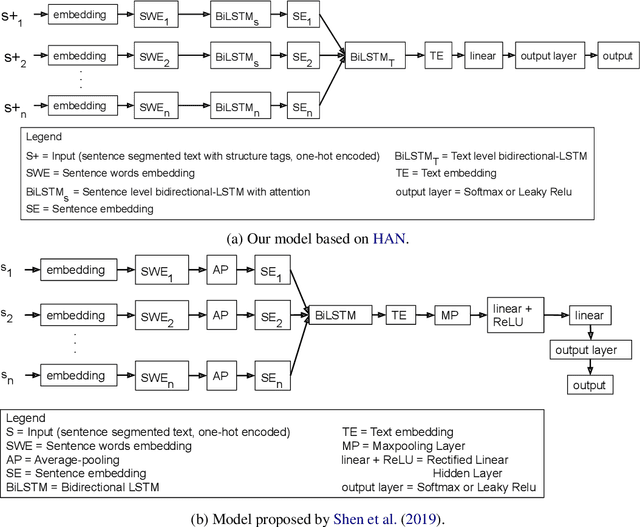



Training recurrent neural networks on long texts, in particular scholarly documents, causes problems for learning. While hierarchical attention networks (HANs) are effective in solving these problems, they still lose important information about the structure of the text. To tackle these problems, we propose the use of HANs combined with structure-tags which mark the role of sentences in the document. Adding tags to sentences, marking them as corresponding to title, abstract or main body text, yields improvements over the state-of-the-art for scholarly document quality prediction: substantial gains on average against other models and consistent improvements over HANs without structure-tags. The proposed system is applied to the task of accept/reject prediction on the PeerRead dataset and compared against a recent BiLSTM-based model and joint textual+visual model. It gains 4.7% accuracy over the best of both models on the computation and language domain and loses 2.4% against the best of both on the machine learning domain. Compared to plain HANs, accuracy increases on both domains, with 1.5% and 2% respectively. We also obtain improvements when introducing the tags for prediction of the number of citations for 88k scientific publications that we compiled from the Allen AI S2ORC dataset. For our HAN-system with structure-tags we reach 28.5% explained variance, an improvement of 1.0% over HANs without structure-tags.
Transductive Data-Selection Algorithms for Fine-Tuning Neural Machine Translation
Oct 08, 2019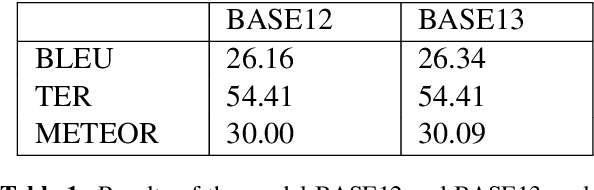
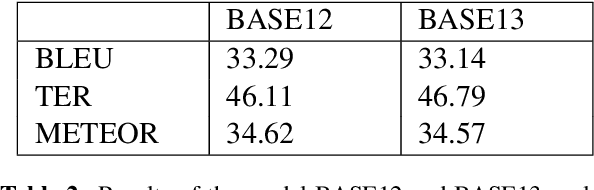
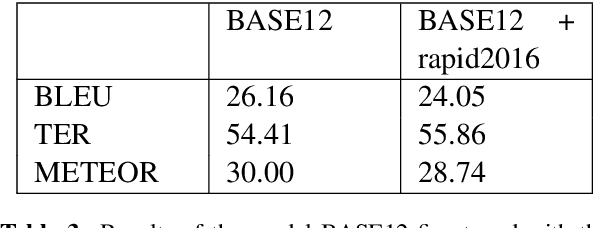
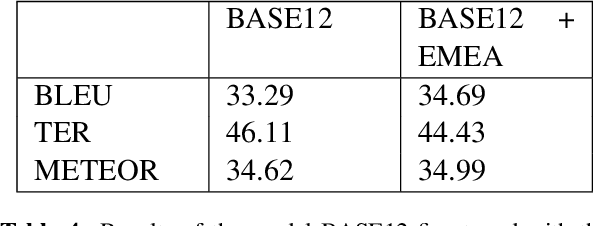
Machine Translation models are trained to translate a variety of documents from one language into another. However, models specifically trained for a particular characteristics of the documents tend to perform better. Fine-tuning is a technique for adapting an NMT model to some domain. In this work, we want to use this technique to adapt the model to a given test set. In particular, we are using transductive data selection algorithms which take advantage the information of the test set to retrieve sentences from a larger parallel set. In cases where the model is available at translation time (when the test set is provided), it can be adapted with a small subset of data, thereby achieving better performance than a generic model or a domain-adapted model.
