 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Padding Please: Efficient Neural Handwriting Recognition
Paper and Code
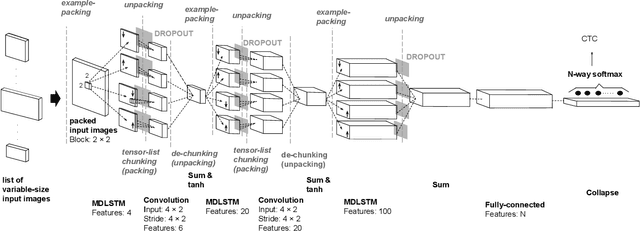
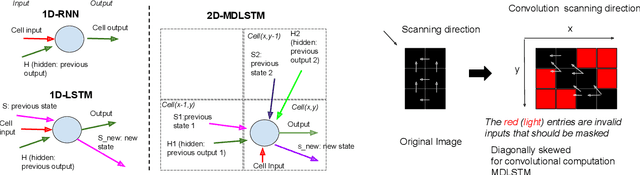
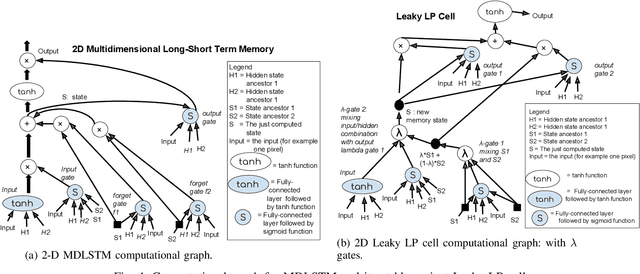
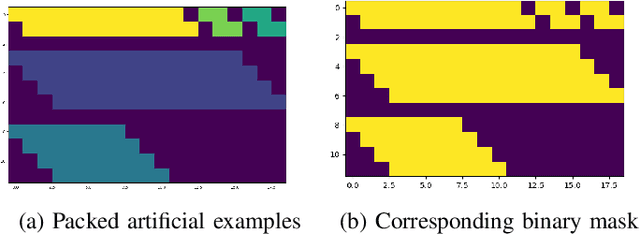
Neural handwriting recognition (NHR) is the recognition of handwritten text with deep learning models, such as multi-dimensional long short-term memory (MDLSTM) recurrent neural networks. Models with MDLSTM layers have achieved state-of-the art results on handwritten text recognition tasks. While multi-directional MDLSTM-layers have an unbeaten ability to capture the complete context in all directions, this strength limits the possibilities for parallelization, and therefore comes at a high computational cost. In this work we develop methods to create efficient MDLSTM-based models for NHR, particularly a method aimed at eliminating computation waste that results from padding. This proposed method, called example-packing, replaces wasteful stacking of padded examples with efficient tiling in a 2-dimensional grid. For word-based NHR this yields a speed improvement of factor 6.6 over an already efficient baseline of minimal padding for each batch separately. For line-based NHR the savings are more modest, but still significant. In addition to example-packing, we propose: 1) a technique to optimize parallelization for dynamic graph definition frameworks including PyTorch, using convolutions with grouping, 2) a method for parallelization across GPUs for variable-length example batches. All our techniques are thoroughly tested on our own PyTorch re-implementation of MDLSTM-based NHR models. A thorough evaluation on the IAM dataset shows that our models are performing similar to earlier implementations of state-of-the-art models. Our efficient NHR model and some of the reusable techniques discussed with it offer ways to realize relatively efficient models for the omnipresent scenario of variable-length inputs in deep learning.