* Proceedings of The 8th Workshop on Patent and Scientific Literature Translation, 2019, pages 13--23, Dublin
Combining SMT and NMT Back-Translated Data for Efficient NMT
Sep 09, 2019



Neural Machine Translation (NMT) models achieve their best performance when large sets of parallel data are used for training. Consequently, techniques for augmenting the training set have become popular recently. One of these methods is back-translation (Sennrich et al., 2016), which consists on generating synthetic sentences by translating a set of monolingual, target-language sentences using a Machine Translation (MT) model. Generally, NMT models are used for back-translation. In this work, we analyze the performance of models when the training data is extended with synthetic data using different MT approaches. In particular we investigate back-translated data generated not only by NMT but also by Statistical Machine Translation (SMT) models and combinations of both. The results reveal that the models achieve the best performances when the training set is augmented with back-translated data created by merging different MT approaches.
Adaptation of Machine Translation Models with Back-translated Data using Transductive Data Selection Methods
Jun 18, 2019

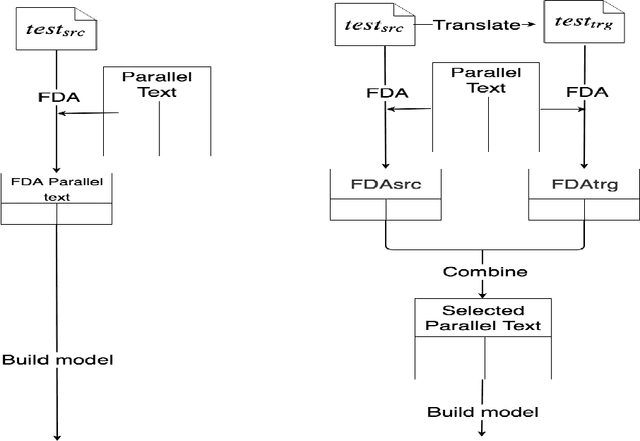

Data selection has proven its merit for improving Neural Machine Translation (NMT), when applied to authentic data. But the benefit of using synthetic data in NMT training, produced by the popular back-translation technique, raises the question if data selection could also be useful for synthetic data? In this work we use Infrequent N-gram Recovery (INR) and Feature Decay Algorithms (FDA), two transductive data selection methods to obtain subsets of sentences from synthetic data. These methods ensure that selected sentences share n-grams with the test set so the NMT model can be adapted to translate it. Performing data selection on back-translated data creates new challenges as the source-side may contain noise originated by the model used in the back-translation. Hence, finding n-grams present in the test set become more difficult. Despite that, in our work we show that adapting a model with a selection of synthetic data is an useful approach.
No Padding Please: Efficient Neural Handwriting Recognition
Feb 28, 2019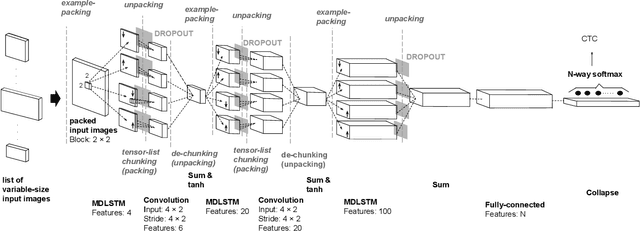
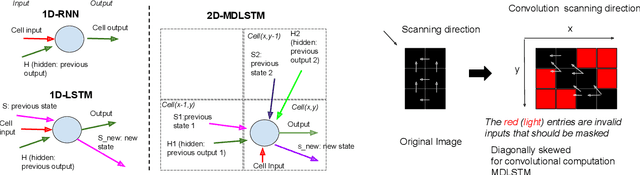
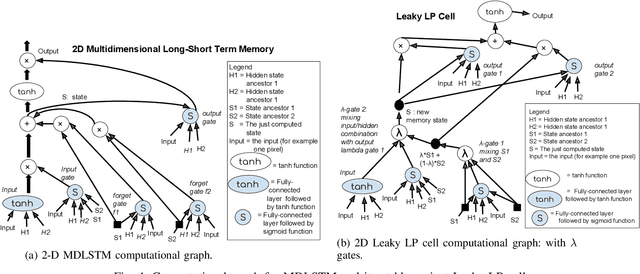
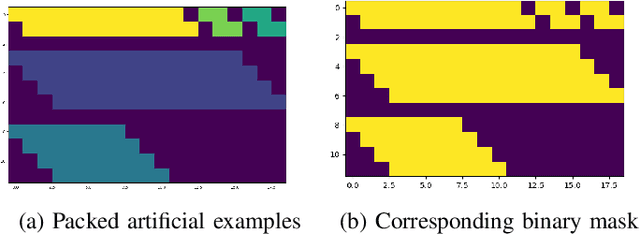
Neural handwriting recognition (NHR) is the recognition of handwritten text with deep learning models, such as multi-dimensional long short-term memory (MDLSTM) recurrent neural networks. Models with MDLSTM layers have achieved state-of-the art results on handwritten text recognition tasks. While multi-directional MDLSTM-layers have an unbeaten ability to capture the complete context in all directions, this strength limits the possibilities for parallelization, and therefore comes at a high computational cost. In this work we develop methods to create efficient MDLSTM-based models for NHR, particularly a method aimed at eliminating computation waste that results from padding. This proposed method, called example-packing, replaces wasteful stacking of padded examples with efficient tiling in a 2-dimensional grid. For word-based NHR this yields a speed improvement of factor 6.6 over an already efficient baseline of minimal padding for each batch separately. For line-based NHR the savings are more modest, but still significant. In addition to example-packing, we propose: 1) a technique to optimize parallelization for dynamic graph definition frameworks including PyTorch, using convolutions with grouping, 2) a method for parallelization across GPUs for variable-length example batches. All our techniques are thoroughly tested on our own PyTorch re-implementation of MDLSTM-based NHR models. A thorough evaluation on the IAM dataset shows that our models are performing similar to earlier implementations of state-of-the-art models. Our efficient NHR model and some of the reusable techniques discussed with it offer ways to realize relatively efficient models for the omnipresent scenario of variable-length inputs in deep learning.
Data Selection with Feature Decay Algorithms Using an Approximated Target Side
Nov 07, 2018
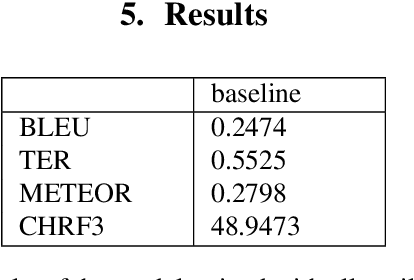
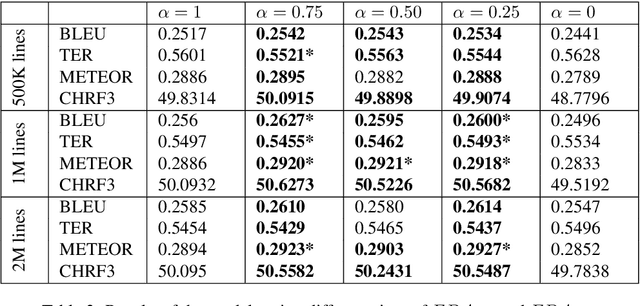
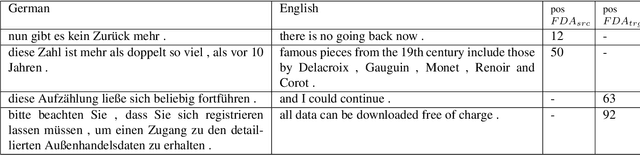
Data selection techniques applied to neural machine translation (NMT) aim to increase the performance of a model by retrieving a subset of sentences for use as training data. One of the possible data selection techniques are transductive learning methods, which select the data based on the test set, i.e. the document to be translated. A limitation of these methods to date is that using the source-side test set does not by itself guarantee that sentences are selected with correct translations, or translations that are suitable given the test-set domain. Some corpora, such as subtitle corpora, may contain parallel sentences with inaccurate translations caused by localization or length restrictions. In order to try to fix this problem, in this paper we propose to use an approximated target-side in addition to the source-side when selecting suitable sentence-pairs for training a model. This approximated target-side is built by pre-translating the source-side. In this work, we explore the performance of this general idea for one specific data selection approach called Feature Decay Algorithms (FDA). We train German-English NMT models on data selected by using the test set (source), the approximated target side, and a mixture of both. Our findings reveal that models built using a combination of outputs of FDA (using the test set and an approximated target side) perform better than those solely using the test set. We obtain a statistically significant improvement of more than 1.5 BLEU points over a model trained with all data, and more than 0.5 BLEU points over a strong FDA baseline that uses source-side information only.